






 文章介绍了对比学习的一种形式——预测编码,其目标是通过预测未来或缺失的内容来学习特征表示。这种方法利用互信息最大化来捕获输入数据的共享信息,特别是在图像和语言领域。文中提出的ContrastivePredictiveCoding(CPC)模型通过非线性编码器和自回归模型来估计输入序列的未来内容,优化InfoNCE损失以最大化正样本对之间的互信息,同时最小化负样本对之间的互信息。
文章介绍了对比学习的一种形式——预测编码,其目标是通过预测未来或缺失的内容来学习特征表示。这种方法利用互信息最大化来捕获输入数据的共享信息,特别是在图像和语言领域。文中提出的ContrastivePredictiveCoding(CPC)模型通过非线性编码器和自回归模型来估计输入序列的未来内容,优化InfoNCE损失以最大化正样本对之间的互信息,同时最小化负样本对之间的互信息。
对比学习
Representation Learning with Contrastive Predictive Coding
Goal
关于无监督最普遍的策略就是预测未来/缺失/内容,预测编码便是在信号处理中用于数据压缩的经典方法。该方法在图像、语言领域表现突出,作者认为这是因为当我们预测相关值的上下文时经常有条件地依赖于共享的特征信息。通过将其当作预测问题,我们就能自动推断出最有利于表征学习的特征。
作者提到学习到的特征应该能够编码高维信号不同部分的潜在共享信息。随着时间步越长,预测步骤越多,共享的潜在信息就会越少,要建模更全局的结构。在这之中,慢性特征或成为我们的关注对象。高水平表达和原始传感信号之间的一个主要区别在于它们变动的时间尺度。因此一个缓慢变化的表示被认为比一个快速变化的表示具有更高的抽象特征。
重构所有细节的生成式模型计算量太大,耗费大量资源建模数据x的关系又忽略了上下文c,因此直接建模
p
(
x
/
c
)
p(x/c)
p(x/c)对于提取x和c之间的共享信息并不是最优解。在预测未来信息时,作者将目标x(未来)和上下文c(当前)编码成紧凑的分布式向量表示,最大限度地保留了原始信号x和c的互信息,定义为:
I
(
x
;
c
)
=
∑
x
,
c
p
(
x
,
c
)
l
o
g
p
(
x
∣
c
)
p
(
x
)
I(x;c)=\sum_{x,c}p(x,c)log\frac{p(x|c)}{p(x)} \qquad
I(x;c)=x,c∑p(x,c)logp(x)p(x∣c)
互信息可以表示两个随机变量之间的相互依赖关系,从下面公式可以看出,X与Y的互信息就是观察到Y之后,X的不确定性的减少,也就是给定Y之后X信息量的减少,互信息可以描述随机变量之间高阶的相关程度,值越大,表示相互依赖性越强。
I
(
X
;
Y
)
=
H
(
X
)
−
H
(
X
∣
Y
)
I(X;Y)=H(X)-H(X|Y)
I(X;Y)=H(X)−H(X∣Y)
这样就通过最大化编码后的表示之间的互信息,提取输入共同具有的潜在变量。
Method
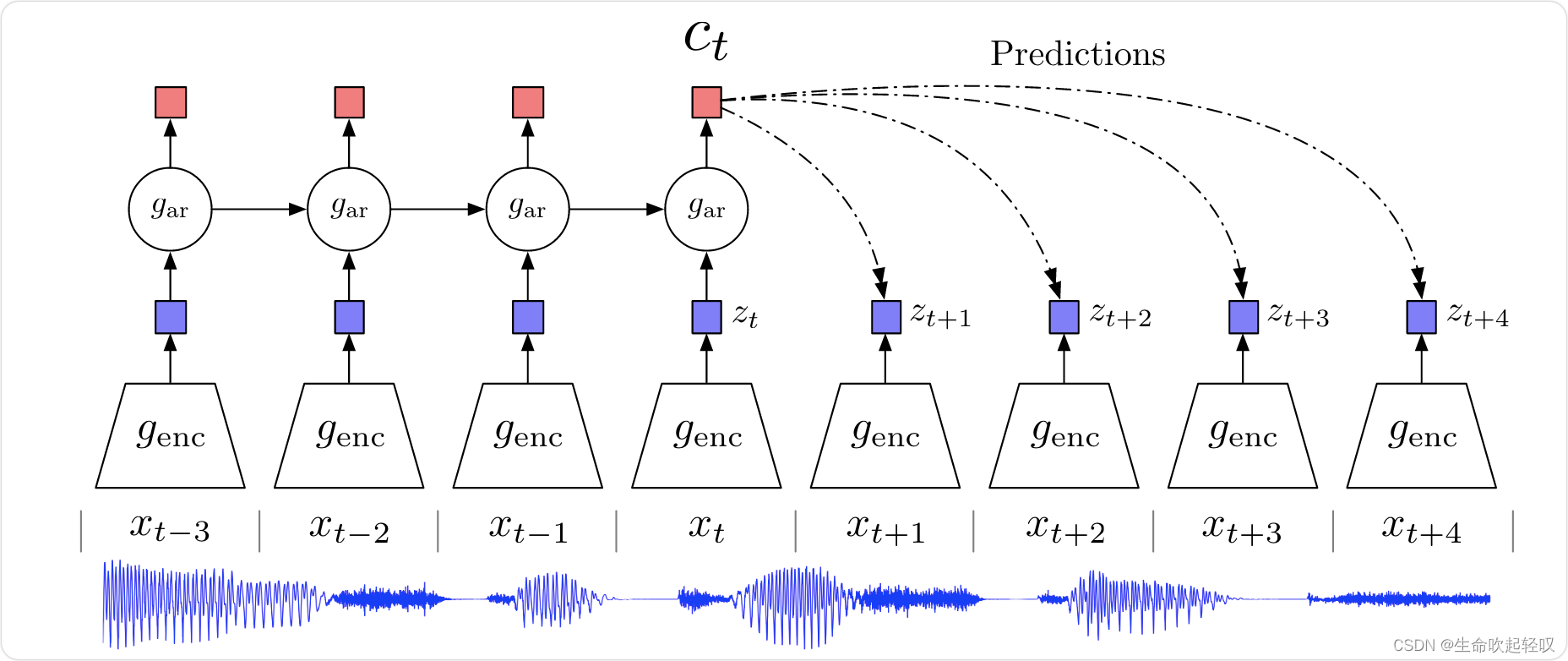
Contrastive Predictive Coding
如上图所示,一个非线性编码器
g
e
n
c
g_{enc}
genc将输入序列映射成特征序列
z
t
=
g
e
n
c
(
z
≤
t
)
z_t=g_{enc}(z_{\leq t})
zt=genc(z≤t),之后一个自回归模型
g
a
r
g_{ar}
gar总结所有
z
≤
t
z_{\leq t}
z≤t,生成一个内容特征表示
c
t
=
g
a
r
(
z
≤
t
)
c_t=g_{ar}(z_{\leq t})
ct=gar(z≤t),这篇工作并不直接通过生成式模型
p
k
(
x
t
+
k
∣
c
t
)
p_k(x_{t+k}|c_t)
pk(xt+k∣ct)预测
x
t
+
k
x_{t+k}
xt+k,而是建模密度比来保存
x
t
+
k
x_{t+k}
xt+k和
c
t
c_t
ct的互信息:
f
k
(
x
t
+
k
,
c
t
)
=
e
x
p
(
z
t
+
k
T
W
k
c
t
)
f_k(x_{t+k},c_t)=exp(z^T_{t+k}W_kc_t)
fk(xt+k,ct)=exp(zt+kTWkct)
其中
f
k
(
x
t
+
k
,
c
t
)
f_k(x_{t+k},c_t)
fk(xt+k,ct)成比例与
p
(
x
t
+
k
∣
c
t
)
p
(
x
t
+
k
)
\frac{p(x_{t+k}|c_t)}{p(x_{t+k})}
p(xt+k)p(xt+k∣ct)。
W
k
c
t
W_kc_t
Wkct用于每一步k的不同
W
k
W_k
Wk的预测。这样利用密度比,通过编码器推断
z
t
+
k
z_{t+k}
zt+k,可以将模型从高维分布
x
t
+
k
x_{t+k}
xt+k中抽离出来。
InfoNCE Loss and Mutual Information Estimation
编码器和自回归模型共同在infoNEC损失中优化,给一个采样集 X = { x 1 , . . . , x N } X=\{x_1,...,x_N\} X={x1,...,xN}包含N个随机样本,其中一个来自 p ( x t + k , c t ) p(x_{t+k},c_t) p(xt+k,ct)的正样本和 N − 1 N-1 N−1个来自建议分布 p ( x t + k ) p(x_{t+k}) p(xt+k)的负样本,作者构建目标函数(以softmax函数为基础的关于经验分布的期望似然):
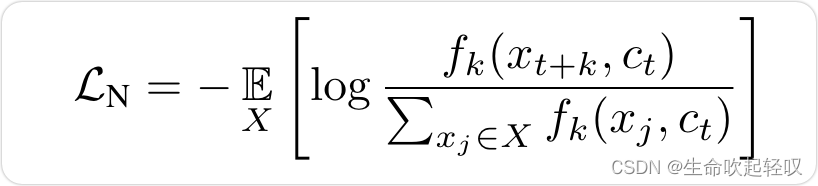
从另一个角度看,损失函数实际上也可以看作是一个二分类交叉熵损失,其中X是一组样本,其中有一对正样本对和N-1对负样本对,分子视为式计算正样本对之间的相似度,分母视为计算所有样本对之间的相似度。
为了优化该损失,希望分子越大,分母越小,也就复合了对x和c之间互信息最大化的要求,即正样本对之间的互信息更大,负样本对之间的互信息更小。
参考链接:
- https://zhuanlan.zhihu.com/p/471018370
- https://blog.youkuaiyun.com/weixin_40957452/article/details/118000679

















 5552
5552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









