






MySQL从8.0开始支持窗口函数,这个功能在大多数据库中早已支持,有的也叫分析函数。
窗口的概念非常重要,它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。简单的说窗口函数就是对于查询的每一行,都使用与该行相关的行进行计算。
窗口函数和普通聚合函数很容易混淆,二者区别如下:
- 聚合函数是将多条记录聚合为一条;而窗口函数是每条记录都会执行,有几条记录执行完还是几条。
- 聚合函数也可以用于窗口函数中。
窗口函数功能
| 名称 | 功能 |
|---|---|
| ROW_NUMBER() | 为分区中的每一行分配一个顺序整数【没有重复值的排序(记录相等也是不重复的),可以进行分页使用】 |
| RANK() | 与DENSE_RANK()函数相似,不同之处在于当两行或更多行具有相同的等级时,等级值序列中存在间隙【跳跃排序】 |
| DENSE_RANK() | 根据该ORDER BY子句为分区中的每一行分配一个等级。它将相同的等级分配给具有相等值的行。如果两行或更多行具有相同的排名,则排名值序列中将没有间隙【连续排序】 |
| PERCENT_RANK() | 计算分区或结果集中行的百分数等级 |
| CUME_DIST() | 计算一组值中一个值的累积分布 |
| LAG() | 返回分区中当前行之前的第N行的值。如果不存在前一行,则返回NULL |
| LEAD() | 返回分区中当前行之后的第N行的值。如果不存在后续行,则返回NULL |
| FIRST_VALUE() | 返回相对于窗口框架第一行的指定表达式的值 |
| LAST_VALUE | 返回相对于窗口框架中最后一行的指定表达式的值 |
| NTH_VALUE() | 从窗口框架的第N行返回参数的值 |
| NTILE() | 将每个窗口分区的行分配到指定数量的排名组中 |
上述函数按照功能划分,可以把MySQL支持的窗口函数分为如下几类:
- 序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
- 分布函数:PERCENT_RANK()、CUME_DIST()
- 前后函数:LAG()、LEAD()
- 头尾函数:FIRST_VALUE()、LAST_VALUE()
- 其他函数:NTH_VALUE()、NTILE()
函数示例
ROW_NUMBER()
语法格式:row_number() over(partition by 分组列 order by 排序列 desc);
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where 、group by、 order by 的执行。
创建数据表:
create table TEST_ROW_NUMBER_OVER(
id varchar(10) not null,
name varchar(10) null,
age varchar(10) null,
salary int null
);
select * from TEST_ROW_NUMBER_OVER t;
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a',10,8000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a2',11,6500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b',12,13000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b2',13,4500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c',14,3000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c2',15,20000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(4,'d',16,30000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(5,'d2',17,1800);
- 对查询结果进行排序
select id,name,age,salary,row_number()over(order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
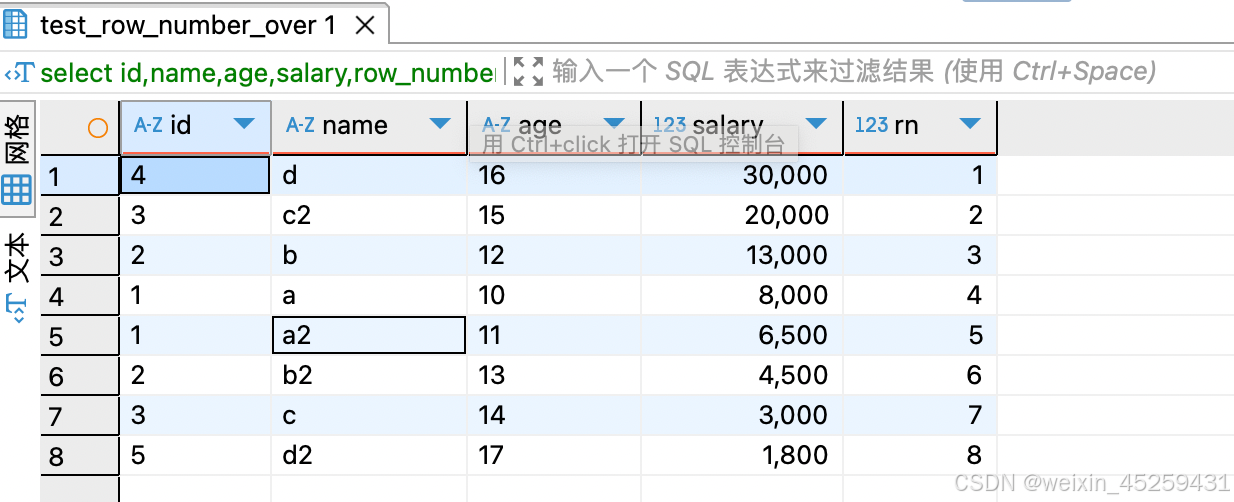
row_numer(),这个排序函数的特点是相同数据,先查出的排名在前,没有重复值。像这里的salary相同,先查出来的数据的rn排名优先
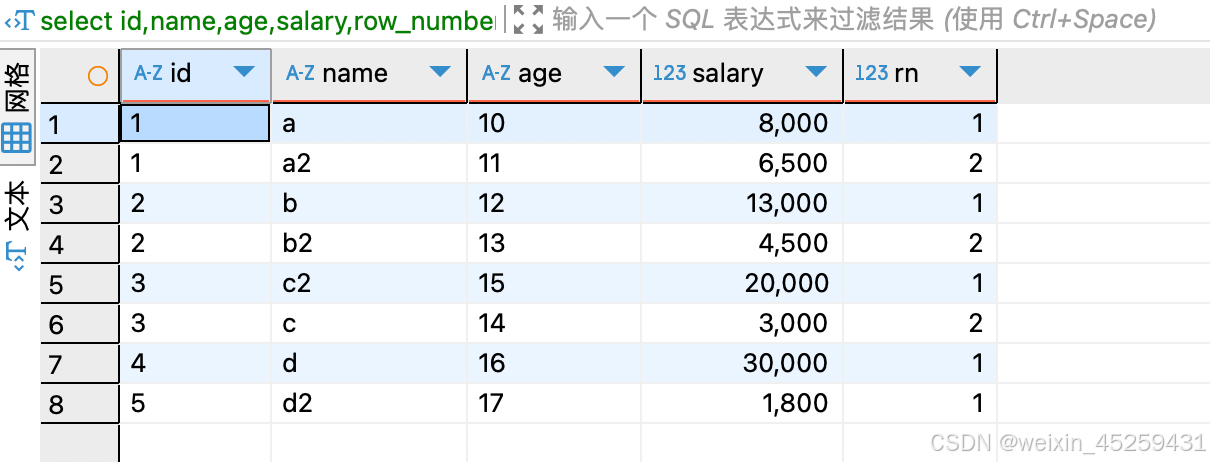
- 根据id分组排序
select id,name,age,salary,row_number()over(partition by id order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
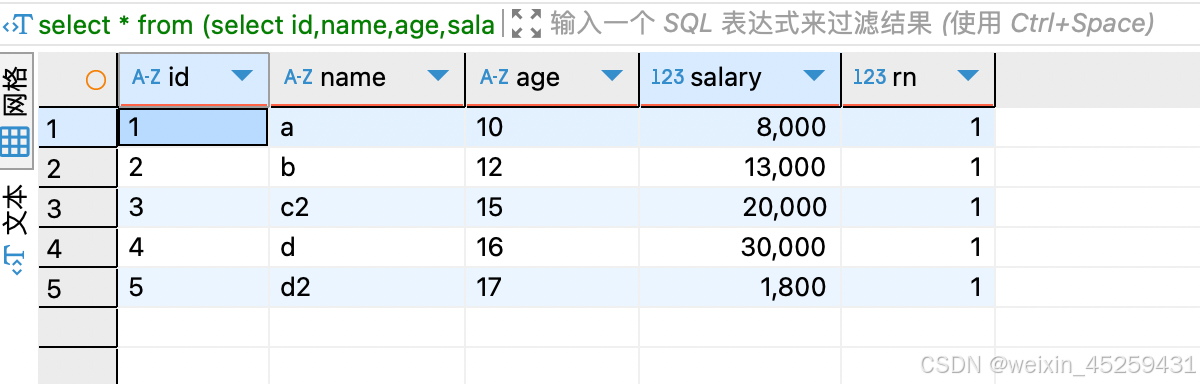
- 筛选以id分组查询后 序号为一的数据
select * from (select id,name,age,salary,row_number()over(partition by id order by salary DESC) rn
from TEST_ROW_NUMBER_OVER)
tt where rn = 1
- 排序找出年龄在13岁到16岁数据,按salary排序
select id,name,age,salary,row_number()over(order by salary DESC) rn
from TEST_ROW_NUMBER_OVER where age between 13 and 16
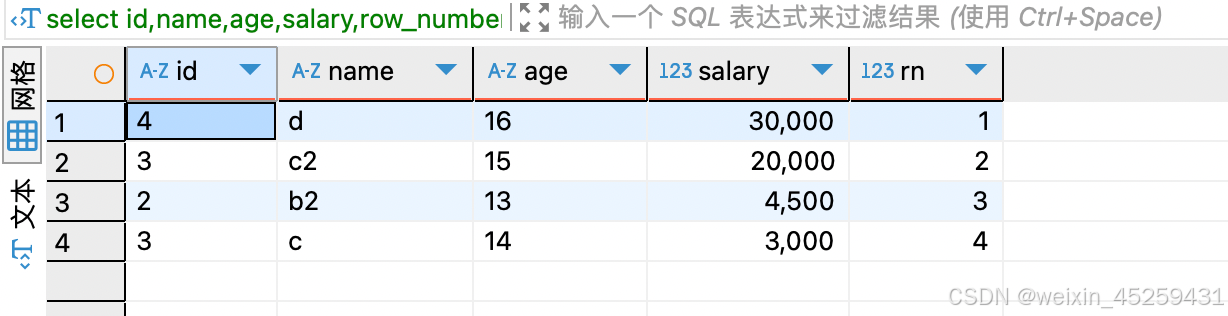
结果中 rank 的序号,其实就表明了 over(order by salary desc) 是在where age between and 后执行的
RANK()
select id,name,age,salary,rank()over(order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
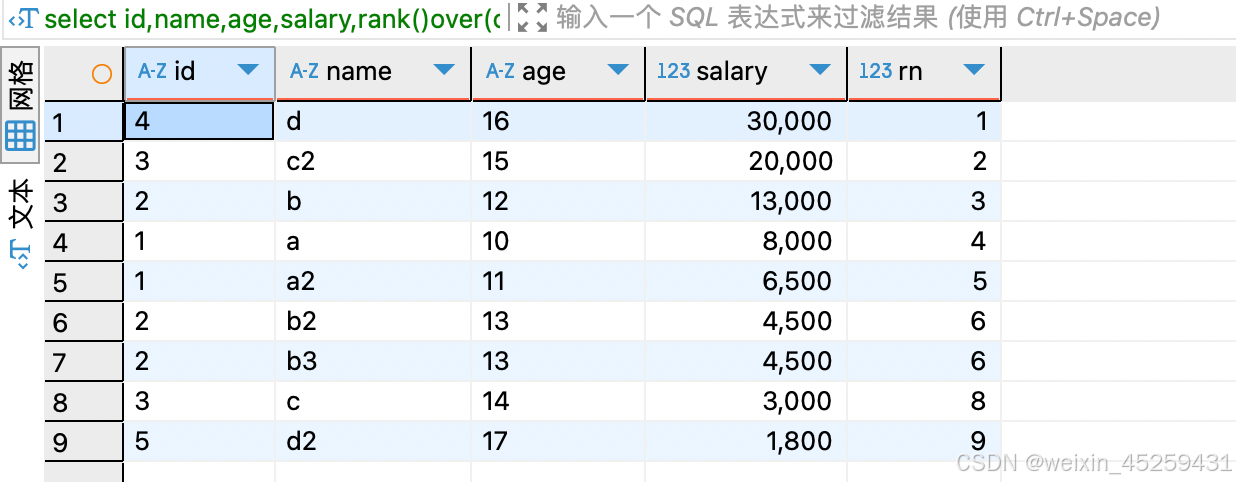
rank()函数,是跳跃排序,相同数据(这里为salary列相同)排名相同,比如并列第6,则两行数据(这里为rn列)都标为6,下一位将是第7名.中间的7被直接跳过了。排名存在重复值。
DENSE_RANK()
select id,name,age,salary,dense_rank()over(order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
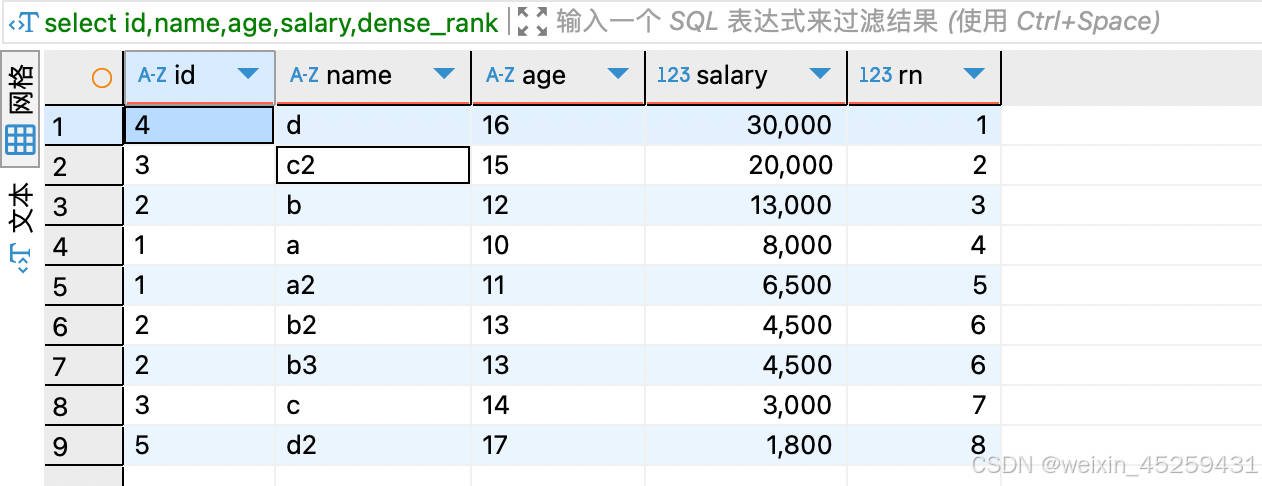
dense_rank(),这个是连续排序的,比如两条并列第6,则两行数据(这里为rn列)都标为6,下一个排名将是第7名
PERCENT_RANK()
select id,name,age,salary,percent_rank()over(order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
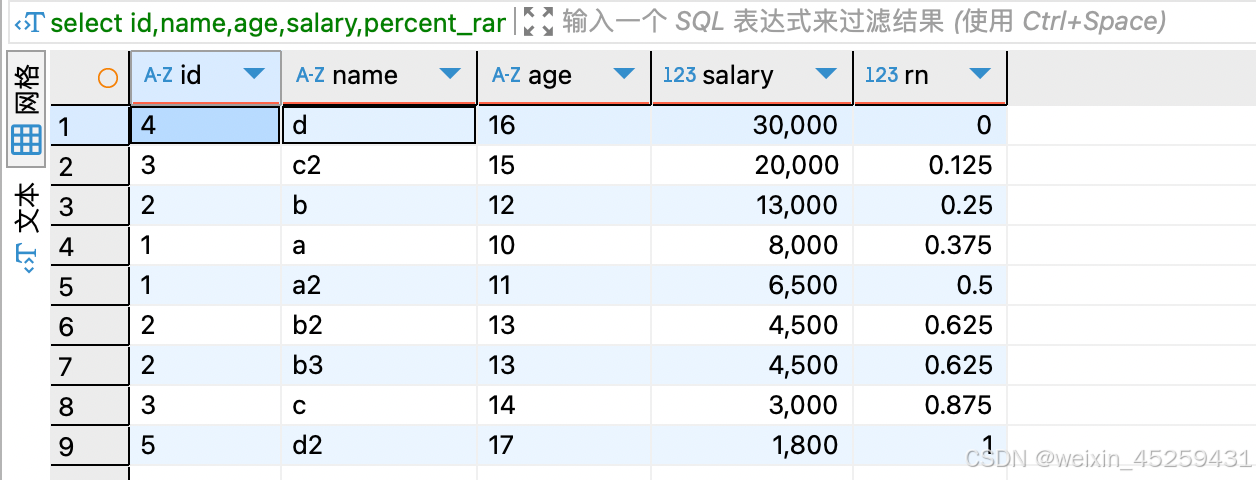
percent_rank:(分组内当前行的值(第几行)-1)/(分组内总行数-1)
CUME_DIST()
select id,name,age,salary,cume_dist()over(order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
如果按升序排列,则统计:小于等于当前值的行数/总行数(number of rows ≤ current row)/(total number of rows)。如果是降序排列,则统计:大于等于当前值的行数/总行数。
使用场景:统计大于等于当前薪水的人数,占总人数比例
注意:CUME_DIST、PERCENT_RANK均不支持WINDOW子句(between…and…)
LAG() 、 LEAD()
Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列
在实际应用当中,若要用到取今天和昨天的某字段差值时,Lag和Lead函数的应用就显得尤为重要。当然,这种操作可以用表的自连接实现,但是LAG和LEAD与left join、rightjoin等自连接相比,效率更高,SQL更简洁。下面我就对这两个函数做一个简单的介绍。
函数语法如下:
lag(exp_str,offset,defval) over(partion by …order by …)
lead(exp_str,offset,defval) over(partion by …order by …)
参数说明:
exp_str是字段名
Offset是偏移量,即是上1个或上N个的值,假设当前行在表中排在第10行,则offset 为3,则表示我们所要找的数据行就是表中的第7行(即10-3=7)。
Defval默认值,当两个函数取上N/下N个值,当在表中从当前行位置向前数N行已经超出了表的范围时,lag()函数将defval这个参数值作为函数的返回值,若没有指定默认值,则返回NULL,那么在数学运算中,总要给一个默认值才不会出错
- 对salary列:取上一个salary列作为单独的列,若不指定默认值,则默认值为NULL
select id,name,age,salary,lag(salary,1)over(order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
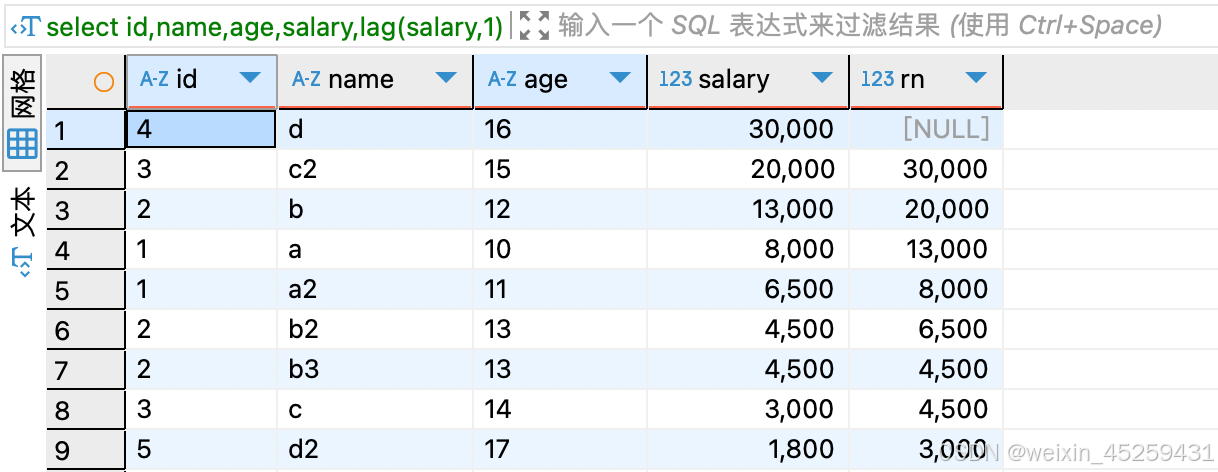
- 对salary列:取上一个salary列作为单独的列,指定默认值为0
select id,name,age,salary,lag(salary,1,0)over(order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
- 对salary列:取下一个salaryL列作为单独的列,指定默认值为0
select id,name,age,salary,lead(salary,1,0)over(order by salary DESC) rn
from `TEST_ROW_NUMBER_OVER`
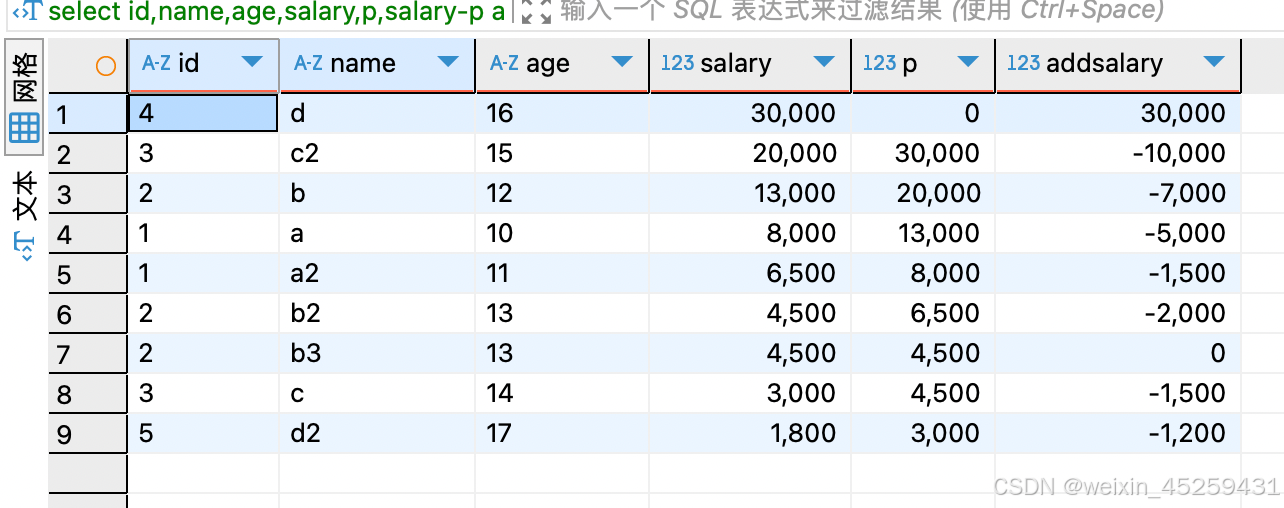
- 运算:薪水跟上次相比涨了多少
select id,name,age,salary,p,salary-p as addsalary from
(select id,name,age,salary,lag(salary,1,0)over(order by salary DESC) p
from `TEST_ROW_NUMBER_OVER`) tt
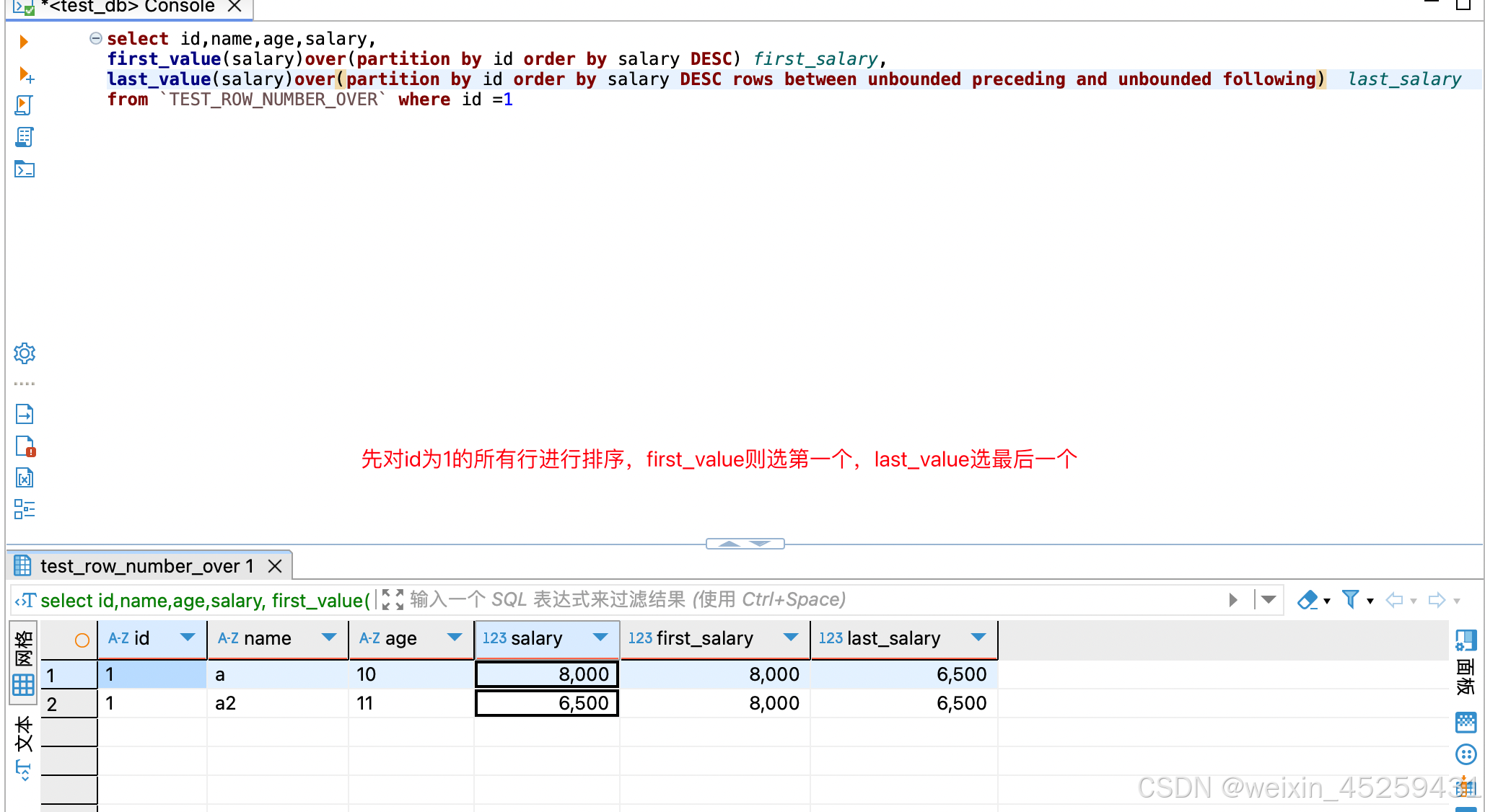
FIRST_VALUE()、LAST_VALUE()
select id,name,age,salary,
first_value(salary)over(partition by id order by salary DESC) first_salary,
last_value(salary)over(partition by id order by salary DESC) last_salary
from `TEST_ROW_NUMBER_OVER`
first_value()的结果容易理解,在提供一组已排序行的情况下,FIRST_VALUE 返回有关窗口框架中的第一行的指定表达式的值;
last_value()默认统计范围是 rows between unbounded preceding and current row,也就是取当前行数据与当前行之前的数据的比较.
那么如果我们直接在每行数据中显示最后的那个数据,需在order by 条件的后面加上语句:rows between unbounded preceding and unbounded following , 也就是前面无界和后面无界之间的行比较.
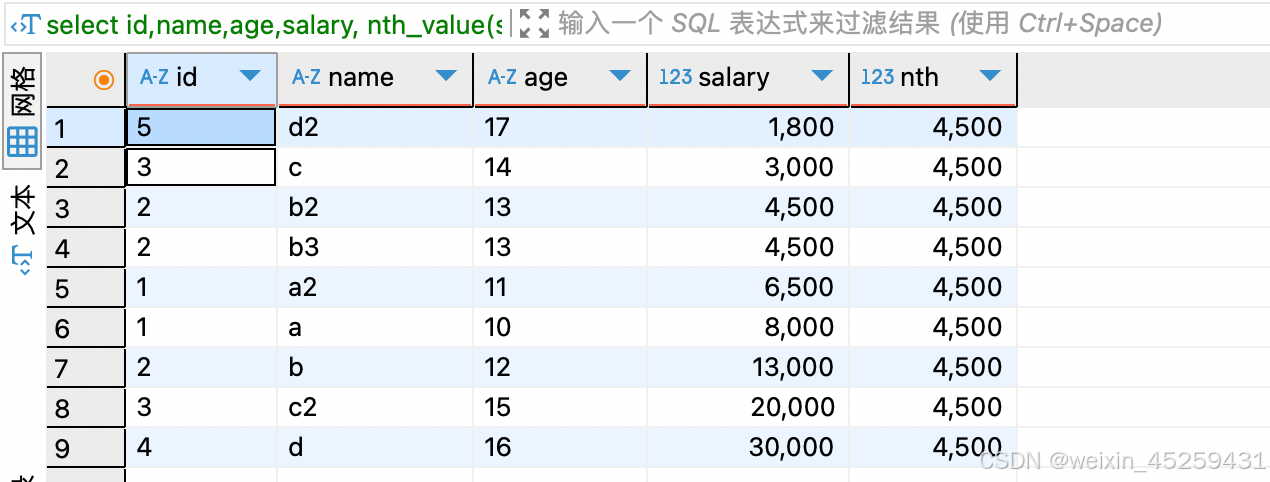
NTH_VALUE()
select id,name,age,salary,
nth_value(salary,3) over( order by salary ASC rows between unbounded preceding and unbounded following) nth
from `TEST_ROW_NUMBER_OVER`
其中NTH_VALUE()中的第二个参数是指这个函数取排名第几的记录
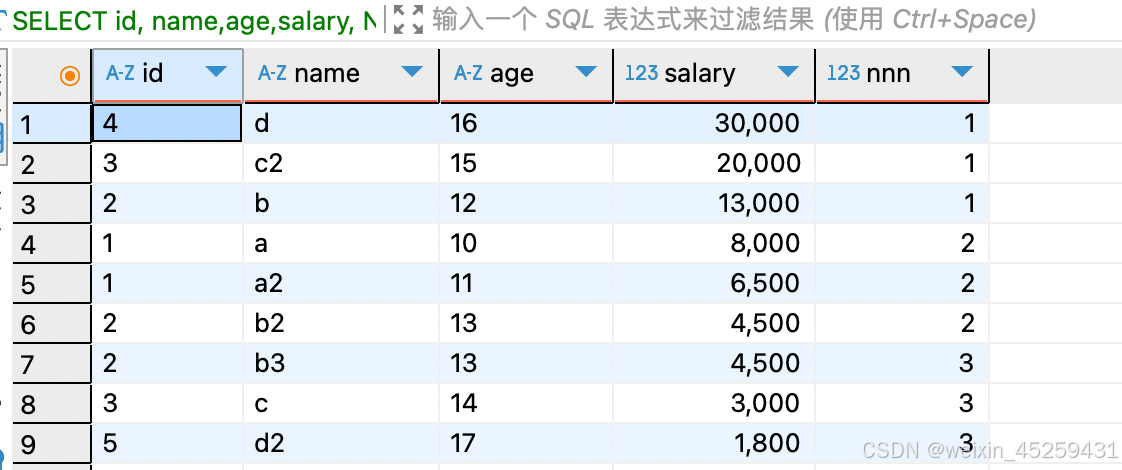
NTILE()
NTILE 窗口函数将分区中已排序的行划分为大小尽可能相等的指定数量的已排名组,并返回给定行所在的组。
SELECT id, name,age,salary,
NTILE (3) OVER (ORDER BY salary DESC) as nnn
FROM TEST_ROW_NUMBER_OVER ORDER BY 5;
CTE()
MySQL的CTE是在MySQL8.0版本开始支持的,公用表表达式是一个命名的临时结果集,仅在单个SQL语句(例如select、insert、delete和update)的执行范围内存在。CTE分为递归CTE和非递归CTE。
CTE的出现简化了复杂查询语句的编写,提高了SQL性能。
- 非递归
语法:
WITH cte_name (column_list) AS (
query
)
SELECT * FROM cte_name
生成一个cte_name的派生表,然后再操作派生表
WITH age_list AS(
select id,age,salary from `TEST_ROW_NUMBER_OVER` where salary > 10000
)
select * from age_list
新建一个学生表 和 学校表 进行关联
WITH student AS(
select id,username,school_id
from st_students
where username like '%浩南%'
),
school AS(
select student.id student_id,op_schools.id as school_id,`name`,address,student_count
from `op_schools`
right join student on school_id = op_schools.id
)
select student_id,school_id,`name`,student_count,row_number()over(partition by school_id order by student_count DESC) rn
from school
order by student_count DESC
- 递归
递归CTE概念:递归的方式是CTE的子查询可以引用其本身,使用递归方式时,WITH子句中要使用WITH RECURSIVE代替。递归CTE子句中必须包含两个部分,一个是种子查询(不可引用自身),另一个是递归查询,这两个子查询可以通过 UNION、UNION ALL或UNION DISTINCT 连接在一起。
注意:种子SELECT只会执行一次,并得到初始的数据子集,而递归SELECT是会重复执行直到没有新的行产生为止,最终将所有的结果集都查询出来,这对于深层查询(如具有父子关系的查询)是非常有用的。
CREATE TABLE emp(
id INT PRIMARY KEY NOT NULL,
name VARCHAR(100) NOT NULL,
manager_id INT NULL,
INDEX (manager_id)
)
----------------------------------------------
INSERT INTO emp VALUES
(333, "总经理", NULL),
(198, "副总1", 333),
(692, "副总2", 333),
(29, "主任1", 198),
(4610, "职员1", 29),
(72, "职员2", 29),
(123, "主任2", 692);
----------------------------------------------
WITH RECURSIVE test(id, name, path)
AS
(
SELECT id, name, CAST(id AS CHAR(200))
FROM emp WHERE manager_id IS NULL
UNION ALL
SELECT e.id, e.name, CONCAT(ep.path, ',', e.id)
FROM test AS ep JOIN emp AS e ON ep.id = e.manager_id
)SELECT * FROM test ORDER BY path;
链接:https://juejin.cn/post/6844904113126244365
https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/c_Window_functions.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









