







 本文介绍了一个使用Python的urllib库来爬取糗事百科网站笑话的示例代码。通过设置User-Agent并利用正则表达式提取网页中的笑话内容。
本文介绍了一个使用Python的urllib库来爬取糗事百科网站笑话的示例代码。通过设置User-Agent并利用正则表达式提取网页中的笑话内容。
代码如下:
import urllib.request
import re
headers = ("User-Agent", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36")
opener = urllib.request.build_opener()
opener.addheaders = [headers]
# UA安装为全局
# 使用urllib.request下的install_opener(),使UA安装为全局,之后使用urlopen()请求链接,会自动携带报头
urllib.request.install_opener(opener)
for i in range(0, 2):
this_url = "https://www.qiushibaike.com/text/page/"+str(i+1)+"/"
data = urllib.request.urlopen(this_url).read().decode("utf-8", "ignore")
pat = '<div class="content">.*?<span>(.*?)</span>'
# re.S 模式修正符,让.匹配包括换行符
rst = re.compile(pat, re.S).findall(data)
print(this_url)
# 每个段子之间用“----”隔开
for j in range(0, len(rst)):
print(rst[j])
print("--------------")
结果为:
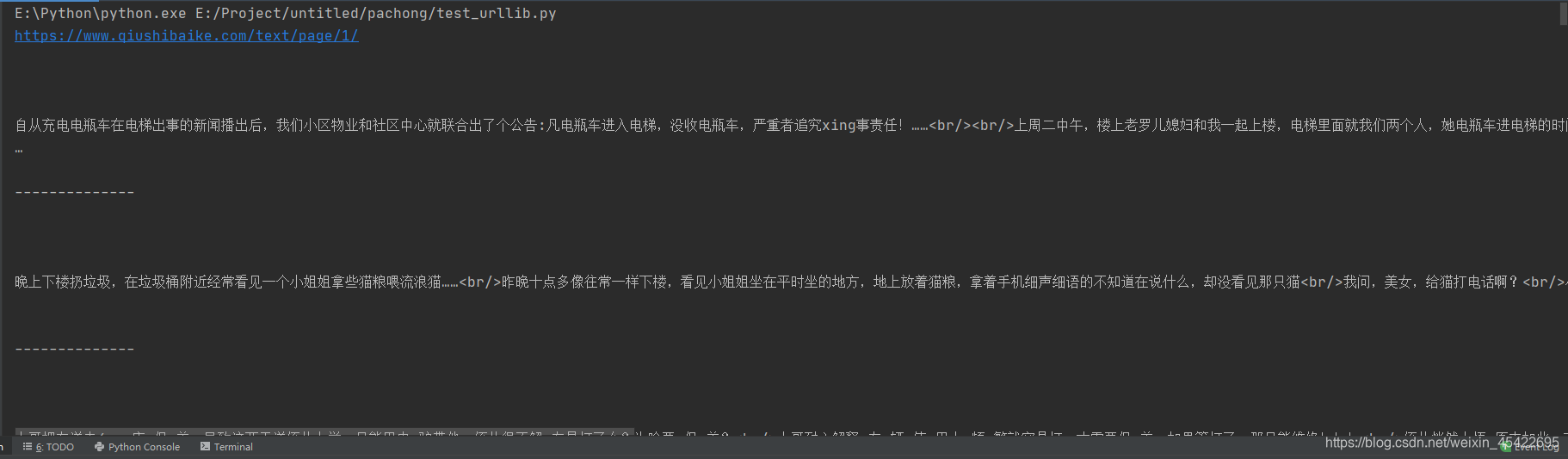
注意点:
1、UA安装为全局:
固定语法为:
opener = urllib.request.build_opener()
opener.addheaders = [headers]
urllib.request.install_opener(opener)
UA安装为全局后,会自动携带报头,之后可全局使用urllib.request.urlopen(url),url会自动携带报头信息
2、url拼接:
url拼接使用了变量i,i为整型,需转换为字符串str(i),方可拼接
由于url变量页数从1开始,变量i一般从0开始,故拼接时,使变量+1,即str(i+1),url中的页数变量即可从第一页开始
3、模式修正符:
正则匹配时,处有换行符,“.”不能匹配到换行符,所以使用模式修正符re.S,让“.”匹配包括换行符
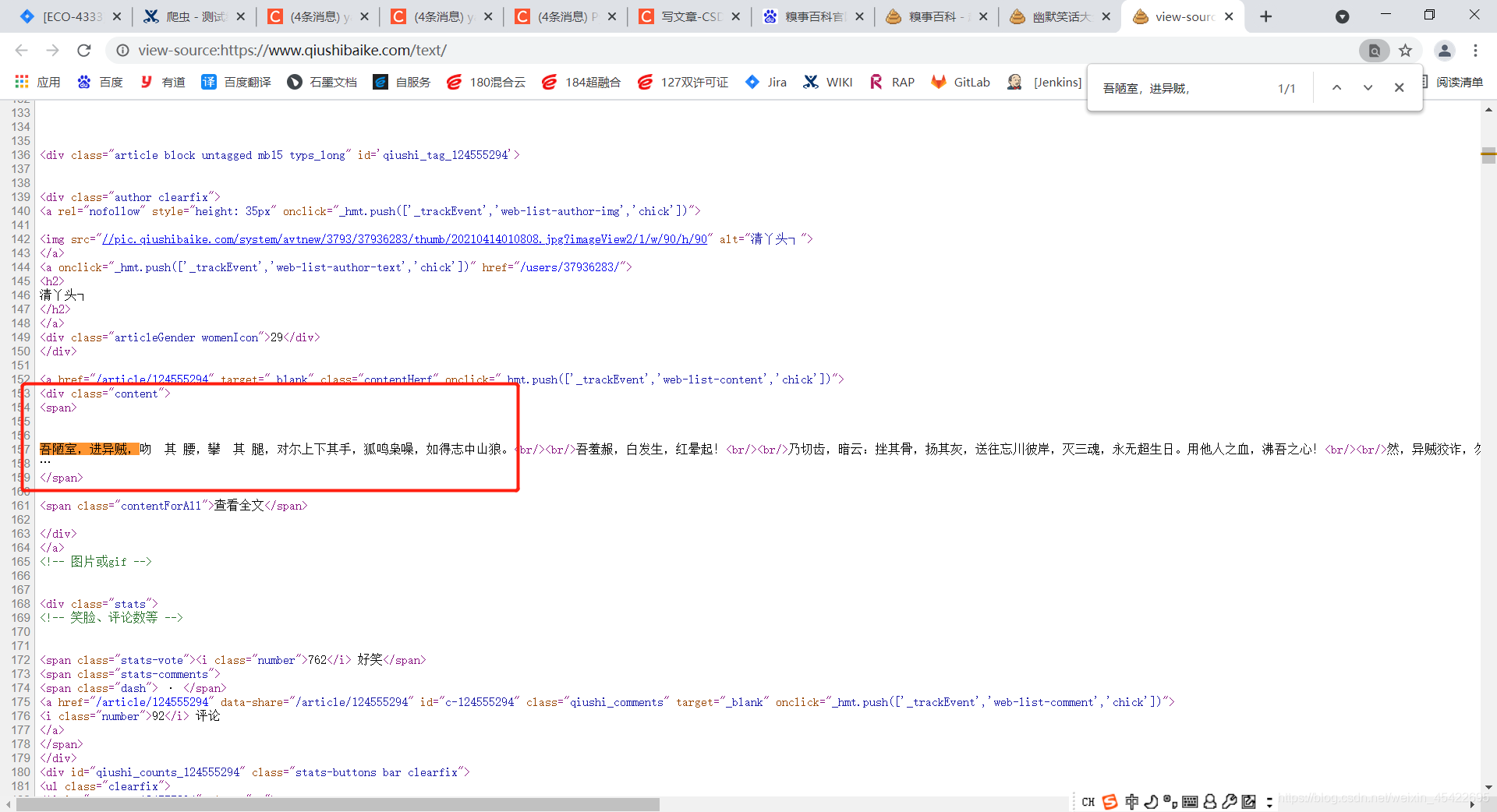
4、段子分割:
每个url页面有25个段子,若不分割,则全部显示在一行,故使用for循环,将每个段子隔开

















 3942
3942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









