







 本文详细介绍了TensorFlow数据集(TFDS)的功能,包括ETL原理、数据切分、数据pipeline的构建以及性能提升方法。TFDS提供了一种灵活的方式与TensorFlow训练衔接,支持多种数据类型和来源。通过示例展示了如何使用TFDS进行数据预处理、数据切分,并讨论了如何通过缓存、并行API和运行顺序优化性能。此外,还涵盖了数据类型、数据源的处理,如CSV、TXT、TFRecord及图像数据。
本文详细介绍了TensorFlow数据集(TFDS)的功能,包括ETL原理、数据切分、数据pipeline的构建以及性能提升方法。TFDS提供了一种灵活的方式与TensorFlow训练衔接,支持多种数据类型和来源。通过示例展示了如何使用TFDS进行数据预处理、数据切分,并讨论了如何通过缓存、并行API和运行顺序优化性能。此外,还涵盖了数据类型、数据源的处理,如CSV、TXT、TFRecord及图像数据。
文章目录
一、概述
1.概述
从整体上看,数据可分为六种类型:图像、语言、结构化数据、视频、文本、翻译。目前来讲,对于在深度学习领域使用的数据有以下问题:
- 不同来源的数据格式差距很大
- 数据在下载之前不知道大小
- 需要转换数据使其易于可用
Tensorflow Dataset(TFDS)能够与Tensorflow训练衔接,使用灵活

Tensorflow Dataset(TFDS)能够与Tensorflow训练衔接,使用灵活,下面是TFDS中包含的一些数据集。

2.TFDS功能介绍
(1)ETL原理
数据pipeline基于ETL原理工作,ETL是指抽取(extract)、转换(transform)、加载(load)
# EXTRACT
dataset = tfds.load(name="mnist", split="train")
# TRANSFORM
dataset = dataset.shuffle(100)
dataset = dataset.repeat(NUM_EPOCHS)
dataset = dataset.map(lambda x:...)
dataset = dataset,batch(BATCH_SIZE)
# LOAD
for data in dataset.take(1):
image = data["image"].numpy().squeeze()
label = data["label"].numpy()
print("Label: {}".format(label))
plt.imshow(image, cmap=plt.cm.binary)
plt.show()
# 查看所有的数据集
print(tfds.list_builders())
(2)Datasetinfo
查看TFDS的元数据使用Datasetinfo类,在load函数中设置with_info为True,并用一个变量来接受info内容。
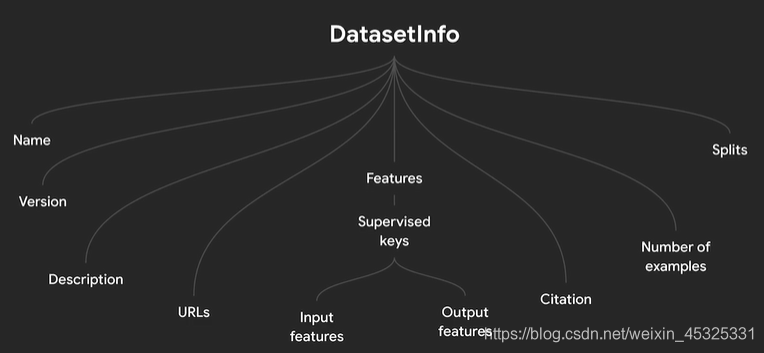
(3)load参数说明
-
数据集版本:数据集后面的三个数字分别表示主要版本、次要版本、补丁版本
minst = tfds.load("mnist:1.*.*") -
as_supervised:设为False返回字典表示的数据,设置为True返回元组表示的数据
-
split:根据创建者的设定,split参数可取的值包括tfds.Split.TRAIN、tfds.Split.VALIDATION、tfds.Split.TEST、tfds.Split.ALL。也可以使用一些自定义的split声明,具体内容见下一小节。
二、split和slice
1.Split API
Split API分为两种,第一种是Legacy tfds.Split API,第二种是Splits API(S3),后者为默认方法。
(1)Legacy API(不建议使用)
目前,Legacy API提供了许多灵活的交互方式以及某些复杂的切片操作。
-
Merging
使用加号来合并所需要的的部分all = tfds.Split.TRAIN + tfds.Split.TEST ds = tfds.load("mnist", split=all) -
Subsplit:将现有拆分进一步划分为更多部分
s1, s2, s3 = tfds.Split.TRAIN.subslpit(k=3) data1 = tfds.load("mnist", split=s1) data2 = tfds.load("mnist", split=s2) data3 = tfds.load("mnist", split=s3)加权分割
half, quarter1, quarter2 = tfds.Split.TRAIN.subslpit(weighted=[2,1,1]) -
Slicing:通过指定百分比切片来对数据集进行切片
first_30_percent = tfds.Split.TRAIN.subslpit(tfds.percent[:30]) -
Composition:将不同部分组合到一起
first_50_train = tfds.Split.TRAIN.subslpit(tfds.percent[:50]) split = first_50_train + tfds.Split.TEST data = tfds.load("mnist", split=split)
注意事项:
- 不能多次添加同一部分,例如Train+Train
- 不能在subsplit后再次subsplit
- 不能在已经merge的数据集中进行subsplit
(2)S3 API
使用字符串文字来决定拆分
split = "train+test"
split = "train[:300]"
split = "train[:30%]"
split = "train[-30%:]"
split = "train[-30%:]+train[:10%]"
使用之前确保数据集能够支持。
K折划分
val_ds = tfds.load('mnist:3.*.*', split=['train[{}%:{}%]'.format(k, k+20) for k in range(0,100,20)])
train_dx = tfds.load('mnist:3.*.*', split=['train[:{}%]+train[{}%:]'.format(k, k+20) for k in range(0,100,20)])
2.TFRecord
在使用tfds.load加载数据集后,会下载对应的数据文件,其格式为xxx_train.tfrecord-xxxxx。我们可以通过tfrecord来获取原始文件信息。
import tensorflow as tf
import tensorflow_datasets as tfds
data, info = tfds.load("mnist", with_info=True)
输出其中一个文件,可以看到以16进制存储的文件
filename="/root/tensorflow_datasets/mnist/3.0.0/mnist-test.tfrecord-00000-of-00001"
raw_dataset = tf.data.TFRecordDataset(filename)
for raw_record in raw_dataset.take(1):
print(repr(raw_record))
将16进制文件进行解码得到适当的格式
# Create a description of the features.
feature_description = {
'image': tf.io.FixedLenFeature([], dtype=tf.string),
'label': tf.io.FixedLenFeature([], dtype=tf.int64),
}
def _parse_function(example_proto):
# Parse the input `tf.Example` proto using the dictionary above.
return tf.io.parse_single_example(example_proto, feature_description)
parsed_dataset = raw_dataset.map(_parse_function)
for parsed_record in parsed_dataset.take(1):
print((parsed_record))
三、数据pipeline
一些经典的数据集都是以浮点型数据作为输入,但是在真实数据集中也包括了很多类别型变量或者一些用数字表示但是含义不是数字本身的,使用tf.data可以搭建简单可重用的复杂输入pipeline。而且,tf.data能够处理大规模数据、从不同的来源读取数据和进行复杂的转换。
1.tf.data.Dataset
tf.dataAPI使用tf.data.Dataset类来进行对数据的处理,例如:
-
从内存或其他数据源建立一个数据集,应使用
tf.data.Dataset.from_tensors()或者tf.data.Dataset.from_tensor_slices(),如果是以TFRecord方式存储,应使用tf.data.TFRecordDataset()dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1]) -
当有了数据集对象,可以通过其中的一些方法对数据集进行转换,常见的有
Dataset.map()和Dataset.batch()
2.数据类型
不同的数据有不同的数据类型,反应在数据集中则表现为不同的列有不同的属性,下面介绍不同种类的列:
-
数值型变量:最简单的数值型数据,参数可以用dtype指定类型,维度
age = tf.feature_column.numeric_column("age", dtype=tf.float64, shape=[5,10]) -
桶型(Bucketized)数据:数据分桶,例如小于18岁为青少年,18-50岁中年人,50岁以上老年人。首先将数据读取为数值型变量,之后设定边界将其进行数据分桶
age = tf.feature_column.numeric_column("age") age_buckets = tf.feature_column.bucketized_column(age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65]) -
类别型变量
# 桶化转变为类别型 identity_feature_column = feature_column.categorical_column_with_identity( key='my_feature', num_buckets=4) # 从词表构建类别型 thal = feature_column.categorical_column_with_vocabulary_list( 'thal', ['fixed', 'normal', 'reversible']) # 类别较多时利用哈希表构建类别型,注意hash_bucket_size要慎重选择 thal_hashed = feature_column.categorical_column_with_hash_bucket( 'thal', hash_bucket_size=1000) # 交叉特征可以结合两个特征,这种方法也是基于哈希表的 crossed_feature = feature_column.crossed_column([age_buckets, thal], hash_bucket_size=1000) -
Embedding变量:注意embedding维度
thal_embedding = feature_column.embedding_column(thal, dimension=8) demo(thal_embedding)
3.数据源
(1)numpy、pandas、images
读取numpy格式最常见的方法是tf.data.Dataset.from_tensor_slices
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
读取pandas文件
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file, index_col=None)
target = df.pop(['target'])
dataset = tf.data.Dataset.from_tensor_slices((df.values, target.values))
读取图像文件
flowers_root = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
flowers_root = pathlib.Path(flowers_root)
label_names = sorted(item.name for item in flowers_root.glob('*/') if item.is_dir())
(2)csv
csv文件是最常用的文件格式之一,可以使用tf.keras.utils.get_file或者pd.read_csv等方法读取
(3)txt、TFRecord
读取txt文件
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
dataset = tf.data.TextLineDataset(file_paths)
# 之后对文件进行解码
dataset.decode('utf-8')
读取TFRecord
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
(4)generator
常用于处理图像
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
ds = tf.data.Dataset.from_generator(
img_gen.flow_from_directory, args=[flowers],
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
四、性能
1.提升性能的方法
我们知道使用GPU、TPU能够加快训练速度,但是如果没有一个很好的数据pipeline,效率也可能非常低下,尤其在并行计算的时候。
下图是前文讲的ETL原理,先从本地或者远程抽取数据,在对数据进行各种形式的转换,最后将转换后的数据送入加速器中。
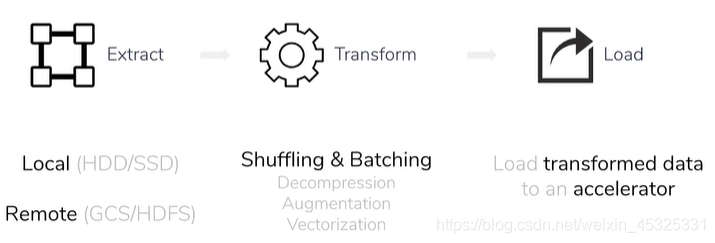
在上述过程中,预处理阶段在CPU上进行,训练阶段在GPU上进行,所以可以看出预处理阶段可能会成为训练速度的瓶颈。
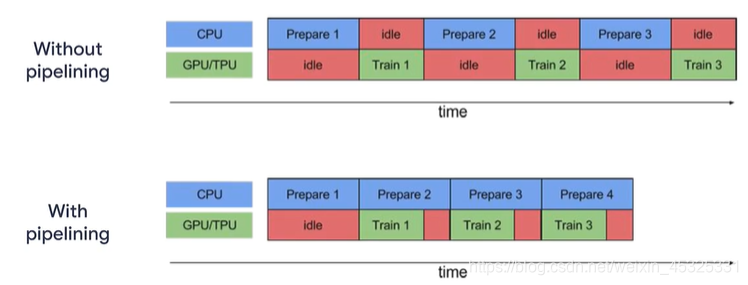
在现实世界中,分布式存储数据和分布式训练有着重要的作用。在没有进行pipeline时,程序按照处理——训练——处理——训练的流程进行,效率低下,经过pipeline后,程序会在训练的同时并行处理下一组数据,这样能够增加效率。
(1)缓存
缓存是一种很方便的提高性能的工具。tf.data.Dataset.cache()转换可以在内存或本地存储中缓存数据集。
如果数据可以放入内存中,使用缓存转换可以在第一个epoch将数据缓存到内存中,这样做可以避免后续epoch读取数据的时间开销。这种转换也可以通过指定本地文件名进行缓存。
dataset = tfds.load("cats_vs_dogs", split=tfds.Split.TRAIN)
# 内存中缓存
train_dataset = dataset.cache()
model.fit(train_dataset, epochs=...)
# 硬盘缓存
train_dataset = dataset.cache(filename='cache')
model.fit(train_dataset, epochs=...)
(2)并行API
tf数据并行性主要有三个方面;
-
map:在数据转换时,转换的开销很大,可能无法充分利用CPU,例如图像数据需要进行改变大小、随机翻转、选转等操作。因此,在map函数中,可以设置参数num_parallel_calls来设定CPU核数来增加效率。
num_cores = multiprocessing.cpu_count() augmented_dataset = dataset.map(augment, num_parallel_calls=num_cores)但是在复杂的情况下,硬件会进行虚拟化且不断变化,这会产生一些问题。因此,我们可以在运行中进行动态调整
from tensorflow.data.experimental import AUTOTUNE augmented_dataset = dataset.map(augment, num_parallel_calls=AUTOTUNE) -
prefetch:从数据集中加载数据可以使用预取(prefetch)方法,预提取方法会运行一个后台线程,利用缓冲区提前从输入数据集中预取元素,预取的数据应大于等于每个训练步的batch。
augmented_dataset = dataset.map(augment, num_parallel_calls=AUTOTUNE).prefetch(tensorflow.data.experimental.AUTOTUNE) -
interleave:加载数据的时候有时需要对数据进行反序列化或者解码,这些操作也会有很大的时间开销,因此我们需要减轻数据提取的开销,并行处理数据。
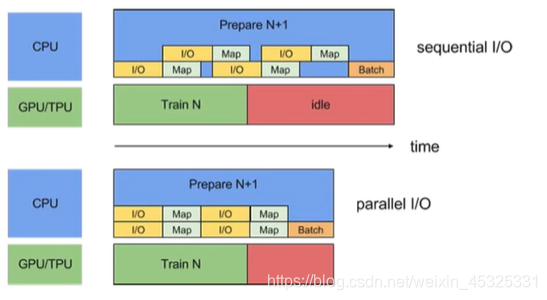
num_parallel_reads=4 dataset = files.interleave( tf.data.TFRecordDataset, # map function cycle_length=num_parallel_reads, num_parallel_calls=tensorflow.data.experimental.AUTOTUNE)
(3)运行顺序
我们已经介绍了tf.data中的很多方法,他们之间的顺序尤为重要
- map和batch:向量化处理,先进行batch后进行map
- map和cache:当转换很复杂时先map再cache
- shuffle和repeat:先repeat后shuffle会模糊边界从而性能更好,先shuffle后repeat能够保证顺序。
- interleave、prefetch、shuffle:使用对内存影响最小的顺序


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









