







12.程序性能检测及优化
在图像处理中你每秒钟都要做大量的运算,所以你的程序不仅要能给出正 确的结果,同时还必须要快。所以这节我们将要学习:
• 检测程序的效率.
• 一些能够提高程序效率的技巧.
• 你要学到的函数有:cv2.getTickCount,cv2.getTickFrequency 等。
除了 OpenCV,Python 也提供了一个叫 time 的的模块,你可以用它来计算程序的运行时间。另外一个叫做 profile 的模块会帮你得到一份关于你的程序的详细报告,其中包含了代码中每个函数运行需要的时间,以及每个函数被调用的次数。如果你正在使用 IPython 的话,所有这些特点都被以一种用户友好的方式整合在一起了。我们会学习几个重要的,要想学到更加详细的知识就打 开更多资源中的链接吧。
12.1使用OpenCV检测程序效率
cv2.getTickCount 函数返回从参考点到这个函数被执行的时钟数。所以当你在一个函数执行前后都调用它的话,你就会得到这个函数的执行时间(时钟数)。
cv2.getTickFrequency 返回时钟频率,或者说每秒钟的时钟数。所以 你可以按照下面的方式得到一个函数运行了多少秒:
import cv2
e1 = cv2.getTickCount()
e2 = cv2.getTickCount()
time = (e2 - e1)/ cv2.getTickFrequency()
我们将会用下面的例子演示。下面的例子是用窗口大小不同(5,7,9)的 核函数来做中值滤波:
import cv2
img1 = cv2.imread('roi.jpg')
e1 = cv2.getTickCount()
for i in range(5, 49, 2):
img1 = cv2.medianBlur(img1, i)
e2 = cv2.getTickCount()
t = (e2 - e1) / cv2.getTickFrequency()
print(t)
# Result I got is 0.521107655 seconds
代码解析:
cv2.getTickCount():返回 CPU 的时钟周期数(高精度计时器)
-
range(5, 49, 2):生成一个从 5 到 48 的奇数序列(步长为 2),即[5, 7, 9, ..., 47, 49]。-
为什么用奇数?:中值滤波的核大小必须是奇数。
-
-
cv2.medianBlur(img1, i):对图像img1应用中值滤波,核大小为i×i。-
中值滤波的作用:去除噪声(如椒盐噪声),同时保留边缘。
-
注意:每次滤波的结果会覆盖
img1,因此滤波是 累积叠加 的。
-
-
cv2.getTickFrequency():返回 CPU 每秒的时钟周期数(用于将周期数转换为秒)。 -
公式:

-
结果:
t是代码执行的总时间(单位:秒)。
关键点总结
-
中值滤波的累积效果:
-
每次循环都会在前一次滤波结果的基础上再次滤波,核大小逐步增大(5→7→...→49)。
-
最终图像会变得非常模糊(因为大核滤波会抹去更多细节)。
-
-
性能测试目的:
这段代码主要用于 测试中值滤波在不同核大小下的耗时,而非实际图像处理需求。 -
时间计算的原理:
getTickCount()提供高精度计时,适合测量短时间操作的性能。
t = (e2 - e1) / cv2.getTickFrequency()
这行代码的作用是 计算代码段的执行时间(单位:秒),具体分解如下:
1. 核心组件
-
cv2.getTickCount()-
返回当前CPU的时钟周期计数(高精度计时器,单位是" ticks ")。
-
类似秒表,记录某一时刻的计数器值。
-
-
cv2.getTickFrequency()-
返回CPU每秒的时钟周期数(即计时器的频率,单位是" ticks/second ")。
-
例如,若频率为
1000000,表示每秒有100万次时钟周期。
-
2. 计算步骤
-
获取两个时间点之间的时钟周期差值(即代码执行消耗的周期数)。e2 - e1 -
将周期数转换为秒:(e2 - e1) / cv2.getTickFrequency()
-
-
设你的心脏每分钟跳60次(频率=60次/分钟)。
-
某件事发生时心跳了30次 → 耗时 = 30 / 60 = 0.5分钟。
-
-
代码中的逻辑:
-
e1和e2是开始和结束时的“心跳计数”。 -
getTickFrequency()是“心脏频率”(每秒多少次)。 -
最终时间 = (结束计数 - 开始计数) / 频率。
-
4. 为什么用这种方式计时?
-
高精度:CPU时钟周期是纳秒级精度,适合测量短时间操作(如OpenCV图像处理)。
-
跨平台:OpenCV封装了底层硬件计时器,保证不同系统下的准确性。
5. 示例
假设:
-
e1 = 1000(开始时的周期数) -
e2 = 2500(结束时的周期数) -
cv2.getTickFrequency() = 1000000(每秒100万周期)
计算: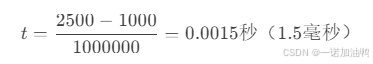
6. 对比Python标准库
如果用Python的 time 模块,等效写法是:
import time st行art = time.time() # 执代码... end = time.time() t = end - start # 直接得到秒数
但 cv2.getTickCount() 精度通常更高(尤其是Windows系统)
注 意: 你 也 可 以 中 time 模 块 实 现 上 面 的 功 能。 但 是 要 用 的 函 数 是 time.time() 而不是 cv2.getTickCount。 比较一下这两个结果的差别 吧。
中值滤波(Median Filter) 是一种常用的非线性图像处理技术,主要用于去除噪声(尤其是椒盐噪声)同时保留边缘细节。它的核心思想是用像素邻域的中值替代当前像素值,而非像均值滤波那样取平均值。
1. 基本原理
-
操作步骤:
-
定义一个滑动窗口(通常为奇数的正方形,如 3×3、5×5)。
-
将窗口内的所有像素值排序。
-
取排序后的中间值(中位数)作为当前中心像素的新值。
-
-
数学表达:
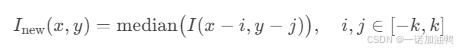
其中 k 是窗口半径(如 3×3 窗口的 k=1)。
2. 关键特点
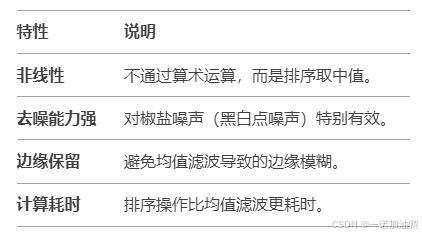
3. 与均值滤波的对比

4. 代码示例(OpenCV)
import cv2
import numpy as np
# 读取图像(添加椒盐噪声示例)
img = cv2.imread('image.jpg', 0) # 灰度图
noisy_img = np.copy(img)
# 随机添加椒盐噪声
salt_pepper_prob = 0.05 # 噪声比例
noise = np.random.rand(*img.shape)
noisy_img[noise < salt_pepper_prob/2] = 0 # 椒噪声(黑点)
noisy_img[noise > 1 - salt_pepper_prob/2] = 255 # 盐噪声(白点)
# 中值滤波去噪
kernel_size = 5 # 5x5窗口
denoised_img = cv2.medianBlur(noisy_img, kernel_size)
# 显示结果
cv2.imshow('Noisy Image', noisy_img)
cv2.imshow('Denoised Image', denoised_img)
cv2.waitKey(0)
cv2.destroyAllWindows()5. 直观效果
-
输入图像:(黑白点状噪声)
-
中值滤波后:(噪声消失,边缘清晰)
6. 参数选择
-
窗口大小(
kernel_size):-
较小(如 3×3):去噪较弱,但细节保留更好。
-
较大(如 7×7):去噪更强,但可能过度平滑。
-
-
经验法则:
-
椒盐噪声:窗口大小通常为 3 或 5。
-
大颗粒噪声:可能需要更大的窗口(但需权衡边缘损失)。
-
7. 应用场景
-
图像去噪:修复扫描文档的黑白噪点。
-
医学影像:去除CT/MRI中的孤立噪声点。
-
实时视频处理:抑制摄像头采集的随机噪声。
8. 注意事项
-
不适用于高斯噪声:中值滤波对随机分布的灰度噪声(高斯噪声)效果较差,此时均值滤波或高斯滤波更合适。
-
避免过大窗口:可能导致图像纹理丢失。
总结
中值滤波通过排序取中值的方式,在去除椒盐噪声的同时最大程度保留边缘,是图像去噪的经典工具。其非线性特性使其在特定场景下比线性滤波(如均值滤波)更具优势。
椒盐噪声(Salt-and-Pepper Noise) 是数字图像中常见的一种噪声类型,其特点是图像中随机出现的纯白(盐)和纯黑(椒)像素点,类似于撒在图像上的胡椒和盐粒,因此得名。
1. 噪声特征
-
表现形式:
-
白点(盐噪声):像素值为最大值(如255,8位图像中为纯白)。
-
黑点(椒噪声):像素值为最小值(如0,纯黑)。
-
-
分布:随机出现在图像的任何位置,通常稀疏但明显。
2. 产生原因

3. 与其他噪声的对比
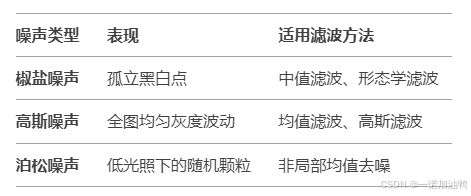
4. 模拟椒盐噪声的代码(Python)
import numpy as np
import cv2
def add_salt_pepper_noise(image, prob=0.05):
"""
添加椒盐噪声
:param image: 输入图像(灰度或彩色)
:param prob: 噪声比例(默认5%)
:return: 带噪声的图像
"""
output = np.copy(image)
# 生成随机噪声矩阵
rng = np.random.rand(*image.shape)
# 椒噪声(黑点)
output[rng < prob/2] = 0
# 盐噪声(白点)
output[rng > 1 - prob/2] = 255
return output
# 示例使用
img = cv2.imread('lena.jpg', 0) # 读取灰度图
noisy_img = add_salt_pepper_noise(img, prob=0.1) # 添加10%噪声
cv2.imshow('Noisy Image', noisy_img)
cv2.waitKey(0)5. 去噪方法
(1) 中值滤波(最佳选择)
denoised = cv2.medianBlur(noisy_img, 3) # 3x3窗口
-
原理:用邻域中值替代噪声点(黑白点是极端值,排序后会被剔除)。
(2) 均值滤波(效果较差)
denoised = cv2.blur(noisy_img, (3,3)) # 3x3均值
-
缺点:会模糊边缘,且无法完全去除噪声。
(3) 自适应滤波
-
结合局部统计特性,更适合非均匀噪声。
7. 实际应用场景
-
老旧照片修复:去除扫描照片的黑白噪点。
-
监控视频处理:抑制摄像头传输中的突发噪声。
-
医学影像:清理X光片或显微镜图像的孤立噪声。
8. 注意事项
-
噪声密度:若噪声比例过高(如>20%),中值滤波可能失效。
-
彩色图像:需分别处理每个通道(BGR),或转换到HSV空间处理亮度通道。
总结
椒盐噪声是图像中随机出现的黑白像素点,通常由硬件故障或传输错误引起。中值滤波是其经典解决方案,能在去噪的同时保留边缘信息。理解这种噪声有助于选择正确的图像复原方法。
高斯噪声(Gaussian Noise) 是数字图像和信号处理中最常见的一种噪声类型,其特点是噪声值服从正态分布(高斯分布),表现为图像像素值的随机微小波动。以下是详细解析:
1. 核心特性

2. 与椒盐噪声的对比

3. 数学建模
在图像中,高斯噪声的数学模型为:

4. 代码模拟高斯噪声(Python/OpenCV)
import cv2
import numpy as np
def add_gaussian_noise(image, mean=0, sigma=25):
"""
添加高斯噪声
:param image: 输入图像(灰度或彩色)
:param mean: 噪声均值(默认0)
:param sigma: 噪声标准差(默认25)
:return: 带噪声的图像
"""
row, col, ch = image.shape
gauss = np.random.normal(mean, sigma, (row, col, ch))
noisy = image + gauss
return np.clip(noisy, 0, 255).astype(np.uint8) # 确保值在0-255范围内
# 示例
img = cv2.imread('lena.jpg') # 读取彩色图像
noisy_img = add_gaussian_noise(img, sigma=30) # 添加标准差为30的噪声
cv2.imshow('Noisy Image', noisy_img)
cv2.waitKey(0)5. 去噪方法
(1) 高斯滤波(线性滤波)
blurred = cv2.GaussianBlur(noisy_img, (5,5), 0) # 5x5高斯核
-
原理:用高斯加权平均值替代中心像素,抑制噪声。
-
缺点:会轻微模糊边缘。
(2) 非局部均值去噪(Non-Local Means)
denoised = cv2.fastNlMeansDenoisingColored(noisy_img, None, 10, 10, 7, 21)
-
优势:保留细节更好,但计算较慢。
(3) 小波变换
-
适用于高频噪声分离,需专用库(如PyWavelets)。
6. 实际应用场景
-
低光照摄影:手机夜间模式拍摄的图像常含高斯噪声。
-
医学影像:MRI/CT图像中的热噪声。
-
无线传输:受信道干扰的监控视频。
7. 参数影响
-
标准差(σ):
-
σ越小 → 噪声越微弱(如σ=10)。
-
σ越大 → 噪声越明显(如σ=50)。
-
-
均值(μ):
通常设为0,非零值会导致整体亮度偏移。
8. 注意事项
-
彩色图像:需在RGB各通道分别添加噪声,或转换到YUV空间仅处理亮度通道(Y)。
-
噪声叠加:实际图像可能同时存在高斯噪声和椒盐噪声,需组合滤波方法。
总结
高斯噪声是图像中符合正态分布的随机波动,广泛存在于电子成像系统中。通过高斯滤波或非局部均值算法可有效抑制,但需权衡去噪强度与细节保留。理解其特性有助于优化图像处理流程。
12.2 OpenCV中的默认优化
OpenCV 中的很多函数都被优化过(使用 SSE2,AVX 等)。也包含一些 没有被优化的代码。如果我们的系统支持优化的话要尽量利用只一点。在编译时 优化是被默认开启的。因此 OpenCV 运行的就是优化后的代码,如果你把优化 关闭的话就只能执行低效的代码了。你可以使用函数 cv2.useOptimized() 来查看优化是否被开启了,使用函数 cv2.setUseOptimized() 来开启优化。
# check if optimization is enabled
In [5]: cv.useOptimized()
Out[5]: True
In [6]: %timeit res = cv.medianBlur(img,49)
10 loops, best of 3: 34.9 ms per loop
# Disable it
In [7]: cv.setUseOptimized(False)
In [8]: cv.useOptimized()
Out[8]: False
In [9]: %timeit res = cv.medianBlur(img,49)
10 loops, best of 3: 64.1 ms per loop
看见了吗,优化后中值滤波的速度是原来的两倍。如果你查看源代码的话, 你会发现中值滤波是被 SIMD优化的。所以你可以在代码的开始处开启优化(优化是默认开启的)。
12.3在IPython中检测程序效率
有时你需要比较两个相似操作的效率,这时你可以使用 IPython 为你提供 的魔法命令%time。他会让代码运行好几次从而得到一个准确的(运行)时 间。它也可以被用来测试单行代码的。
例如,你知道下面这同一个数学运算用哪种行式的代码会执行的更快吗?
x = 5; y = x ∗ ∗2
x = 5; y = x ∗ x
x = np.uint([5]); y = x ∗ x y = np.squre(x)




关键对比总结
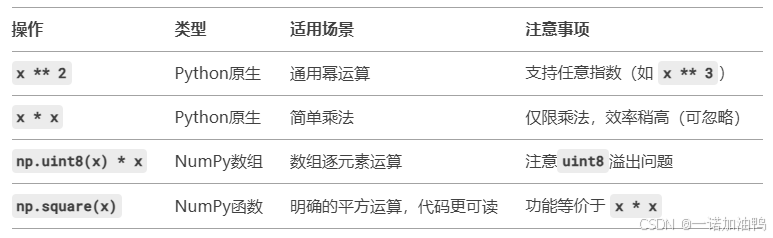
扩展说明
1. 数据类型的重要性(NumPy)
-
np.uint8([5])定义了 8位无符号整数数组,取值范围 0-255。-
若计算结果超出范围,会截断(模运算):
x = np.uint8([200]) y = x * x # 200*200=40000 → 40000 % 256 = 144 → y=array([144], dtype=uint8)
-
2. 性能考虑
-
对于大规模数组,
np.square(x)和x * x性能几乎相同,均优化为底层C运算。 -
Python原生的
**和*在小规模计算中无差别。
3. 实际应用建议
-
标量计算:直接用
x * x或x ** 2(简洁)。 -
NumPy数组:优先用
np.square(x)(意图明确,避免溢出问题)。
代码验证示例
import numpy as np
# 标量计算
x = 5
print("Python原生:")
print("x ** 2 =", x ** 2) # 输出 25
print("x * x =", x * x) # 输出 25
# NumPy数组计算
x_np = np.uint8([5])
print("\nNumPy数组:")
print("x * x =", x_np * x_np) # 输出 [25]
print("np.square(x) =", np.square(x_np)) # 输出 [25]
# 溢出测试
x_overflow = np.uint8([200])
print("\n溢出测试:")
print("200 * 200 (uint8) =", x_overflow * x_overflow) # 输出 [144]我们可以在 IPython 的 Shell 中使用魔法命令找到答案。
In [10]: x = 5
In [11]: %timeit y=x**2
10000000 loops, best of 3: 73 ns per loop
In [12]: %timeit y=x*x
10000000 loops, best of 3: 58.3 ns per loop
In [15]: z = np.uint8([5])
In [17]: %timeit y=z*z
1000000 loops, best of 3: 1.25 us per loop
In [19]: %timeit y=np.square(z)
1000000 loops, best of 3: 1.16 us per loop
竟然是第一种写法,它居然比 Nump 快了 20 倍。如果考虑到数组构建的 话,能达到 100 倍的差。
注意:Python 的标量计算比 Nump 的标量计算要快。对于仅包含一两个 元素的操作 Python 标量比 Numpy 的数组要快。但是当数组稍微大一点时 Numpy 就会胜出了。
我 们 来 比 较 一 下 cv2.countNonZero() 和np.count_nonzero()。
In [35]: %timeit z = cv.countNonZero(img)
100000 loops, best of 3: 15.8 us per loop
In [36]: %timeit z = np.count_nonzero(img)
1000 loops, best of 3: 370 us per loop
看见了吧,OpenCV 的函数是 Numpy 函数的 25 倍。
注意:一般情况下 OpenCV 的函数要比 Numpy 函数快。所以对于相同的操 作最好使用 OpenCV 的函数。当然也有例外,尤其是当使用 Numpy 对视图(而非复制)进行操作时。
12.4效率优化技术
有些技术和编程方法可以让我们最大的发挥 Python 和 Numpy 的威力。 我们这里仅仅提一下相关的,你可以通过超链接查找更多详细信息。我们要说 的最重要的一点是:首先用简单的方式实现你的算法(结果正确最重要),当结 果正确后,再使用上面的提到的方法找到程序的瓶颈来优化它。
1. 尽量避免使用循环,尤其双层三层循环,它们天生就是非常慢的。
2. 算法中尽量使用向量操作,因为 Numpy 和 OpenCV 都对向量操作进行了优化。
3. 利用高速缓存一致性。
4. 没有必要的话就不要复制数组。使用视图来代替复制。数组复制非常浪费资源。
就算进行了上述优化,如果你的程序还是很慢,或者说大的训话不可避免的话, 你你应该尝试使用其他的包,比如说 Cython,来加速你的程序。
还有几个魔法命令可以用来检测程序的效率,profiling,line profiling, 内存使用等。他们都有完善的文档。所以这里只提供了超链接。感兴趣的可以 自己学习一下。
更多资源
cv2.countNonZero() 和 np.count_nonzero() 都是用于计算数组中非零元素数量的函数,但它们在 输入类型、功能细节 和 使用场景 上有一些区别。以下是详细对比:
1. cv2.countNonZero()(OpenCV函数)
功能
-
计算单通道数组(通常是图像或掩码)中非零像素的数量。
-
仅适用于单通道(如灰度图、二值掩码)。
语法
count = cv2.countNonZero(src)
-
src:输入数组(必须是单通道,如cv2.Mat或numpy.ndarray)。
特点
-
只支持单通道:多通道图像需先拆分或转换为灰度。
-
针对图像优化:OpenCV内部优化,适合处理图像数据。
-
输入类型:通常用于
uint8类型的二值掩码(0或255)。
示例
import cv2
import numpy as np
# 创建一个二值掩码(单通道)
mask = np.array([[0, 255, 0],
[255, 0, 255]], dtype=np.uint8)
count = cv2.countNonZero(mask)
print(count) # 输出:3(非零像素数)
2. np.count_nonzero()(NumPy函数)
功能
-
计算任意维度的NumPy数组中非零元素的总数。
-
支持多通道和多维数组。
语法
count = np.count_nonzero(arr)
-
arr:输入数组(可以是任意维度和数据类型)。
特点
-
通用性强:支持任何维度的数组(如RGB图像、多维矩阵)。
-
灵活性高:可结合条件统计(如
np.count_nonzero(arr > 5))。 -
输入类型:不限制数据类型(
int、float、bool等均可)。
示例
import numpy as np
# 单通道示例
mask = np.array([[0, 255, 0],
[255, 0, 255]], dtype=np.uint8)
count = np.count_nonzero(mask)
print(count) # 输出:3
# 多通道示例(如RGB图像)
rgb_img = np.array([[[255, 0, 0], [0, 255, 0]],
[[0, 0, 255], [0, 0, 0]])
count = np.count_nonzero(rgb_img)
print(count) # 输出:3(统计所有通道的非零值)
3. 核心区别对比
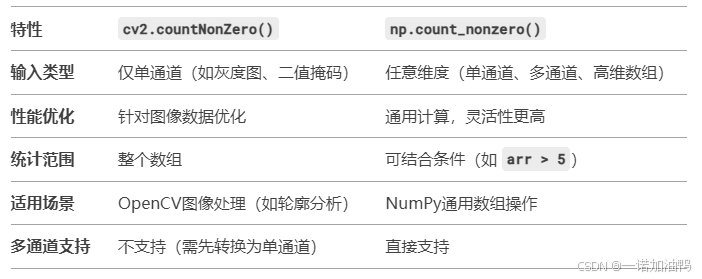
4. 如何选择?
-
处理OpenCV图像/掩码 → 优先用
cv2.countNonZero()(效率更高)。 -
处理多维数组或需要条件统计 → 用
np.count_nonzero()。 -
多通道图像的非零统计 → 必须用
np.count_nonzero()。
5. 进阶用法
(1) 统计多通道图像的非零像素
# 方法1:合并所有通道
rgb_img = cv2.imread('image.jpg') # 3通道BGR
count = np.count_nonzero(rgb_img) # 统计所有通道
# 方法2:分通道统计
count_per_channel = [np.count_nonzero(rgb_img[:, :, i]) for i in range(3)]
(2) 条件统计(NumPy)
arr = np.array([[1, 0, 3], [4, 5, 0]]) count = np.count_nonzero(arr > 2) # 统计大于2的元素数量 print(count) # 输出:2(3和4满足条件)
总结
-
cv2.countNonZero():专为OpenCV单通道图像设计,高效但功能有限。 -
np.count_nonzero():NumPy通用函数,灵活支持复杂场景。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









