






最近想在4567kp.com网站上爬取下载“穿普拉达的女王”电影到本地。在写代码之前,我先做了如下的分析:
1.确定该电影的资源所在地,即src_url
2.通过F12抓包分析如何可以获取并下载视频资源
在确定电影资源的src_url时,我使用的是F12中的element来定位视频资源,使用element的原因是因为element的数据比较全,同时可以通过鼠标精准定位视频所在的具体标签。如果通过抓包的话,包的数量多并分散,不方便定位;另外,服务器返回的数据对资源进行处理的可能性大,通过关键字筛选不一定能筛选出想要的url。
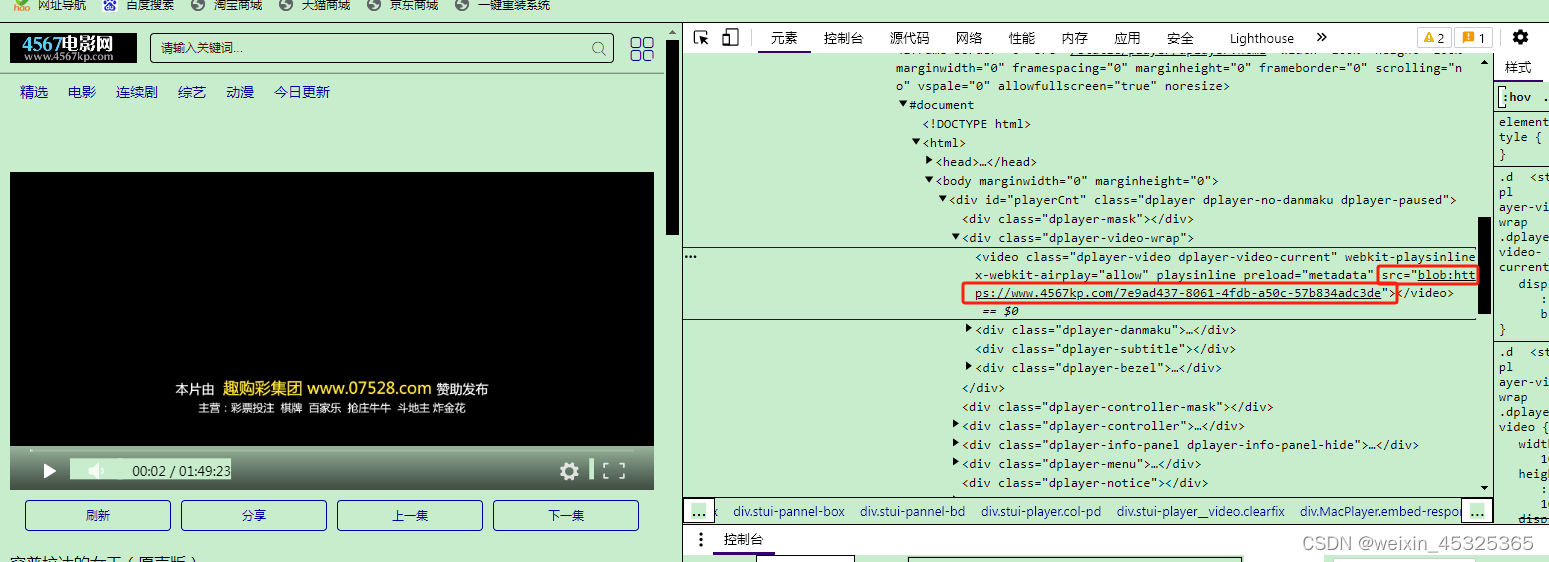
通过F12的element分析,该视频的src="blob:https://www.4567kp.com/7e9ad437-8061-4fdb-a50c-57b834adc3de"。使用该blob链接访问提示不存在。对于blob我也是第一次接触,因而在百度上查询blob的资料,发现blob的url视频一般都是将视频切割成N个ts短视频,它的好处是提高效率,让用户观看更流畅。而切割成N个TS的短视频的url地址都存放在.m3u8中。
获取这个信息后思路打开,m3u8的url是关键,有承上启下的效果。因此现在需要解决2个问题:
1.在起始的url(穿普拉达的女王(原声版)免费在线观看完整版 - 剧情片 - 4567电影网)返回中获取m3u8的url。
2.请求m3u8的url获取ts视频的链接并下载。
解决第一个问题,我使用了正则表达式将起始url返回的信息中获取m3u8的url,获取的url格式为https:\/\/hnzy.bfvvs.com\/play\/Yer7N6aO\/index.m3u8。然后再使用split函数通过‘\’来对url做分割,然后再使用join函数进行联合。这样就获取了期望的m3u8的url(https://hnzy.bfvvs.com/play/Yer7N6aO/index.m3u8)。
获取m3u8的url后,使用requests.get()发送请求,从服务器返回如下的数据:
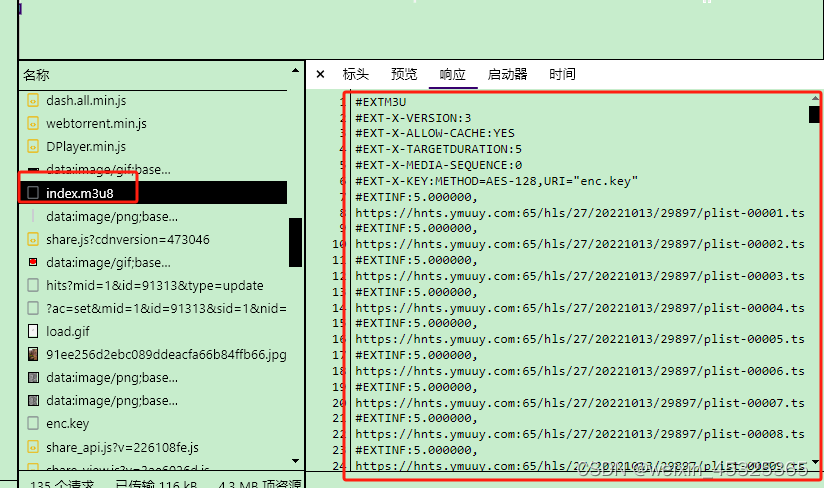
服务端返回的https的链接就是ts的资源链接,#EXT-X-KEY:METHOD=AES-128,URI="enc.key"说明ts视频加密,加密方式是AES-128,密钥是enc.key。现在遇到的难题是获取密钥并对视频解密。
获取密钥简单,可以直接使用正则表达式从服务端返回的URI中获取enc.key,然后拼接密钥的请求url(https://hnzy.bfvvs.com/play/Yer7N6aO/enc.key)。如何解密是一个难题,我在csdn查询了很多关于AES加密解密的资料,多次尝试都没有解决解密的问题。后来我总结了下解密不成功的原因是因为csdn给的解决方案很多和我遇到的情况不一致,他们有2个参数key和text。但是我遇到的问题是只有一个enc.key的URL。后来我转到B站搜索视频资料,我感觉肯定有类似我情况的解决方法和学习资料。果然在B站中找到了类似的案例,我使用相同的方法将解密解决。
解密的方法如下:
1.找到加密的js文件,可以通过包中的启动器查看到是在hls.min.js文件中。
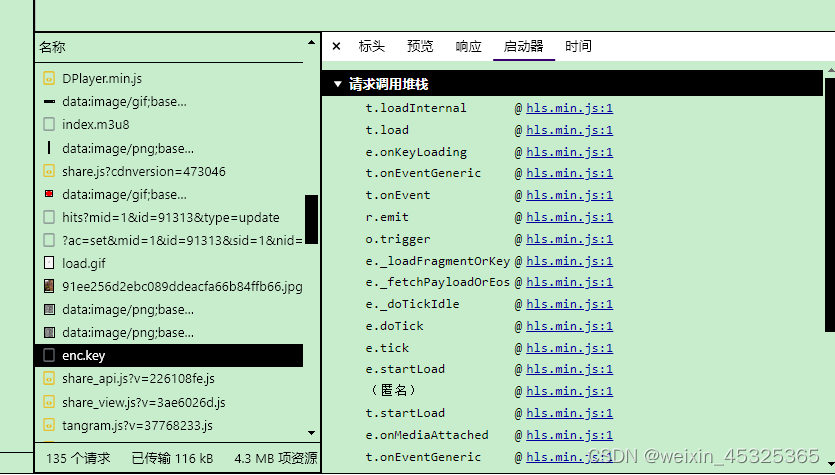
2.点击hls.min.js跳转到下面的页面,然后搜索AES关键字。在AES关键字中做debug调试。得到该加密是AES-128的加密方式,模式是MODE_CBC,没有IV。
3.写代码。
#密钥的地址
key_uri = 'https://hnzy.bfvvs.com/play/Yer7N6aO/enc.key'
#密钥url发送请求,获取返回的content内容
key_res = requests.get(key_uri,headers).content
#使用密钥和加密模式构建解密器,因为没有IV,所以构建解密器没有使用IV
aes = AES.new(key_res, AES.MODE_CBC)
#循环请求ts的链接
for new_url in url_list:
response = requests.get(new_url,headers).content
#使用创建的解码器对ts链接返回信息做解密
decryt_content = aes.decrypt(response)
解决了视频解密的问题,我们需要将下载的ts视频做合并操作,我使用的是ffmpeg。安装好ffmpeg后,创建一个ts视频地址文件(mergefile.txt),然后使用如下命令来合并:
ffmpeg -f concat -safe 0 -i mergefile.txt所在路径 -c copy 输出文件所在路径
总结:
这次电影的爬虫还是比较简单,遇到的难题主要是解密视频,其他都比较顺畅。总结下对m3u8视频爬取的过程。
1.从抓包中分析获取m3u8的链接url,这是我们期望的url。
2.从起始url返回信息中提取m3u8的url,同时对提取出的url做相应的处理,让其和期望的url相同。
3.发送m3u8 url的请求,从返回信息中提取全部的ts视频的url。同时查看ts视频是否为加密视频,如果是加密视频,需要定位到加密的js并debug加密的信息。需获取加密方式,密钥,加密模式等信息。
4.对ts视频的url发送请求,如果是加密的,需要对服务器返回的消息做解密操作然后保存。如果没有加密就直接保存。
5.使用ffmgrep合并所有的ts视频。

















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









