









 本文介绍如何使用Scrapy和Selenium结合爬取某些无法直接抓取的网页内容。针对特定网站的反爬措施,通过Selenium模拟浏览器行为,解决爬虫获取数据不完整的问题。
本文介绍如何使用Scrapy和Selenium结合爬取某些无法直接抓取的网页内容。针对特定网站的反爬措施,通过Selenium模拟浏览器行为,解决爬虫获取数据不完整的问题。
scrapy Middleware 和 selenium 结合
scrapy框架的结构图和顺序图
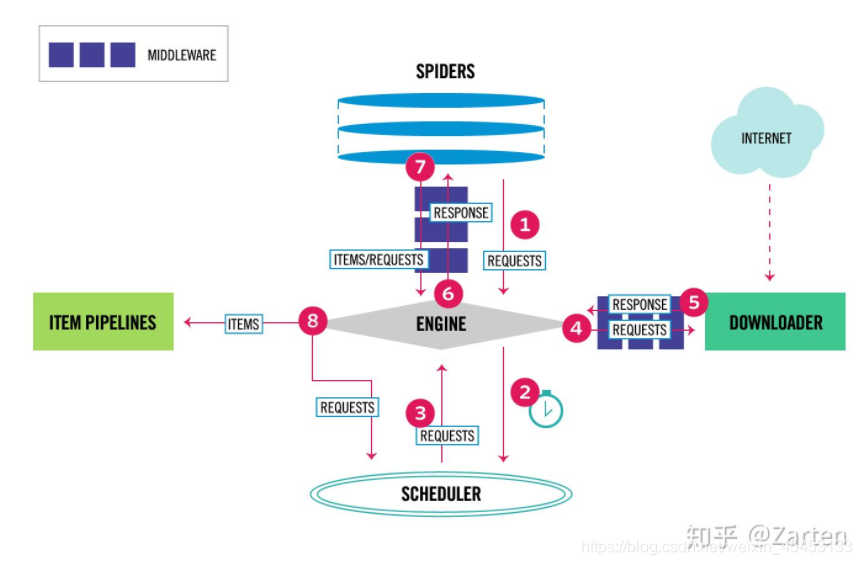

middleware结合selenium
-
问题描述:某些网页无法正常通过爬虫去爬取或者仅仅通过爬虫获取到的网页中信息不全,这时需要用selenium模拟浏览器返回最终渲染后的页面。
-
遇到的困难:在新创建了一个
ChromeDownloaderMiddleware,但是最终并没有完成预期(返回浏览器渲染之后的页面,然后进行爬取),download在下载过程中遇到403,之后爬虫就结束了。
代码
# 如果下载器返回的html中的纯文本不足二百个字符,那就启动selenium得到渲染之后的页面
class ChromeDownloaderMiddleware:
def __init__(self):
print('Chrome driver begin...')
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 设置无界面
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2,
"profile.managed_default_content_settings.flash": 0})
self.webdriver = webdriver.Chrome(executable_path=r'E:\python配置文件\chromedriver', options=options)
def __del__(self):
self.webdriver.close()
# 这个处理响应到底在程序运行过程中的哪一步?
def process_response(self, response, requset,spider):
print('Chrome driver begin...')
try:
print('Chrome driver begin...')
pure_text = BeautifulSoup(response.body).get_text()
if pure_text.len < 200:
# self.webdriver.get(url=response.url)
# wait = WebDriverWait(self.webdriver, timeout=20)
return HtmlResponse(url=response.url, body=self.webdriver.page_source, encoding='utf-8',
) # 返回selenium渲染之后的HTML数据
else:
return response
except TimeoutException:
return HtmlResponse(url=response.url, encoding='utf-8', status=500)
finally:
print('Chrome driver end...')
程序log

解决方案
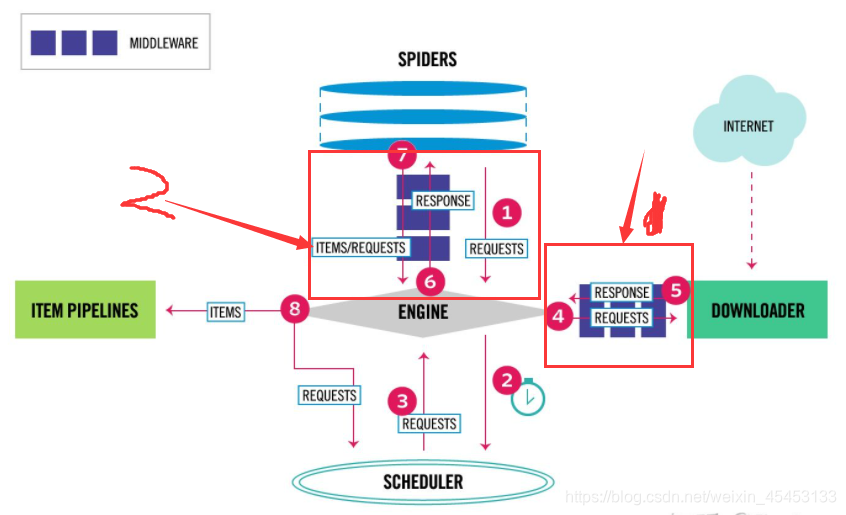
分析scrapy框架在运行过程中的整个流程
详见文章最初的框架图和官网的解释。
分析middleware种类
-
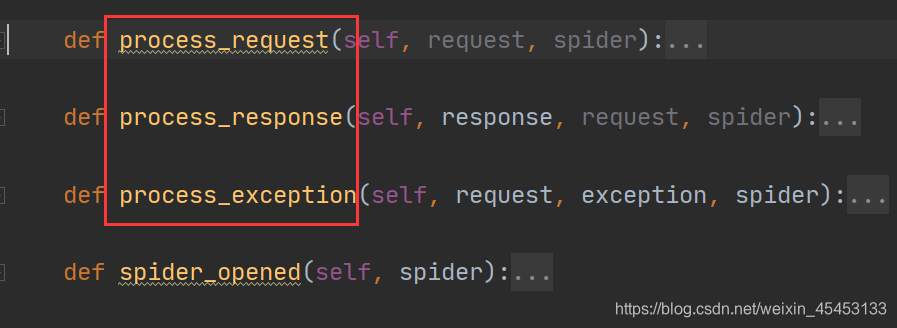
Spider middleware
spider中间件是一个与Scrapy的spider处理机制挂钩的框架,在这个框架中,可以插入自定义功能来处理发送给spider进行处理的响应,以及处理从spider生成的请求和项目。
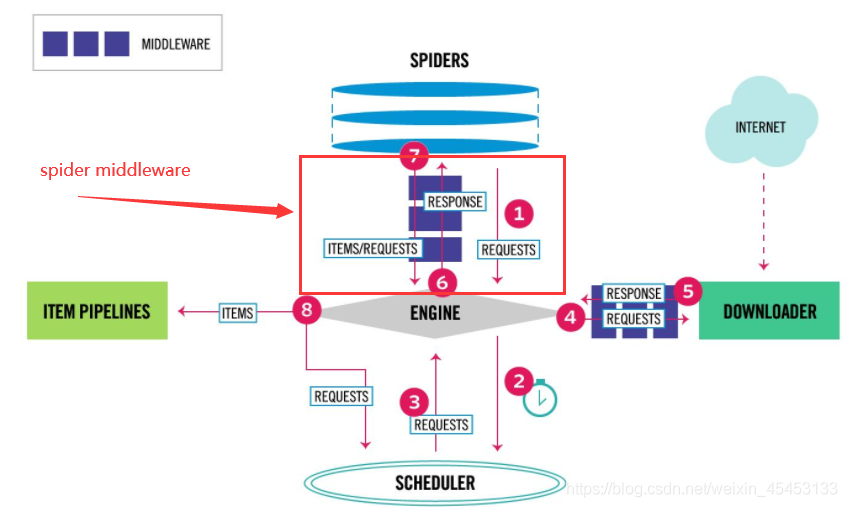
其实看代码也能看出其作用的位置:
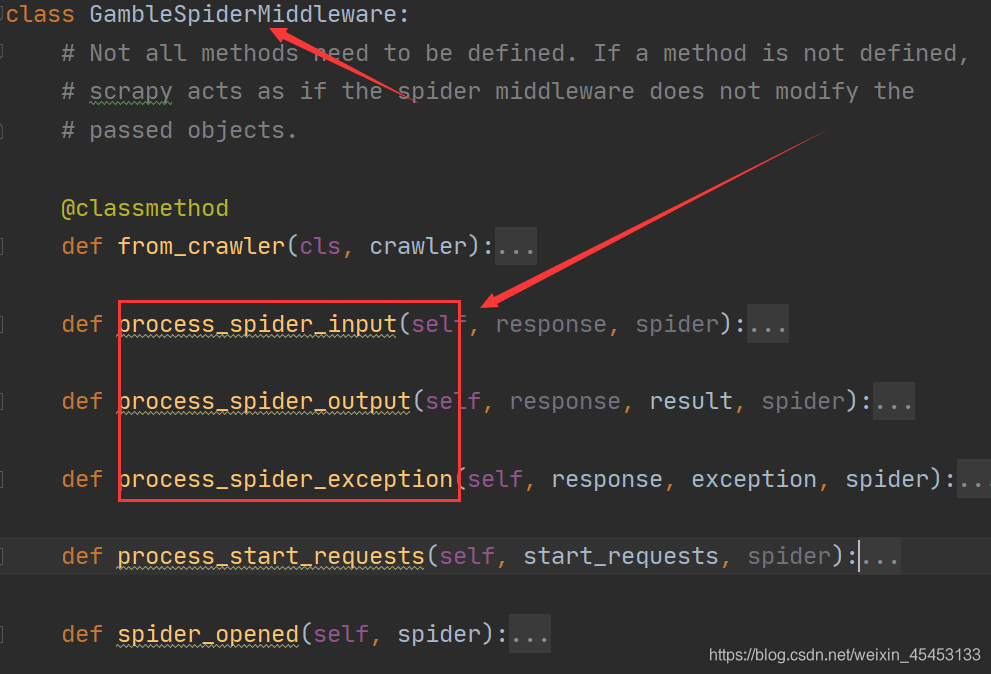
-
Downloader Middleware
下载器中间件是介于Scrapy的request/response处理的钩子框架。 是用于全局修改Scrapy request和response的一个轻量、底层的系统。
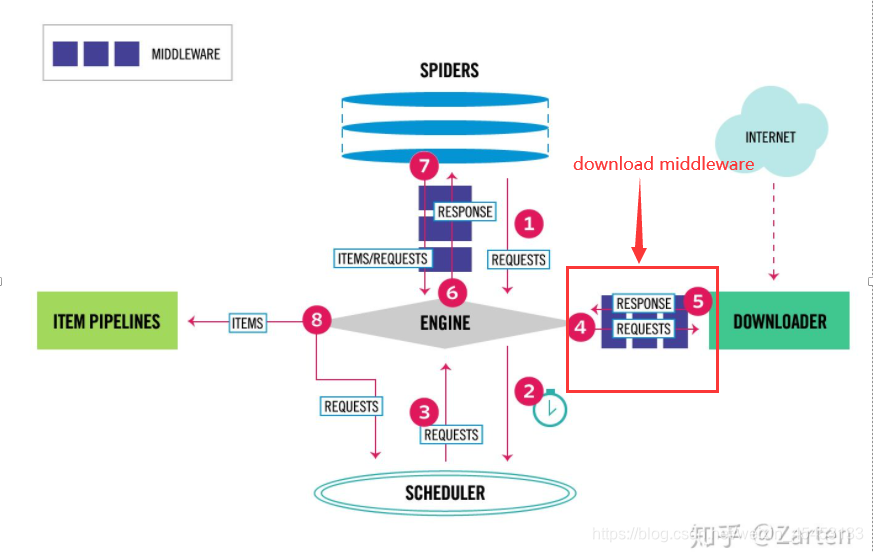
看代码也能看出作用的位置:
分析自己的代码
理论原因:没有搞清楚spider中间件和download中间件作用的位置。错误的将ChromeDownloaderMiddleware放在了spider中间件的位置上。

流程原因:
- 在1过程中,由于网页的限制措施,download相当于并没有爬取到相应的response,这也是为什么日志中出现了
2021-04-10 11:02:20 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 https://www.XXXX.com/home/>: HTTP status code is not handled or not allowed。 - 既然1过程都没有返回response给引擎,那引擎自然也不会给spider相应的response。因此,在2过程中部署的
ChromeDownloaderMiddleware也就不会发挥作用。与程序展现出来的效果一致。
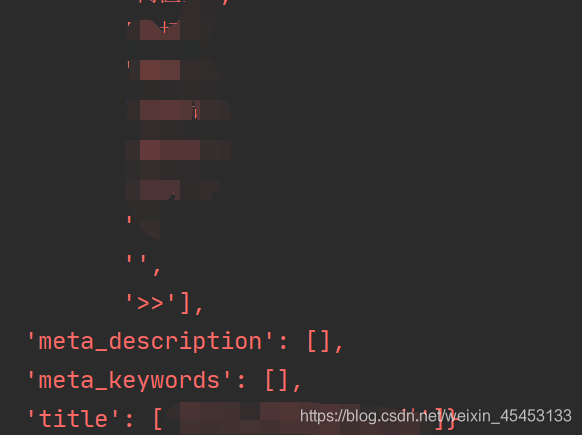
代码修改
直接将ChromeDownloaderMiddleware放到DOWNLOADER_MIDDLEWARES中,在setting.py中打开即可。成功爬到数据。

















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









