







一个简单的爬虫:
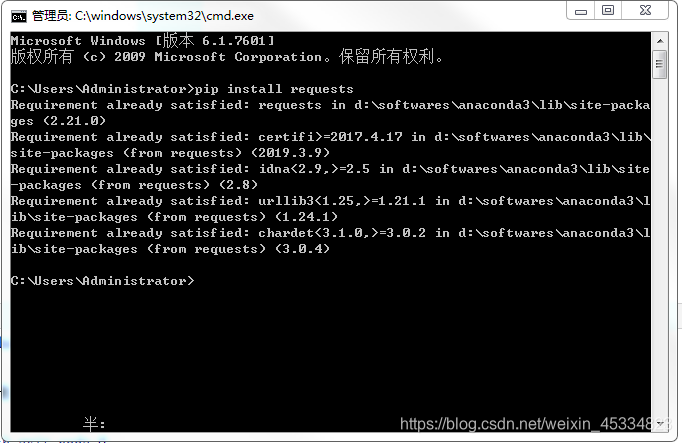
1.安装request
pip install requests
2.测试是否安装成功
输入python
import requests
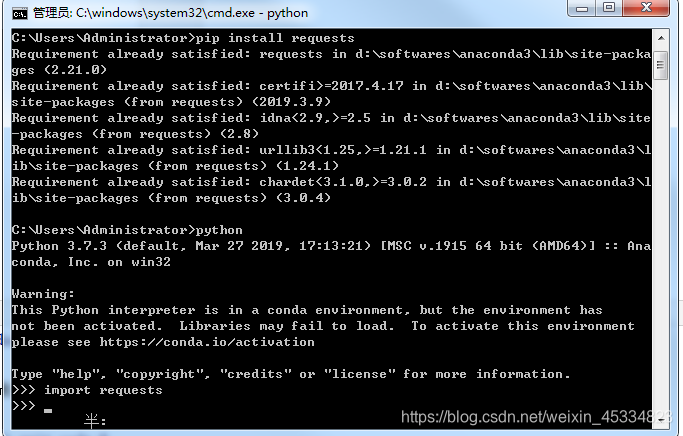
不报错就是安装成功
3.新建项目
4.使用requests请求网页
import requests #引入requests包
resp=requests.get('https://www.baidu.com') #请求百度首页
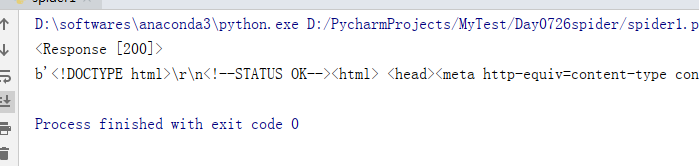
print(resp) #打印请求结果的状态码(正常的状态码是200,异常状态码就很多了,比如404(找不到网页)、301(重定向)等。
print(resp.content) #打印请求到的网页源码
请求正常:
4.如何用python解析网页源码
网页源码解析器 BeautifulSoup:但是使用bs4还需要安装另一个类库lxml,用来代替bs4默认的解析器。之所以这样做,是因为默认的那个实在太慢了,换用了lxml后,可以大幅度提升解析速度。
安装:命令行中输入以下指令并回车,安装bs4:
Windows环境下使用pip install安装lxml库:

测试是否安装成功:
import bs4
import lxml
没有报错,安装成功
使用BeautifulSoup+lxml解析网页源码:
import requests #引入requests包
from bs4 import BeautifulSoup
resp=requests.get('https://www.baidu.com') #请求百度首页
print(resp) #打印请求结果的状态码(正常的状态码是200,异常状态码就很多了,比如404(找不到网页)、301(重定向)等。
print(resp.content) #打印请求到的网页源码
bsobj=BeautifulSoup(resp.content,'lxml') # 将网页源码构造成BeautifulSoup对象,方便操作
#将网页的源码转化成了BeautifulSoup的对象,这样我们可以向操作DOM模型类似地去操作它。
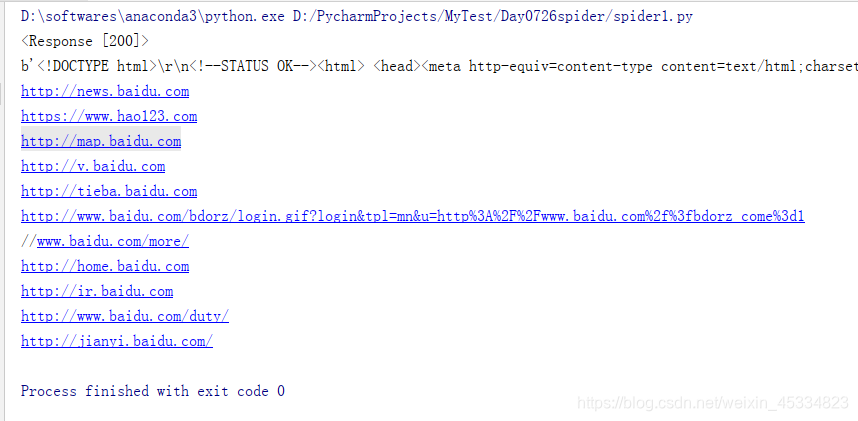
a_list=bsobj.find_all('a') #获取网页中所有a标签对象
for a in a_list:
print(a.get('href')) #打印a标签对象的href属性,即这个对象指向的链接地址
5.简单的保存数据的方法
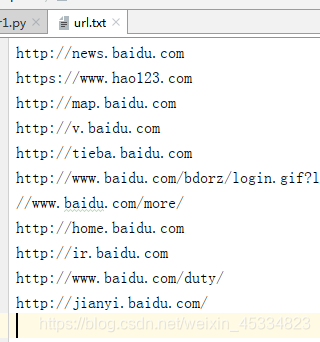
将刚才提取出来的链接保存到一个名称为url.txt的文本里面去,将上面的代码稍作修改。
import requests #引入requests包
from bs4 import BeautifulSoup
resp=requests.get('https://www.baidu.com') #请求百度首页
print(resp) #打印请求结果的状态码(正常的状态码是200,异常状态码就很多了,比如404(找不到网页)、301(重定向)等。
print(resp.content) #打印请求到的网页源码
bsobj=BeautifulSoup(resp.content,'lxml') # 将网页源码构造成BeautifulSoup对象,方便操作
#将网页的源码转化成了BeautifulSoup的对象,这样我们可以向操作DOM模型类似地去操作它。
a_list=bsobj.find_all('a') #获取网页中所有a标签对象
for a in a_list:
print(a.get('href')) #打印a标签对象的href属性,即这个对象指向的链接地址
text='' #创建一个空字符串
for a in a_list:
href=a.get('href') #获取a标签对象的href属性,即这个对象指向的链接地址
text+=href+'\n' #加入到字符串中,并换行
with open('url.txt','w') as f: #以写的方式打开一个url.txt
f.write(text)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









