




在构建检索增强生成 (RAG) 系统时,信息检索是核心环节。检索模块负责对用户查询进行分析,从知识库中快速定位相关文档或段落,为后续的语言生成提供信息支持。检索是指根据用户的问题去向量数据库中搜索与问题相关的文档内容,当我们访问和查询向量数据库时可能会运用到如下几种技术:
- 基本语义相似度(Basic semantic similarity)
- 最大边际相关性(Maximum marginal relevance,MMR)
- 过滤元数据
- LLM辅助检索
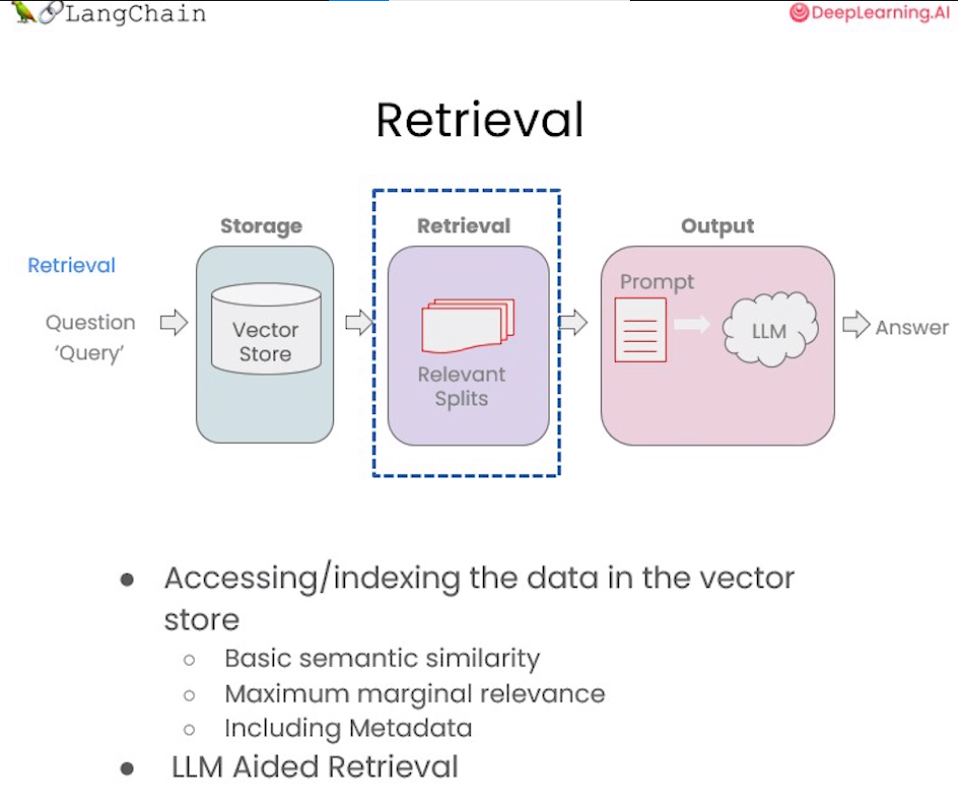
图 4.5.1 检索技术
使用基本的相似性搜索大概能解决你80%的相关检索工作,但对于那些相似性搜索失败的边缘情况该如何解决呢?这一章节我们将介绍几种检索方法,以及解决检索边缘情况的技巧,让我们一起开始学习吧!
一、向量数据库检索
本章节需要使用lark包,若环境中未安装过此包,请运行以下命令安装:
!pip install -Uq lark
1.1 相似性检索(Similarity Search)
以我们的流程为例,前面课程已经存储了向量数据库(VectorDB),包含各文档的语义向量表示。首先将上节课所保存的向量数据库(VectorDB)加载进来:
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory_chinese = 'docs/chroma/matplotlib/'
embedding = OpenAIEmbeddings()
vectordb_chinese = Chroma(
persist_directory=persist_directory_chinese,
embedding_function=embedding
)
print(vectordb_chinese._collection.count())
27
下面我们来实现一下语义的相似度搜索,我们把三句话存入向量数据库Chroma中,然后我们提出问题让向量数据库根据问题来搜索相关答案:
texts_chinese = [
"""毒鹅膏菌(Amanita phalloides)具有大型且引人注目的地上(epigeous)子实体(basidiocarp)""",
"""一种具有大型子实体的蘑菇是毒鹅膏菌(Amanita phalloides)。某些品种全白。""",
"""A. phalloides,又名死亡帽,是已知所有蘑菇中最有毒的一种。""",
]
我们可以看到前两句都是描述的是一种叫“鹅膏菌”的菌类,包括它们的特征:有较大的子实体,第三句描述的是“鬼笔甲”,一种已知的最毒的蘑菇,它的特征就是:含有剧毒。对于这个例子,我们将创建一个小数据库,我们可以作为一个示例来使用。
smalldb_chinese = Chroma.from_texts(texts_chinese, embedding=embedding)100%|██████████| 1/1 [00:00<00:00, 1.51it/s]
下面是我们对于这个示例所提出的问题:
question_chinese = “告诉我关于具有大型子实体的全白色蘑菇的信息”
现在,让针对上面问题进行相似性搜索,设置 k=2 ,只返回两个最相关的文档。
smalldb_chinese.similarity_search(question_chinese, k=2)
[Document(page_content='一种具有大型子实体的蘑菇是毒鹅膏菌(Amanita phalloides)。某些品种全白。', metadata={}),
Document(page_content='毒鹅膏菌(Amanita phalloides)具有大型且引人注目的地上(epigeous)子实体(basidiocarp)', metadata={})]
我们现在可以看到,向量数据库返回了 2 个文档,就是我们存入向量数据库中的第一句和第二句。这里我们很明显的就可以看到 chroma 的 similarity_search(相似性搜索) 方法可以根据问题的语义去数据库中搜索与之相关性最高的文档,也就是搜索到了第一句和第二句的文本。但这似乎还存在一些问题,因为第一句和第二句的含义非常接近,他们都是描述“鹅膏菌”及其“子实体”的,所以假如只返回其中的一句就足以满足要求了,如果返回两句含义非常接近的文本感觉是一种资源的浪费。下面我们来看一下 max_marginal_relevance_search 的搜索结果。
1.2 解决多样性:最大边际相关性(MMR)
最大边际相关模型 (MMR,Maximal Marginal Relevance) 是实现多样性检索的常用算法。

图 4.5.2 MMR
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









