






在 Flink on YARN 运行模式下,Flink 提供了三种主要的部署模式:Session模式、Per-Job模式和 Application模式。每种模式在集群管理、资源分配、作业执行等方面有不同的特点,适用于不同的场景。接下来详细介绍这三种部署模式及其适用场景。
1.Session模式
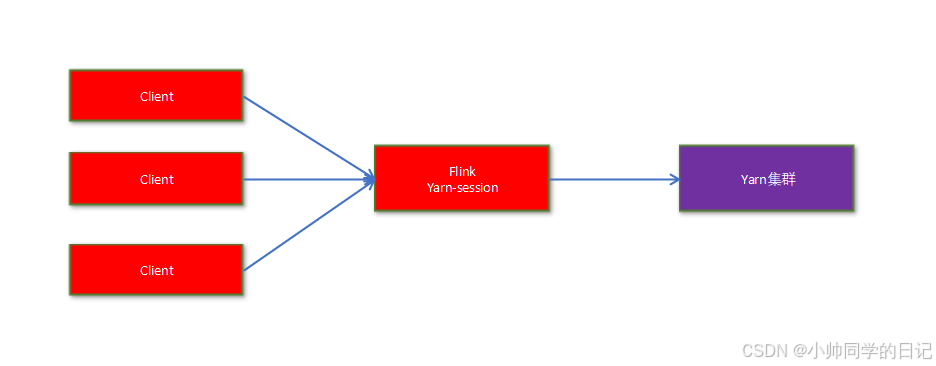 Session模式需预先在yarn启动一个Flink集群,启动JobManager,暂不启动TaskManager和Slot,后续任务提交时向Yarn申请资源,启动TaskManager和Slot。任务完成后释放TaskManager和Slot,所有任务共享Flink集群资源。这个Flink集群会常驻在yarn集群中,除非手工停止。
Session模式需预先在yarn启动一个Flink集群,启动JobManager,暂不启动TaskManager和Slot,后续任务提交时向Yarn申请资源,启动TaskManager和Slot。任务完成后释放TaskManager和Slot,所有任务共享Flink集群资源。这个Flink集群会常驻在yarn集群中,除非手工停止。
特点:
1.共享集群,一个集群运行多个作业。
2.需要事先申请资源,使用Flink中的yarn-session(yarn客户端),启动JobManager和TaskManger,
3.不需要每次递交作业申请资源,而是使用已经申请好的资源,从而提高执行效率
缺点:
1.如果某一个任务出现了问题导致整个集群挂掉,那就得重启集群中的所有任务。
2.在向Flink集群提交Job时, 如果资源被用完,则新的Job无法提交,等待资源释放。
适用场景:Session模式适合那些需要频繁提交的多个小Job, 并且执行时间都不长的Job.
启动命令:
bin/yarn-session.sh \
-d \
-jm 1024 \
-tm 1024 \
-nm yarn-session-flink \
-qu flink \
-s 8
bin/flink run examples/batch/WordCount.jarbin/yarn-session.sh
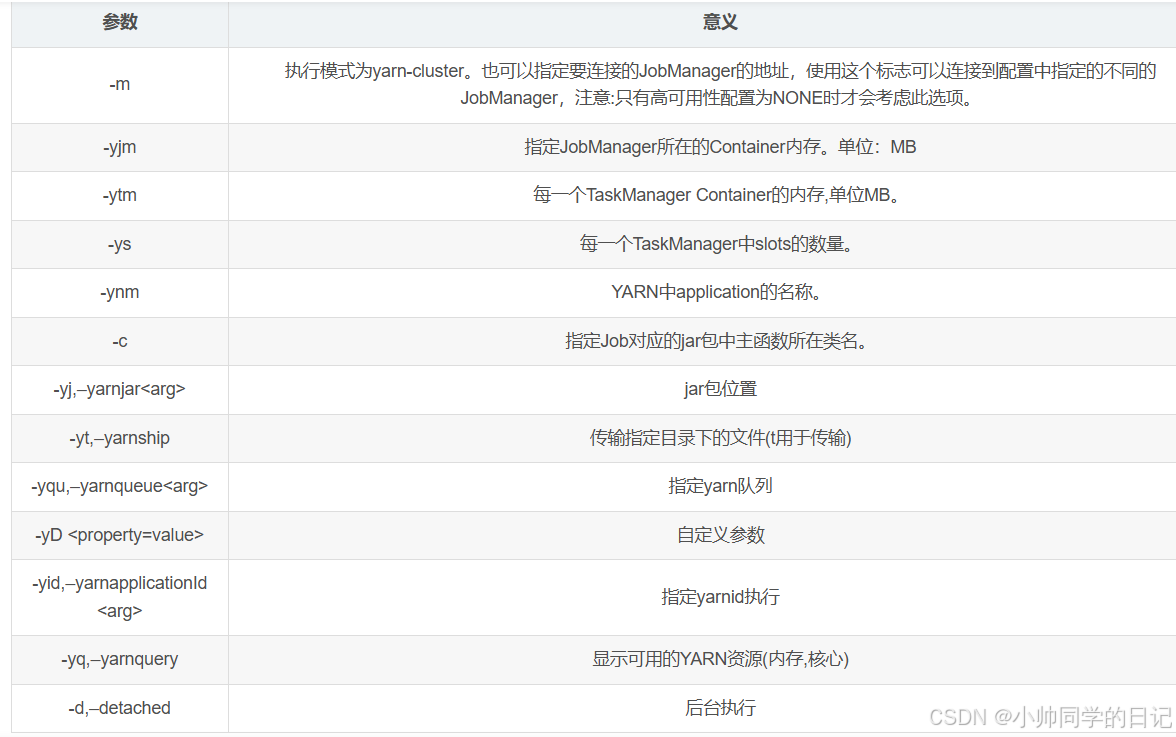
可用参数解读:
-d:分离模式,如果你不想让Flink YARN客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session也可以后台运行。
-jm(–jobManagerMemory):配置JobManager所需内存,默认单位MB。
-tm(–taskManager):配置每个TaskManager所使用内存,默认单位MB。
-nm(–name):配置在YARN UI界面上显示的任务名。
-qu(–queue):指定YARN队列名。
-s (slots): 指定每个TaskManager的槽位数。
2.Per-Job模式
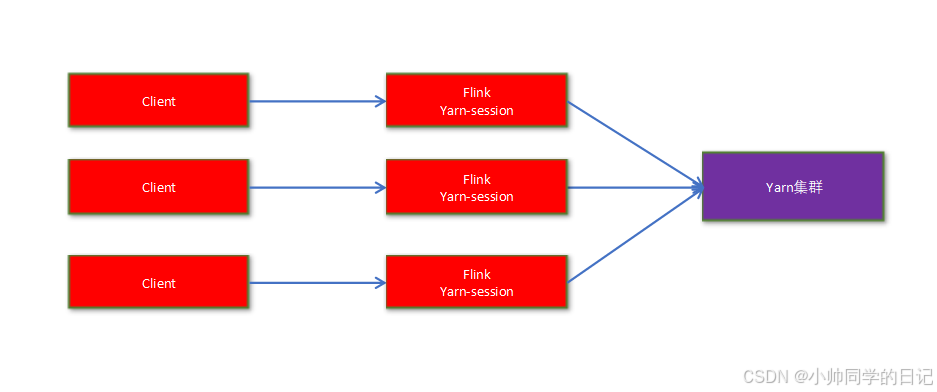
一个Job会对应一个Flink集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享资源,按需申请资源。
特点:
- 独享集群,一个作业一个集群:
- 每次提交作业时,都会启动一个独立的 Flink 集群,包括一个独立的 JobManager 和多个 TaskManager。
- 作业执行完毕后,整个集群会被销毁。
适用场景:Per-Job模式一般用来部署那些长时间运行的作业。
启动命令:
./bin/flink run \
# 指定yarn的Per-job模式,-t等价于-Dexecution.target
-t yarn-per-job \
# yarn应用的自定义name
-Dyarn.application.name=wordcount \
# 未指定并行度时的默认并行度值, 该值默认为1
-Dparallelism.default=3 \
# JobManager堆的内存
-Djobmanager.memory.process.size=2048mb \
# TaskManager堆的内存
-Dtaskmanager.memory.process.size=2048mb \
# 每个TaskManager的slot数目, 最佳配比是和vCores保持一致
-Dtaskmanager.numberOfTaskSlots=2 \
# 防止日志中文乱码
-Denv.java.opts="-Dfile.encoding=UTF-8" \
# 支持火焰图, Flink1.13新特性, 默认为false, 开发和测试环境可以开启, 生产环境建议关闭
-Drest.flamegraph.enabled=true \
# 入口类
-c xxxx.MainClass \
# 提交Job的jar包
xxxx.jar
 3.Application模式
3.Application模式
flink-1.11 引入了一种新的部署模式,即 Application 模式。
Session模式:所有作业共享集群资源,隔离性差,JM 负载瓶颈,main 方法在客户端执行。
Per-Job模式:每个作业单独启动集群,隔离性好,JM 负载均衡,main 方法在客户端执行。
Application模式和Per-Job的区别: 就是Application模式下, 用户的main函数是在集群中执行的
启动命令:
./bin/flink run-application \
#部署目标
-t yarn-application \
#类的全包名
-c xxxx.MainClass \
#并发数
-Dparallelism.default=3 \ #也可以使用 -p 3
#JobManager 内存
-Djobmanager.memory.process.size=2048m \
#TaskManager 内存
-Dtaskmanager.memory.process.size=4096m \
#作业名字
-Dyarn.application.name="MyFlinkWordCount" \
#TaskManager slot数量
-Dtaskmanager.numberOfTaskSlots=3 \
#flink客户端依赖包上传地址
-Dyarn.provided.lib.dirs="hdfs://$NameNode:$port/remote-flink-dist-dir/lib;hdfs://myhdfs/remote-flink-dist-dir/plugins" \
#作业jar包上传地址
hdfs://$NameNode:$port/job/jars/MyApplication.jar
4.三种方式区别:
session:所有作业在一个集群,集群生命周期独立于集群上运行的任何作业的生命周期,并且资源在所有作业之间共享;集群只有一个JobManager,所以JobManager容易有负载瓶颈;main方法在客户端执行;
per-job:每个作业启动一个独立的集群,集群的生命周期与作业的生命周期绑定在一起,资源隔离有更好的保证;每个独立的集群都有一个Jobmanager,所以JoobManager负载均衡;main方法在客户端执行;
application:每个应用程序创建一个会话集群,集群的生命周期与应用的生命周期绑定在一起,集群中特定的作业之间共享资源,在应用粒度上资源隔离有保证;每个集群都有一个JobManager,所以JobManager负载均衡;main方法在集群上执行;

















 1159
1159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









