







 本文介绍了图计算的概念,以SparkGraphX为例,阐述了其作为分布式图处理框架的作用,统一了图数据和结构化数据的处理。文章详细讲解了PageRank、最短路径、社群发现等常见图算法,并探讨了GraphX的数据抽象RDPG和图的基本结构。通过社交网络关系查询的案例展示了GraphX的使用。
本文介绍了图计算的概念,以SparkGraphX为例,阐述了其作为分布式图处理框架的作用,统一了图数据和结构化数据的处理。文章详细讲解了PageRank、最短路径、社群发现等常见图算法,并探讨了GraphX的数据抽象RDPG和图的基本结构。通过社交网络关系查询的案例展示了GraphX的使用。
SparkGraphX基本介绍
一、什么是图
什么是图?图计算都在计算什么?我们可以从社交网络、人物关系挖掘、节点之间依赖计算等方面来理解图计算。首先,图数据存在于我们生活的方方面面,如果将数据相关方分别定位为一个点,而他们之间的互相联系抽象为边,那整个不同事物时间的错综复杂的联系就构成了一幅幅“图数据”。
社交关系数据:将每个人作为一个点,而人与人之间的互动关系是边,那么庞大的社交圈子中,不同人之间的互动联系就构成了庞大的社交关系数据。
网页链接数据:通过一个网页链接,可以跳转到其他多个网页,这么一来,网页与网页之间的多个跳转联系就构成了一个复杂的网页链接数据。通过这些数据可以进行多个研究,比如可以分析出来哪个网页是入口大的重要网页等。
图数据和图计算应用,比如可以通过交易网络数据图来分析出哪些交易是欺诈交易、通过通信网络数据图来分析企业员工之间不正常的社交、通过用户—商品图数据图来分析用户需求,做个性化推荐等。
二、什么是SparkGraphX
GraphX官网:http://spark.apache.org/graphx/
Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求。
GraphX是一个使用非常广泛的图计算库,而在GraphX之前,也有许多的图计算库,比如Pregel、Giraph、GraphLab等,他们有着共同的特点:定义了独特的图计算API,简化图算法的实现;充分利用图数据结构特点加速计算,比通用的数据驱动的计算引擎更快。但随着需求的变化,这些图计算库逐渐被淘汰了,这是为什么呢?
观察近现代图计算整个流程,在图计算整个流程里面涉及了两部分的计算:一是结构化数据的计算和提取,二是图数据计算与分析。为了完成结构化数据和图数据的处理,在GraphX出来之前,公司主要是用Hadoop和Spark这种通用的计算引擎来解决,后半部分是用专门的图计算引擎Pregel来处理,这就需要同时维护和学习两套计算引擎,比较麻烦。如下图表示:
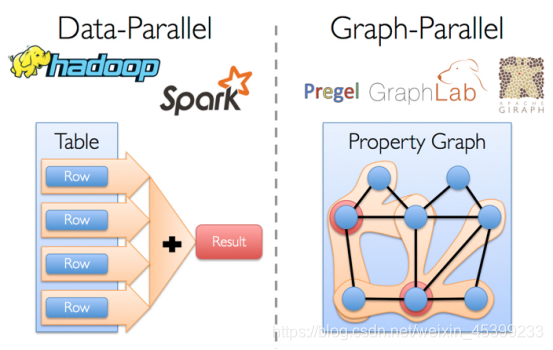
可能有人会说:用两套系统就可以解决问题了啊。但你有所不知的是,同时混用多个引擎会出现非常多的问题,如成本高,效率低下,数据冗余等问题,这样会使整个计算过程变得复杂。
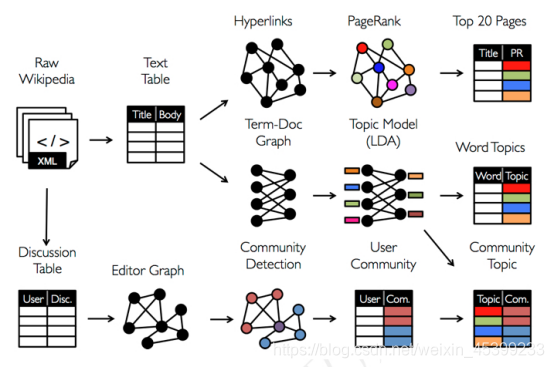
在传统的图计算流水线中,在Table View视图下,可能需要Spark或者Hadoop的支持,在Graph View这种视图下,可能需要Prege或者GraphLab的支持。也就是把图和表分在不同的系统中分别处理。 不同系统之间数据的移动和通信会成为很大的负担。
而GraphX就解决了这一问题,将分布式图graph-parallel和分布式数据data-parallel统一到一个系统中,并提供了一个唯一的组合API ,GraphX允许用户把数据当做一个图和一个集合(RDD),而不需要数据移动或者复制。作为统一的图计算引擎,GraphX可以实现在一个数据流水线中,使用一种技术解决图计算相关所有问题!
GraphX包含两大特色:
新API:打破了结构化数据和图数据的界限。
新Library:直接在Spark上完成图计算。
三、常见的图算法
通常,在图计算中,基本的数据结构表达就是:G = (V,E,D) V = vertex (顶点或者节点) E = edge (边) D = data (权重)。 图数据结构很好的表达了数据之间的关联性,因此,很多应用中出现的问题都可以抽象成图来表示,以图论的思想或者以图为基础建立模型来解决问题。
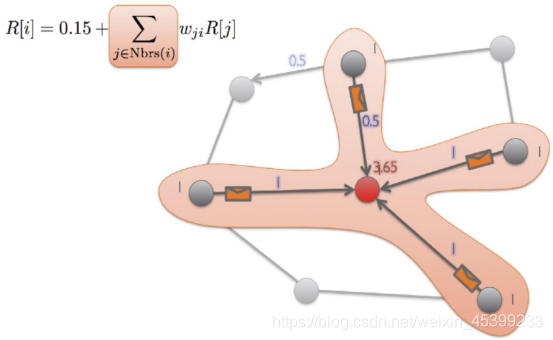
1、PageRank算法
PageRank源自搜索引擎,它是搜索引擎里面非常重要的图算法,可用来对网页做排序。比如我们在网页里搜索spark,会出来非常多有着spark关键字的网页,可能有上千上万个相关网页,而PageRank可以根据这些网页的排序算法将其排序,将一些用户最需要的网页进行优先展示。
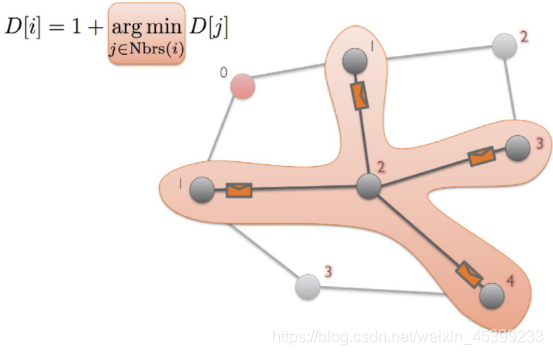
2、最短路径算法
在社交网络里面,有一个六度空间的理论,表示你和任何一个陌生人之间所间隔的人不会超过五个,也就是说,最多通过五个中间人你就能够认识任何一个陌生人。这也是图算法的一种,也就是说,任何两个人之间的最短路径都是小于等于6。
3、社群发现
用来发现社交网络中三角形的个数(圈子),可以分析出哪些圈子更稳固,关系更紧密。用来衡量社群耦合关系的紧密程度。一个人的社交圈子里面,三角形个数越多,说明他的社交关系越稳固、紧密。像微信、微博、Facebook、Twitter等社交网站,常用到的的社交分析算法就是社群发现。
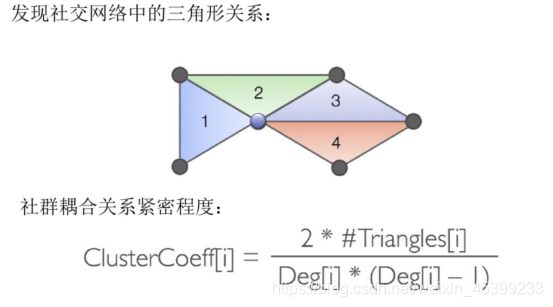
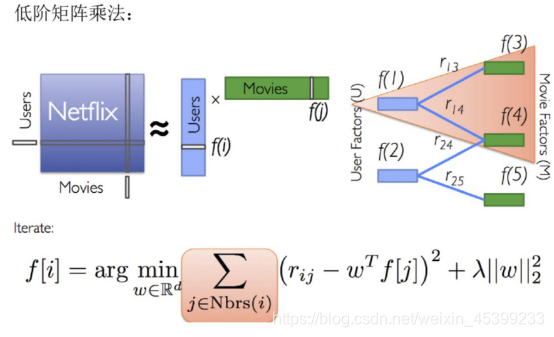
4、推荐算法ALS和SVD++
ALS是一个矩阵分解算法,比如购物网站要给用户进行商品推荐一些推荐,就需要知道哪些用户对哪些商品感兴趣,这时,可以通过ALS构建一个矩阵图,在这个矩阵图里,假如被用户购买过的商品是1,没有被用户购买过的是0,这时我们需要计算的就是有哪些0有可能会变成1。
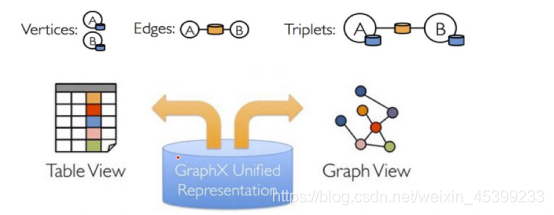
四、GraphX数据抽象RDPG
Spark的每一个模块,都有自己的抽象数据结构(如下图),GraphX的核心抽象是弹性分布式属性图(resilient distribute property graph),一种点和边都带有属性的有向多重图。

Spark关键抽象如下图:
属性图扩展了Spark RDD的抽象,它同时拥有Table和Graph两种视图,而只需一种物理存储,这两种操作符都有自己独有的操作符,从而获得灵活的操作和较高的执行效率。
GraphX支持并行边的能力简化了建模场景,相同的顶点可能存在多种关系(例如co-worker和friend)。 每个顶点用一个唯一的64位长的标识符(VertexID)作为key。GraphX并没有对顶点标识强加任何排序。同样,边拥有相应的源和目的顶点标识符。
顶点以VertexId的顶点ID和属性VD作为参数类型,边以Edge(ED)作为参数类型,属性图以vertex(VD)和edge(ED)类型作为参数类型,这些类型分别是顶点和边相关联的对象的类型。

五、图基本结构
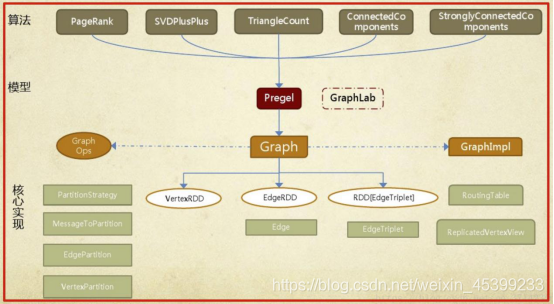
GraphX的整体架构可以分为三个部分:
实现层:Graph类是图计算的核心类,内部含有VertexRDD、EdgeRDD和RDD[EdgeTriplet]引用。GraphImpl是Graph类的子类,实现了图操作。
接口层:在底层RDD的基础之上实现Pragel模型,BSP模式的计算接口。
算法层:基于Pregel接口实现了常用的图算法。包含:PageRank、SVDPlusPlus、TriangleCount、ConnectedComponents、StronglyConnectedConponents等算法。
在图的基本架构基础上我们进一步分析构成弹性分布式属性图的特性:
RDPG和RDD一样,属性图是不可变的、分布式的、容错的。图的值或者结构的改变需要生成一个新的图来实现。注意,原始图中不受影响的部分都可以在新图中重用,用来减少存储的成本。 执行者使用一系列顶点分区方法来对图进行分区。如RDD一样,图的每个分区可以在发生故障的情况下被重新创建在不同的机器上。
逻辑上,属性图对应于一对类型化的集合(RDD),这个集合包含每一个顶点和边的属性。因此,图的类中包含访问图中顶点和边的成员变量。
class Graph 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1624
1624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











