






这里只给大家简单的介绍一下图,什么是图? 大家所熟悉的链表和树 其实也都是图的一种特殊变体,既然是链表,那么就一定有节点和指针了
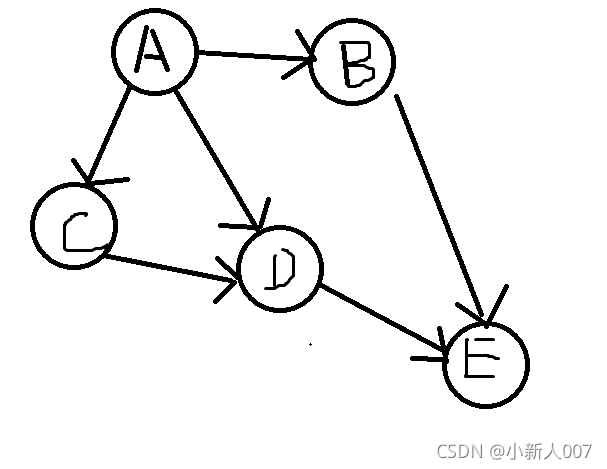
这就是图,有很多节点,互相连接,带箭头的线是单向的,俩个箭头的是双向的,这些线条就是他们的关系的代表称为边,可问题又来了,那么这么做有什么用呢?
其实各个节点都可以看作一个地点,比如北京到上海,需要经过很多站,但是你能保证从北京到上海只有一条路吗?那当然不可能了,所以图的作用也就凸显出来了,从各个路径中找到最合适的路径,再例如,我们常用的手机导航,每个地点就是节点,每次都会显示多条路线,我们可以自由选择其中的一条路线,每条路线就是图的边,这也是图
图的表示有两种,一种是 邻接列表 还有一个是邻接矩阵,本文主要围绕着邻接列表讲,下面就是邻接列表的图
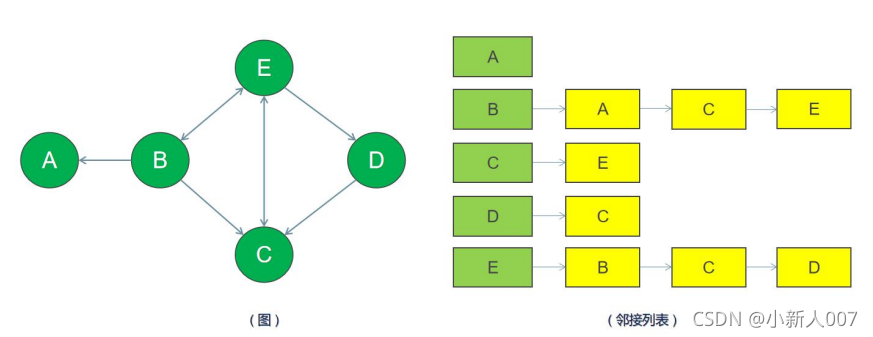
邻接列表主要记录了每个顶点(顶点其实就是结点,一个意思)的能通向哪些顶点,并用链表记录下来,所以他的抽象数据结构分配三个部分,
第一个部分是记录图的顶点和边的个数,还需要一个图节点的数组(方便用下标访问各个节点)。
第二个部分是 记录每个顶点的值,还有一个指针(他是用来连接该节点能连接到哪些节点,并用链表的形式连接起来)。
第三部分是 记录了第二部分链表节点的内容。
代码如下:
#define MAXSIZE 10
typedef struct _GraphEdge {
int adjvertex; //顶点下标
int weight; //权值
_GraphEdge* next; //记录下一条边的顶点
}GraphEdge;
typedef struct _GraphVertex {
char value; //每个顶点的值
GraphEdge* adjArr; //每个顶点的边的数组
}GraphVertex;
typedef struct _GraphNode {
GraphVertex* adjVertex; //每个顶点的存放数组
int vertex; //顶点
int edge; //边数
}GraphNode;数据结构有了,剩下的就是实现功能了,初始化图,创建图
//初始化图节点
void initGraph(GraphNode& G) {
G.adjVertex = new GraphVertex[MAXSIZE]; //初始化大小
G.vertex = 0;
G.edge = 0;
}
//创建图节点
void creatGraph(GraphNode& G) {
//if (!G)return;
cout << "请输入顶点和边的数量: " << endl;
cin >> G.vertex >> G.edge;
if (G.vertex > MAXSIZE || G.edge > MAXSIZE) {
cout << "输入的边或者顶点的数量非法!!!" << endl;
return;
}
cout << "请输入各个顶点: " << endl;
for (int i = 0; i < G.vertex; i++)
{
cin >> G.adjVertex[i].value;
G.adjVertex[i].adjArr = NULL;
}
cout << "输入各个边的关系: " << endl;
char v1, v2;
int i1, i2; //用来记录顶点的下标
for (int i = 0; i < G.edge; i++)
{
cin >> v1 >> v2; //输入两条边
i1 = findGraphIndex(G, v1); //去查找要记录的顶点下标
i2 = findGraphIndex(G, v2); //记录可以连接的顶点下标
if (i1 != -1 && i2 != -1) {
GraphEdge* tmp = new GraphEdge; //创建新的节点
tmp->adjvertex = i2; //把刚才的顶点下标记录一下
tmp->next = G.adjVertex[i1].adjArr;
G.adjVertex[i1].adjArr = tmp;
}
}
}
//查找节点下标
int findGraphIndex(GraphNode& G, char value) {
for (int i = 0; i < G.vertex; i++)
{
if (G.adjVertex[i].value == value) {
return i;
}
}
return -1;
}图的遍历也分为两种, 一种是 深度优先遍历,另一种是 广度优先遍历。
深度优先遍历: 他主要是遍历每一个顶点,然后遍历该顶点的每一个能通项的其他顶点,不讲究顺序,只关心一个节点能最深到哪里去,如果走不同了,那么就回溯到上一个顶点,这就用到了递归了,代码如下:
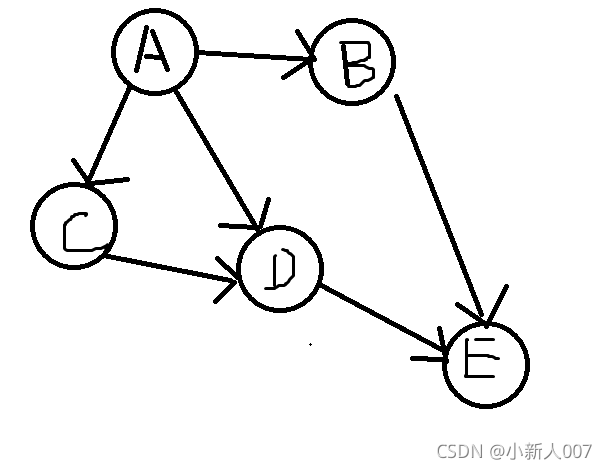
该图的深度遍历结果为 ,A - B - E - D - C (结果的顺序不唯一),他的顺序是根据你链表记录的结构产生的。
//DFC遍历某一个顶点s
void DFC(GraphNode& G, int vertex) {
//visited是一个全局的bool类型的数组,用来记录每个顶点的访问状况
if (visited[vertex])return; //如果当前传进来的顶点为空那么就回溯到上一个顶点
int cur = 0; //用来记录顶点的下标
cout << G.adjVertex[vertex].value << " "; //输出当前顶点的值
visited[vertex] = true; //输出完,就置为true,只有为 false 才会进行执行
GraphEdge* tmp = G.adjVertex[vertex].adjArr; //获得当前顶点的通向其他节点的节点
//一直进行递归遍历,这也就达到了深度的遍历,所以叫做深度优先遍历
while (tmp)
{
cur = tmp->adjvertex;
tmp = tmp->next;
if (visited[cur] == false) {
DFC(G, cur);
}
}
}
//DFC遍历所有的顶点
void dfcWhole(GraphNode& G) {
for (int i = 0; i < G.vertex; i++)
{
if (visited[i] == false) {
DFC(G, i);
}
}
}广度优先遍历: 他就是先把当前顶点的所有可以通向的顶点都打印出来,在进行别的顶点,使用到了队列,因为先进先出的特性,代码如下:
该图的深度遍历结果为 ,A - C - D - B - E (结果的顺序不唯一),他的顺序是根据你链表记录的结构产生的。
void BFC(GraphNode& G,int val) {
queue<int>q;
int cur = -1;
int next= -1;
q.push(val);
while (!q.empty())
{
cur = q.front(); //获得队列的头
if (visited[cur] == false) {
cout << G.adjVertex[cur].value << " ";
visited[cur] = true;
}
q.pop();
GraphEdge* tmp = G.adjVertex[cur].adjArr;
while (tmp)
{
next = tmp->adjvertex;
tmp = tmp->next;
q.push(next);
}
}
}
//BFC遍历所有的节点
void bfcWhole(GraphNode& G) {
for (int i = 0; i < G.vertex; i++)
{
if (visited[i] == false) {
BFC(G,i);
}
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









