






一、遍历字典
operators_dict={'<': 'less than','==': 'equal'}
print("Here is the original dict:")
for i in sorted(operators_dict):
print("Operator {} means {}.".format(i,operators_dict[i]))
operators_dict[">"]="greater than" #字典增加新元素
print() #输出空行
print("The dict was changed to:")
for i in sorted(operators_dict):
print("Operator {} means {}.".format(i,operators_dict[i]))在 Python 中,当你使用 for i in sorted(operators_dict): 这样的循环时,i 是在每次迭代中从 sorted(operators_dict) 得到的当前元素的引用(在这种情况下,它是字典的键)因此输出时operators_dict[i] ,i不加引号。
此外,
#输出空行
print("") #传入一个空字符串
print(" ") #严格来说,它并不是完全意义上的“空行”。它实际上输出了一个空格字符,但是由于这个字符是不可见的,所以看起来像是一个空行。并且本体中用到sorted()函数,此函数不会改变原本的字典,但如果使用dict.sort()编写,那么字典本身就是经过默认升序的新字典。
参考:sort与sorted的区别_sort和sorted函数的区别-优快云博客
二、毕业生就业调查
survey_list=['Niumei','Niu Ke Le','GURR','LOLO']
result_dict={'Niumei': 'Nowcoder','GURR': 'HUAWEI'}
for i in survey_list:
if i in result_dict:
print('Hi, {}! Thank you for participating in our graduation survey!'.format(i))
else:
print('Hi, {}! Could you take part in our graduation survey?'.format(i))三、姓名与学号
my_dict_1={'name': 'Niuniu','Student ID': 1}
my_dict_2={'name': 'Niumei','Student ID': 2}
my_dict_3={'name': 'Niu Ke Le','Student ID': 3}
dict_list=[]
dict_list.append(my_dict_1)
dict_list.append(my_dict_2)
dict_list.append(my_dict_3)
for dict_item in dict_list:
name=dict_item["name"]
id=dict_item["Student ID"]
print(f"{name}'s student id is {id}.")这里要求把多个字典添加到dict_list列表中 ,使得dict_list[0]={'name': 'Niuniu', 'Student ID': 1},相当于列表中的一个元素是字典,那么需要从字典里拆解信息,这里的dict_item就是我们循环时的i,即表示第i个字典名,类似dict_list={'name': 'Niuniu', 'Student ID': 1},再通过字典查询并赋值,最后通过f-string输出,这样的输出方式比format要好一些。
四、首都
cities_dict = {
'Beijing': {'Capital': 'China'},
'Moscow': {'Capital': 'Russia'},
'Paris': {'Capital': 'France'} #这里的Capital为字符型,应加引号
}
for city, country in sorted(cities_dict.items()):
print(f'{city} is the capital of {country["Capital"]}!') 调用 cities_dict.items() 会返回一个迭代器,该迭代器会生成以下元组:
(('Beijing', {'Capital': 'China'}),
('Moscow', {'Capital': 'Russia'}),
('Paris', {'Capital': 'France'}))然后在进行排序(按照字母序(A-Z)排列)
如果直接使用sorted(cities_dict)进行排序,那么默认情况下它会返回字典键的排序列表,因为字典在迭代时会默认只提供键,即排序好的['Beijing', 'Moscow', 'Paris'],而失去了关于'Capital'的信息,而这些信息是题目要求的。
对于for循环输出:
for city, country in sorted(cities_dict.items()):
print(f'{city} is the capital of {country["Capital"]}!')在这里,sorted(cities_dict.items()) 会返回一个已按城市名排序的元组列表,然后for循环会遍历这个列表,并将每个元组的第一个元素赋值给 city 变量,第二个元素赋值给 country 变量,这里的country={'Capital': 'China'},因此在输出时用country['Captital']来得到China。
或者还有一种方法
cities_dict = {'Beijing': {'Capital': 'China'},'Moscow': {'Capital': 'Russia'},'Paris': {'Capital': 'France'}}
for i in sorted(cities_dict):
print('%s is the capital of %s!'%(i,cities_dict[i]['Capital']))在这里,使用sorted(cities_dict)会将字典中的键值升序排列,即,返回['Beijing', 'Moscow', 'Paris'],评论区有人写sorted(cities_dict.keys()),这两得到的效果是相同的,都是不包含键对应的值的。
但作者很聪明的,以i为变量,用cities_dict[i]['Capital']得到i对应的国家,因为cities_dict[i]={'Capital': 'China'},再往后面加上一个['Capital'],就变成了查询{'Capital': 'China'}字典的做法,这是非常巧妙的,两种方法各有好处,原理上都是一样的,country=cities_dict[i]。
五、喜欢的颜色
result_dict={'Allen': ['red','blue','yellow'],'Tom': ['green','white','blue'],'Andy': ['black','pink']}
for name,color in sorted(result_dict.items()):
print(f"{name}'s favorite colors are:")
for i in color:
print(i)或者这样
for i in sorted(result_dict):
print(f"{i}'s favorite colors are:")
for j in result_dict[i]:
print(j)六、生成字典
name=input().split()
langu=input().split()
dict1=zip(name,langu)
print(dict(dict1))这是标准答案,zip 函数是可以接收多个可迭代对象,然后把每个可迭代对象中的第i个元素组合在一起,形成一个新的迭代器,类型为元组。 但zip函数返回一个元组的迭代器,所以要么将其转化为别的类型,如dict()或list()等,否则想输出元素,需要使用多个next(dict1)。
PS:三个及以上的元素也可以使用zip函数组合在一起
参考:Python内置函数zip()函数详解_zip函数-优快云博客
以下为自己的想法:
str1=input().split()
str2=input().split()
my_dict={}
for i in range(len(str1)):
my_dict[str1[i]]=str2[i]
print(my_dict)在进行类型转换时可以使用如my_list=[(int)i for i in str],但输出时貌似不行。
七、查字典
my_dict={'a':['apple','abandon','ant'],'b':['banana','bee','become'],'c':['cat','come'],'d':'down'}
str=input()
if str in my_dict:
for i in my_dict[str]:
print(i,end=' ')
else:
print("error!")这里主要是不仅要查到字典中a对应的列表['apple', 'abandon', 'ant'],输出时还要以空格隔开逐个输出,类似于,apple abandon ant。
存在问题,输入d,输出d o w n,这是因为d所对应的字典不是列表,这样就把单词拆分了。
比较好的解决办法:
d = {'a': ['apple', 'abandon', 'ant'],
'b': ['banana', 'bee', 'become'],
'c': ['cat', 'come'],
'd': 'down'}
word = input()
if isinstance(d[word],list): #先判断是不是列表,如果是就遍历列表
for i in d[word]:
print(i,end=' ')
else: #不是的话直接输出
print(d[word])八、字典新增
my_dict={'a': ['apple', 'abandon', 'ant'], 'b': ['banana', 'bee', 'become'], 'c': ['cat', 'come'], 'd': 'down'}
key=input()
value=input()
my_dict[key]=value
print(my_dict)题目设置有问题,d对应的不是列表,导致输出时将单词down输出为d o w n。
PS:1.要注意变量的命名,最好让人看到就知道是干什么的,比如字典中的key和value。
·2.word = input(">>")在输入时将会看到一个提示符(>>),然后可以输入任何想要的内容,这样写对用户友好。

评论区有一个在题目之外还完善了的答案 ,我们在写代码是就应该考虑这么多,比如你想新增的key是否已存在于字典中,如果不存在,则添加,如果存在,那么再判断输入的单词是否在列表中已存在,如果不存在,则添加。
#改变了一下
#直接输入单词,首字母为键,单词为值
#判断是否重复
word_dict = {
'a': ['apple', 'abandon', 'ant'],
'b': ['banana', 'bee', 'become'],
'c': ['cat', 'come'],
'd': 'down'
}
word = input(">>")
#判断首字母是否存在字典键中
if word[0] in word_dict.keys():
#判断单词是否在对应键的值中
if word in word_dict[word[0]]:
print("exist!")
else:
word_dict[word[0]].append(word)
print(word_dict)
else:
word_dict[word[0]] = word
print(word_dict)但还是由于题目设置的问题,d对应的不是列表,这就导致添加时仍然会失败。
总的来说,我认为本题使大多数人出现问题,主要是题目的原因。字典中所有的value类型应该统一,但在本题中,仅仅因为目前d对应的value值只有一个,就没有设置它为列表类型,但这对于之后的字典的增删改查都是不方便的。
或者本题就是为了考验观察能力,那么,这也能说的过去(但提交答案时,并没有因为d的问题而判错)
无论如何,最正确的答案:(对于d的特殊情况,再加一个if语句,将其转换为list类型)
if letter in dic1:
if letter == 'd': #如果为d,需要转换成列表
list(dic1[letter]).append(word)
dic1[letter].append(word)
else:
#还不存在,需要将新数据变成list,就list(word)
dic1[letter]=word九、使用字典计数
my_dict={}
str_input=input()
for i in str_input:
count = str_input.count(i)
my_dict[i]=count
print(my_dict)使用python的内置函数count()方法计算输入单词中每个字母出现的次数。
或者:不使用函数
a = input()
a_dict = {}
for i in a:
if i in a_dict:
a_dict[i]+=1
else:
a_dict[i]=1
print(a_dict)或者:使用zip()函数或get函数
count_dict = {}
word = input()
for i in word:
count_dict[i] = count_dict.get(i,0) + 1
print(count_dict)get()函数用于获取指定键对应的值,如果i在字典中不存在,那么返回设置的0,再加1,即,若果之前不存在,就设为1,如果存在,get函数会返回上一次保存的次数,再加一。这个方法和上一个方法的原理差不多。
zip()函数可以将多个可迭代对象中对应的元素打包成一个元组,然后返回这些元组组成的迭代器。
a = input()
b = []
c = []
for i in a:
j=a.count(i)
b.append(i)
c.append(j)
print(dict(zip(b,c)))这个方法用一个空列表存储key,另一个存储次数。在循环结束之后,使用zip()函数打包,再转化为字典类型。
在这里有一个小发现,在Python中,字典的键必须是唯一的,如果你尝试使用相同的键来添加新的值,新的值会覆盖旧的值。这意味着如果你尝试将两组同样的键和值添加到字典中,后面的键值对会覆盖前面的键值对。
即,在上述代码中,如果我输入“hello”,得到的两组值
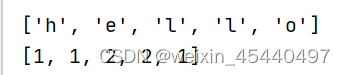
但在使用dict(zip(b,c)转换为字典类型后,只有一组:('l',2),这正是由于字典的特性得到的,
如果不转换为字典,而是list(zip(b,c),那么输出为
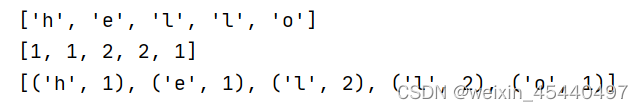
所以在循环中,无需担心多次遍历造成结果错误。
总体来说,解决本题还是count()方法好用,在编程时,可以多找找相应的函数,可以省很多事。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









