







 本文介绍了在导入和处理IMDB数据集时遇到的两个问题:一是数据集的本地下载和加载方法,二是训练模型时出现的KeyError。针对问题1,通过输入特定代码可以解决;对于问题2,报错'accuracy' KeyError,只需将'accuracy'替换为'acc'即可消除错误。
本文介绍了在导入和处理IMDB数据集时遇到的两个问题:一是数据集的本地下载和加载方法,二是训练模型时出现的KeyError。针对问题1,通过输入特定代码可以解决;对于问题2,报错'accuracy' KeyError,只需将'accuracy'替换为'acc'即可消除错误。
还是采用本地下载的方法:
数据集网盘地址:链接:https://pan.baidu.com/s/1USzPMj413kK_Cg7E5fwstw
提取码:3hus
并添加到指定的文件夹下,比如我的地址是:C:\Users\DELL.keras\datasets
之后,在jupyter notebook(我用的是这个,当然可以其他)加载数据集
问题1:
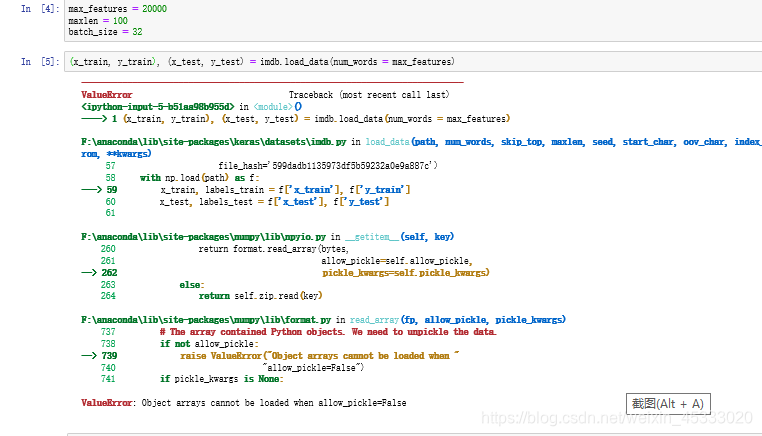 解决方法:
解决方法:
import numpy as np
# save np.load
np_load_old = np.load
# modify the default parameters of np.load
np.load = lambda *a,**k: np_load_old(*a, allow_pickle=True, **k)
# call load_data with allow_pickle implicitly set to true
(x_train, y_train), (x_test, y_test)= imdb.load_data(num_words= max_features)
# restore np.load for future normal usage
np.load = np_load_old
输入以上代码即可解决。
问题2:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









