






CDH6.3.1 成功搭建运行(包能搭起来)
资源链接
此资源为优快云博主分享,博主主页 一位编程的学习者
链接:https://pan.baidu.com/s/1eP4OVQ0u4qgwsmMoW1KCDw?pwd=3ane
提取码:3ane
另一个文件资源,此资源为知乎博主分享,博主主页 随我逐流:
链接:https://pan.baidu.com/s/18XOpQBLXUyI3ajsueBzoOA?pwd=aner
提取码:aner
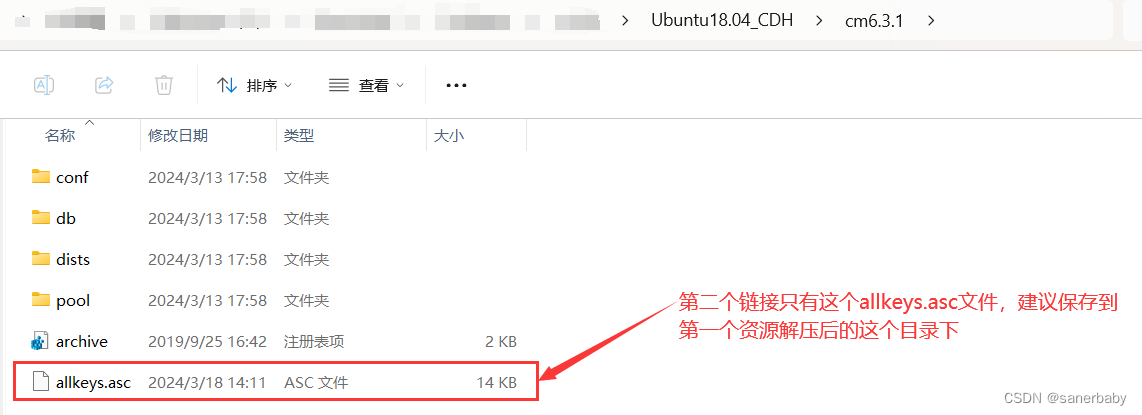
至此,最重要的文件、能保证我们一定能搭建起集群的文件就都下载好了。约等于已经搭建成功了,朋友们可以放心了。
准备虚拟机,配置虚拟机环境
本来准备在标题加上Ubuntu环境下CDH搭建的,但是担心有的朋友看见是Ubuntu环境的就直接不点进来看了,实际上Ubuntu搭建一样可以的,我也是在CentOS7环境下搭建几次失败后才选择的Ubuntu,原因很简单,CentOS7下跟着几位博主的教程都没搭建起来,所以放弃使用CentOS7环境。
下载ISO镜像文件
可以在阿里云下载这个镜像文件,一定要是Ubuntu18.04,别的版本我没有测试过。

新建虚拟机
我使用的是Vmware,操作流程就是:
新建虚拟机–>自定义(高级)–>…–>稍后安装操纵系统–>版本选择Ubuntu64位–>设置虚拟机名称以及安装位置–>设置处理器数量和内核数量(这个设置建议大家根据自己windows的配置去自行查验设置)–>虚拟机的内存设置为4g–>使用桥接网络–>…–>创建新虚拟磁盘–>最大磁盘大小设置为40g(将虚拟磁盘拆分成多个文件)–>…基本就完事了
2024年3月29日更新:40个g不够用,建议master至少分60个g,slaver节点分50个g,如果已经分配完40个g的朋友,可以参考这篇文章对虚拟机进行扩容,我是在集群都在运行的状态下进行扩容的,目测暂时没啥问题
这里说一下我的内核数量设置:根据我的物理机是8核的,所以我的设置由上到下依次为1、2。使得虚拟机得最大内核是2,大家机器配置高的可看情况多给点。

然后编辑虚拟机设置–>在CD/DVD那选择使用ISO映像文件,然后选择我们下载得ISO文件即可。
然后就是开机点点点了。到这里虚拟机就算新建完毕了。
虚拟机设置
Ubuntu的环境使用起来还是挺不习惯的,我们如果想使用ifconfig、vim这样的命令的话,我们需要跟据提示安装相应的插件。
说明:我们配置的是一台虚拟机,而我们最终的集群是3台虚拟机,我们所要对这一台虚拟机配置的应该是3台虚拟机都需要有的部分,其实就只是MySQL和cm相关插件不需要安装,然后配置完这台主机后,克隆两台虚拟机(完整克隆);克隆之后需要对虚拟机内存做调整,主节点master的内存设置为16g(如果物理界的内存是32g的情况下),其他两个从节点还是原来的4g。
大伙还是看第一个资源的分享者的文章去配置虚拟机的相关事项,有一步需要大家调整一下
CDH6.3.2安装部署(Ubuntu1804)(附安装包)
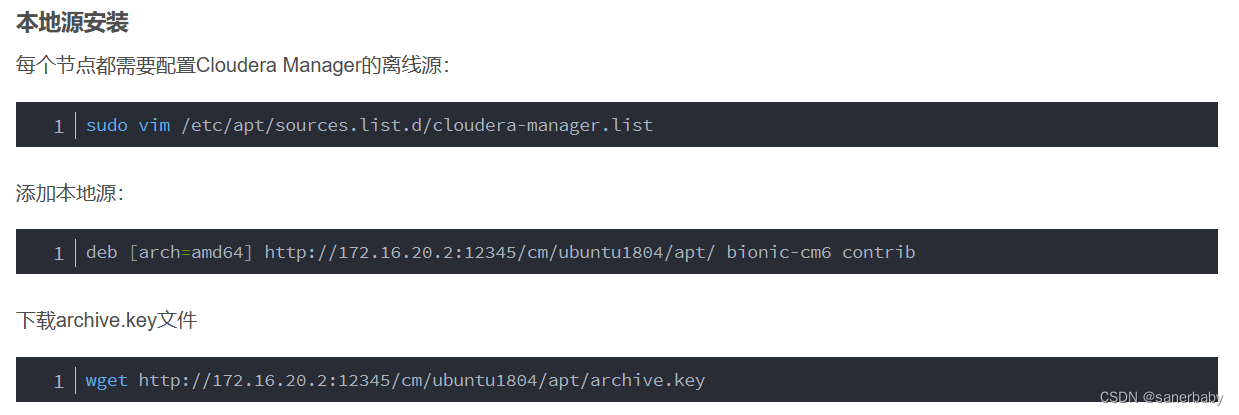
就是这里,这里的话,大家可以参照我的配置:
deb [arch=amd64] file:///etc/apt/sources.list.d/cm6.3.1/ bionic-cm6 contrib
/etc/apt/sources.list.d/cm6.3.1/ 这个是我的本地文件目录,大家可以和我一样或者自定义本地文件的目录,cm6.3.1这个文件夹就是第一个资源解压打开后的唯一一个文件夹,直接传输到虚拟机的相应目录或者传输到一个能传输的目录然后cp 即可。
然后我们就不用尽心wget /…/archive.key了,而是直接到archive.key所在目录执行
apt-key add archive.key
apt-get update -y
此外,原博主对各主机间互信(免密登录)、关闭防火墙、关闭selinux、配置swap的部分是没有展示在文章中的,大伙可以自行做一下。
其他的所有操作按第一个资源分享者的博文操作即可,按博文操作至博文结束,过程中可能会遇到一些我没有提到的小问题,大家耐心解决,都不影响大体。
至此,我们就已经在每个节点上安装了CDH所需要的插件,接下来是非常重要的部分。
网页搭建CDH
-
进入登录页面,登录,用户名密码都是admin
http://ip_address:7180/cmf/login -
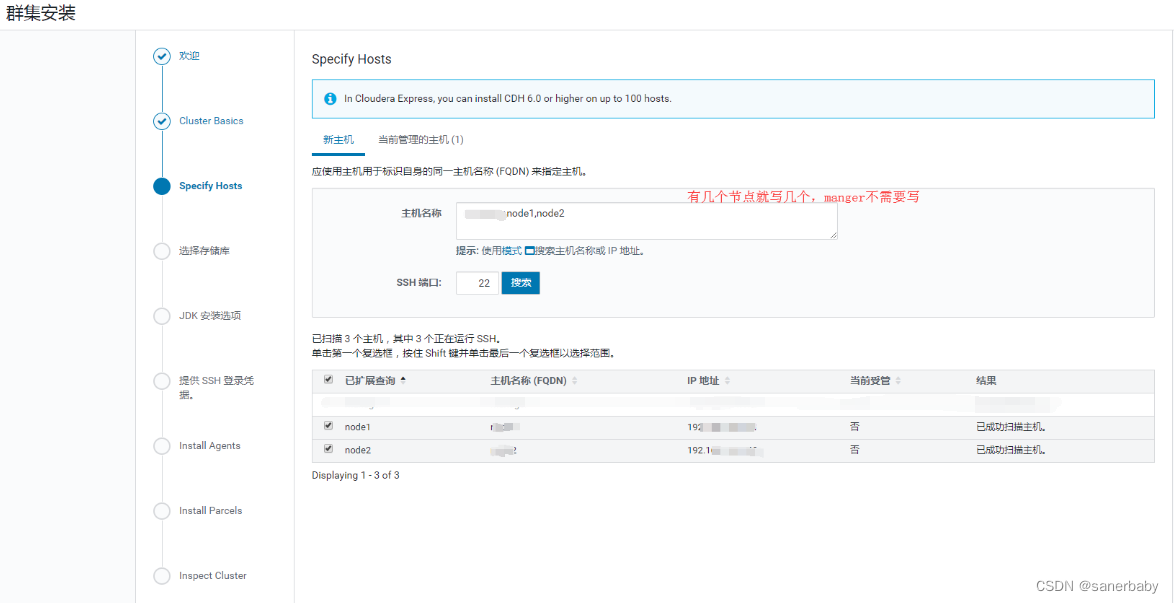
一直继续到Specify Hosts这一步,我们在新主机那个选项界面输入两个从节点的ip地址或主机名,中间用逗号(英文输入法下)分隔,然后搜索到两台从几点主机,在这两个主机前勾选上即可。
-
自定义存储库这部分
大家可以看到我的目录结构是这样的
root@h1:/etc/apt/sources.list.d# ls
cloudera-manager.list cm6.3.1
然后我们进到cm6.3.1这个目录
root@h1:/etc/apt/sources.list.d# cd cm6.3.1/
root@h1:/etc/apt/sources.list.d/cm6.3.1# ls
allkeys.asc archive.key conf db dists pool
然后我们进行如下操作:
# 第一步:安装Supervisor
apt-get install supervisor
# 第二步:
vim /etc/supervisor/conf.d/simple-http.conf
## 在文件中添加以下内容:
## 注意端口8900是自定义的;directory目录要根据实际的文件目录
[program:simple-http]
command=/usr/bin/python -m SimpleHTTPServer 8900
directory=/etc/apt/sources.list.d/cm6.3.1
user=yourusername
autostart=true
autorestart=true
# 第三步:重新加载Supervisor配置并启动服务
supervisorctl reread
supervisorctl update
supervisorctl start simple-http
# 第四步:设置开机自启
systemctl enable supervisor
我们这个时候可以在自定义存储库添加对应url:http://192.168.2.167:8900/
直接这样就可以,注意这样一定是在cm6.3.1下执行上述操作才是这样的url。我们可以在网页进入这个url看一下,点任意文件发现可以正常下载,证明配置成功。

- 注意不装JDK,因为我们已经离线装过了。
- 再往后面的操作,我推荐大家一篇博文,我自己搭建安装以及写这篇博文部分也都是参考了这篇博文。
以上过程就是整体的操作流程了,操作过程中可能避免不了出现这样那样的小小的插曲,而小插曲都是容易解决的,尽早地出现问题对于安装部署CDH来说,可能是一件好事。
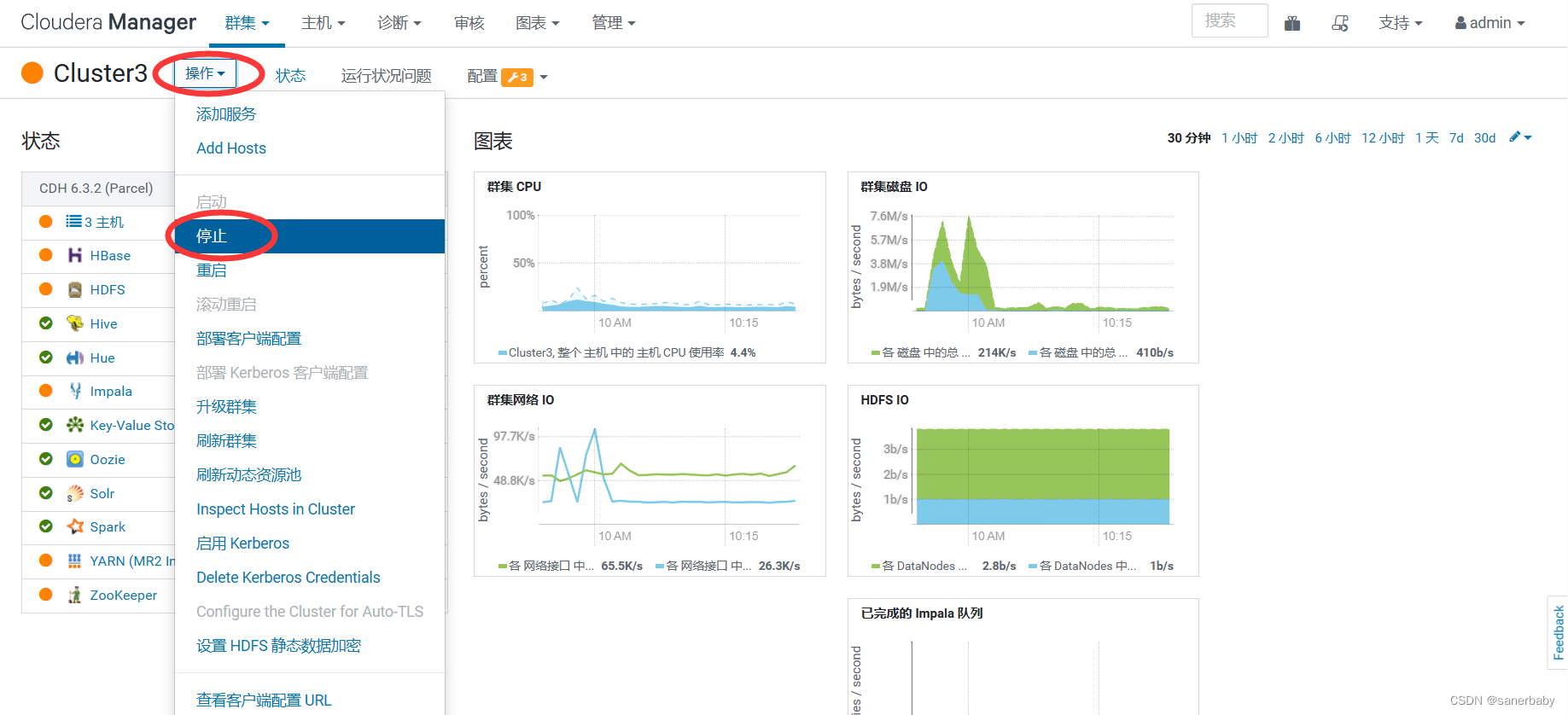
2024年3月29日更新:对于首次使用和部署CDH的朋友,关闭时在管理页面进行各个服务的关闭,再次启动时同样在这个页面进行操作
最后,祝大家身体健康,工作愉快~
以上部分就是搭建部署CDH的全部了,以下部分均不属于搭建部署CDH的范围
想到哪儿我就记录到哪儿
DBeaver连接hive
在搭建好的CDH的主节,直接控制台输入hive就行
期间可能会报一个错,需要手动修改一下一个目录的权限,这里不聊这个。
- hive启动后,我们随便建个库建个表然后向表里导入数据
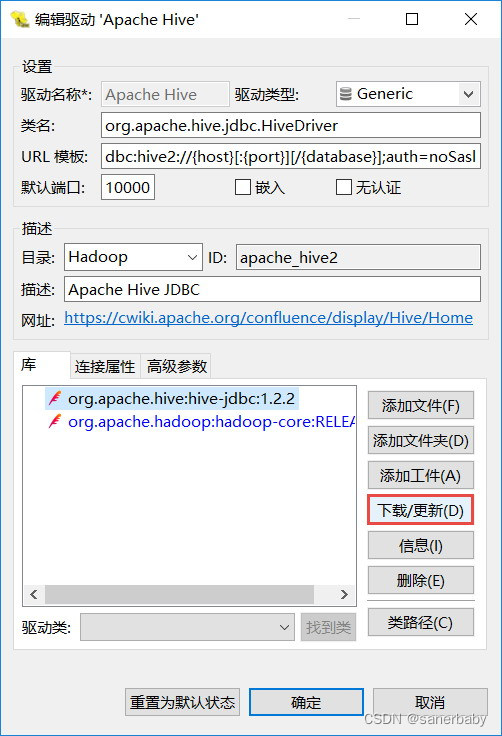
- 打开DBeaver,文件–>新建–>数据库连接–>选择Apache Hive–>"主要"这里的用户名密码就是在网页页面部署CDH时所填写的hive的用户和密码(如果不记得了可以试一下hive,hive123456)–>编辑驱动设置–>url模板长这样:jdbc:hive2://192.168.a.bcd:10000/sales,即jdbc:hive2://ip地址:端口/数据库名–>在"库"这部分,选择添加文件而不是添加工件,我们手动去下载hadoop-core-1.2.1.jar和hive-jdbc-2.1.1.jar这两个文件,然后添加进去–>确定–>完成
- 这时候双击一下左边刚刚新建的连接,有绿色的勾还不能完全代表可以正常使用,需要在我们的数据库做一个sql编辑器,查询一下表中的数据,如果刚刚新建的连接有绿色的勾但是查询时提示/user这个目录权限相关的提示,很有可能是用户名密码不对,需要你找到正确的用户名和密码然后编辑这个连接,然后再重试那条sql,直到能查询出数据。
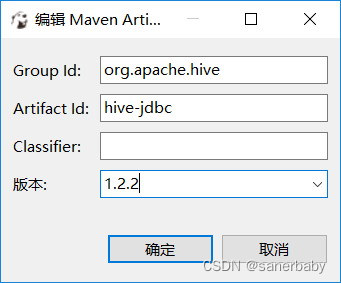
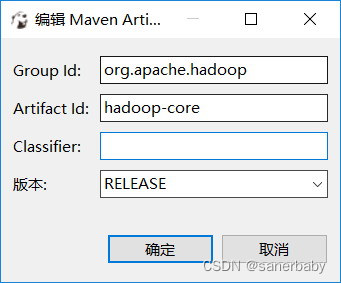
这里选择添加文件而不是添加工件的原因,选择添加工件有问题,会提示访问maven仓库的一些错误、还有网络错误,我是没解决的,如果有想尝试的,可以参照如下方式尝试
选择添加工件,分别添加如下两个(版本要根据自己的hive的版本,我的hive的版本是2.1.2,hadoop的hadoop-core的版本是1.2.1,下面3个图都是偷的)
然后就是下载更新,可以的话就是可以,不可以的话我建议还是直接自己去下载这两个文件来的舒服些。
以上就是使用DBeaver连接Hive的简单记录,再次祝大家身体健康,工作愉快~
Power Bi连接Hive
what can i say~
tableau连接hive
tableau连接hive,花钱的买的不算,根据众多网友反馈,2020版本的pojie版有不显示可视化图表的问题,2019版本的pojie版本的有不显示地图的问题,听说是不用地图就选2019,用地图就选2020~

-------使用tableau连接hive就直接去cloudera的官网去下载一个hive的ODBC驱动即可,下载之后就有各种博文教程辣
ps:cloudera官网下载文件要登录才行,新用户注册可能因为加载不出来人机验证页面而注册不了,就靠大伙各自的手段辣~
Power Bi连接hive
小太阳的数据分析笔记
看这个就行。
为什么看这个呢,因为我从官网下载的一个Hive的ODBC驱动版本好像不大行,能连接数据库能显示表但是一点进去表就报错,谢特!然后我下载了这个博主的文件,用了这个之后就不会报错能正常使用了。

安装zeppelin
安装zeppelin这部分有很多博主都有文章进行讲解,这里需注意,如果博主的博文中没有外部rar的资源链接或根本没提到外部rar(commons-lang-xxx.jar)的,大家需要去下载一下这个文件,注意下载jar文件,这个文件要放到/xx/xxx/zeppelin/interpreter/jdbc/这个目录下。
如果缺少这个文件,在执行hive sql时,会有如下提示:
java.lang.NoClassDefFoundError: org/apache/commons/lang/StringUtils
at org.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:175)
at org.apache.hive.jdbc.HiveDriver.connect(HiveDriver.java:107)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:208)
at org.apache.commons.dbcp2.DriverManagerConnectionFactory.createConnection(DriverManagerConnectionFactory.java:79)
at org.apache.commons.dbcp2.PoolableConnectionFactory.makeObject(PoolableConnectionFactory.java:205)
at org.apache.commons.pool2.impl.GenericObjectPool.create(GenericObjectPool.java:836)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:434)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:361)
at org.apache.commons.dbcp2.PoolingDriver.connect(PoolingDriver.java:129)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:270)
at org.apache.zeppelin.jdbc.JDBCInterpreter.getConnectionFromPool(JDBCInterpreter.java:518)
at org.apache.zeppelin.jdbc.JDBCInterpreter.getConnection(JDBCInterpreter.java:543)
at org.apache.zeppelin.jdbc.JDBCInterpreter.executeSql(JDBCInterpreter.java:751)
at org.apache.zeppelin.jdbc.JDBCInterpreter.internalInterpret(JDBCInterpreter.java:939)
at org.apache.zeppelin.interpreter.AbstractInterpreter.interpret(AbstractInterpreter.java:55)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:110)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:860)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:752)
at org.apache.zeppelin.scheduler.Job.run(Job.java:172)
at org.apache.zeppelin.scheduler.AbstractScheduler.runJob(AbstractScheduler.java:132)
at org.apache.zeppelin.scheduler.ParallelScheduler.lambda$runJobInScheduler$0(ParallelScheduler.java:46)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.ClassNotFoundException: org.apache.commons.lang.StringUtils
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 26 more
如果大家真的遇到了如上报错,别执着,就直接下载那个commons-lang-xxx.jar文件放到指定位置,然后重启zeppelin即可。(我安装的是0.10.1版本)
=====================================================
我呀,我也想把我的芬芳,留在大地上,告诉后来的人们,告诉他们,我曾经来过这里。
—— 刘猛《最后一颗子弹留给我》

















 2611
2611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









