







 本文介绍了Python作为强大的科学计算器,数据采集和分析工具,以及工作流基础设施的使用场景。通过实例展示了Python在基础运算、网络爬虫、机器学习和可视化等方面的应用,强调了Python的易用性和高效开发效率。同时,推荐了学习资源和练习题以帮助读者深入掌握Python。
本文介绍了Python作为强大的科学计算器,数据采集和分析工具,以及工作流基础设施的使用场景。通过实例展示了Python在基础运算、网络爬虫、机器学习和可视化等方面的应用,强调了Python的易用性和高效开发效率。同时,推荐了学习资源和练习题以帮助读者深入掌握Python。
Python可以做什么——Python语言的一个简要导引
0. Why Python?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XdDi5sSW-1579315050706)(static/TIOBE Programming Language Index.png)]](https://i-blog.csdnimg.cn/blog_migrate/0a95807e960747c4a02066bd0ce0a1f1.png)
Python是一项被广泛应用在各个领域的编程语言,并且其应用频率和范围仍然在不断上升(见上图,各个编程语言社区指数,反映了编程语言的使用频率). Python能够做什么呢?利用其多样的第三方库提供的丰富功能,我们几乎可以使用Python轻松做到任何(计算机能够做到的)事情.
通过 import scipy, 我们可以在几行内解决导数计算和矩阵乘法;通过import tensorflow, 我们可以使用十行代码搭建并训练好一个识别手写数字数据集的神经网络;通过import requests, 我们可以自动获取一切你想获取的网络资源构筑自己的信息流体系;通过import antigravity, 我们可以飞!(划掉).

当然,语言仅仅提供了表达思想的手段,这些功能并不是Python语言的专利,那么为什么我们选择Python做这些事情,而不是其他编程语言呢?总的来说,Python作为一个相当高层的建筑,屏蔽了计算机底层结构和实现细节,通过更简洁且更少限制的语法,我们可以使用更少、更优雅的代码完成更多的功能. Python以执行效率为代价,换取开发效率的提升. 这在过去计算效率低下的时代也许难以接受,但在计算能力和人力成本同时提高的今天,以执行效率换取开发效率的提升通常是值得的.
在本文中,我们将探索Python的三个使用场景:作为一个强大的科学计算器,作为数据科学的工具包,以及作为日常自动化工作流的基础设施. 我们不会解释每一个模块的命令详细的工作原理(具体的语法和原理解释将在未来的文章中进行),而是希望通过例子的方式引导读者发现和探索Python的强大功能. 完整的代码文件将提供在附录中. 如果你不知道如何搭建Python环境以及如何安装好示例中的第三方库,可以参考附录中的环境搭建有关的参考资料,或者参考我们下一次的详细介绍环境搭建的文章. 为了亲自体验Python的强大功能,你可以直接运行附录中的代码,或者自己敲一遍代码之后运行,如果在阅读和运行中遇到什么问题欢迎联系我们 .
如果没有特殊说明,本文中的代码均支持Python 3.6或更高版本. Python 2.x已经于2020.01.01正式退役,所以请不要在新项目中使用.
1. Python作为强大的科学计算器
基础运算
实现数学计算是任何语言的一个基础功能. Python作为解释性语言的一个优势在于以交互的方式使用它的解释器,也就是在输入命令后立刻看到结果反馈:
>>> 1 + 2
3
>>> 5 / 2
2.5
>>> (1 + 2) * (4 - 2)
>>> 6
我们可以就像使用计算器那样,在交互环境下输入我们希望计算的代数式, Python立刻就能给出计算结果. +, -, *, /等运算符的含义是不言自明的. 如果你需要进行一些稍微复杂的计算,可以引用math中的对应函数:
>>> from math import pi, sin, gcd, gamma
>>> sin(0.5*pi)
1.0
>>> gcd(36, 60)
12
>>> gamma(5)
24.0
这里我们引用了math标准库中的一个常量pi (
π
\pi
π)和三个函数,分别用于计算正弦值、两个数的最大公约数以及Gamma函数
Γ
(
z
)
\Gamma(z)
Γ(z). Python提供了相当丰富的计算函数用于满足基础的计算需求.
高级运算
一些涉及复杂结构的计算可以通过Python的科学计算相关的模块,例如numpy, scipy, sympy实现,例如矩阵乘法:
>>> import numpy as np
>>> A = np.array(
... [[1, 2],
... [3, 4]]
... )
>>> B = np.array(
... [[0, 1],
... [1, 0]],
)
>>> A.dot(B)
array([[2, 1],
[4, 3]])
以上我们实现了矩阵计算
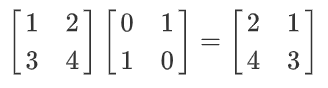
矩阵计算相关的功能在数据分析中尤其实用.
2. Python作为数据采集、分析和表示的工具
Python目前的一个重要应用领域在于数据分析,并且在数据分析的整个过程,包括数据的采集、分析和最后的结果展示中都能够得到应用. 我们通过三个过程中的三个例子来考察一下Python是如何成为我们的数据分析工具包的.
数据采集:网络爬虫
爬虫就是自动化的网页浏览和操作工具,可以用来完成手工操作繁琐的信息获取工作. 举个简单的例子,假如你想知道最近有什么热门的Python项目或者模块,利用requests执行网络请求并引入BeautifulSoup完成HTML解析,我们可以获取Github上以Python为关键词搜索前十页的结果:
import requests
from bs4 import BeautifulSoup
keyword = 'python'
url_form = 'https://github.com/search?p={page}&q={keyword}&type=Repositories'
for page in range(1, 11):
res = requests.get(url_form.format(page=page, keyword=keyword), headers=headers)
soup = BeautifulSoup(res.text, 'html.parser')
repo_list_items = soup.find_all(class_='repo-list-item')
for repo_list_item in repo_list_items:
repo_title = repo_list_item.find('h3').find_next_sibling().get_text().strip()
print(repo_title)
执行后我们就可以获得相应的标题:
All Algorithms implemented in Python
My Python Examples
Python脚本。模拟登录知乎, 爬虫,操作excel,微信公众号,远程开机
Show Me the Code Python version.
最良心的 Python 教程:
...
除了标题之外,我们还可以进一步获取每一个项目的详细信息,例如热度、项目维护进度、贡献者等等. 网络资源的获取是相当实用的功能,几乎任何网络数据都可以通过合适的方式来自动化地获取. 一旦代码写好之后,我们就可以在之后任何想要获取同样信息的时候立刻复用,如果需要的话,甚至可以设置一个定时任务,在特定时间重复执行来获得某些随着时间发生变化的数据,例如天气、金融市场信息等等.
#数据分析:机器学习
Python最著名的机器学习框架之一Tensorflow提供了一个便利的接口来搭建机器学习模型. 如果你不知道什么是机器学习也没有关系,只需要知道这里我们的任务是:通过大量已知数据,教会计算机识别手写数字,以下给出了Tensorflow文档中的实现的用于手写数字数据集MNIST识别的神经网络搭建和训练的过程.
from __future__ import absolute_import, division, print_function, unicode_literals
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train/255.0, x_test/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)
训练完成之后model将是一个可以预测手写数字的模型,我们可以试验一下,首先利用可视化模块matplotlib显示出测试集中第一个手写数字图片的内容,然后我们观察模型的预测结果是否准确:
TEST_INDEX = 0
plt.figure()
plt.imshow(x_test[TEST_INDEX])
plt.colorbar()
plt.show()
predictions = model.predict(x_test)
print(np.argmax(predictions[TEST_INDEX]))
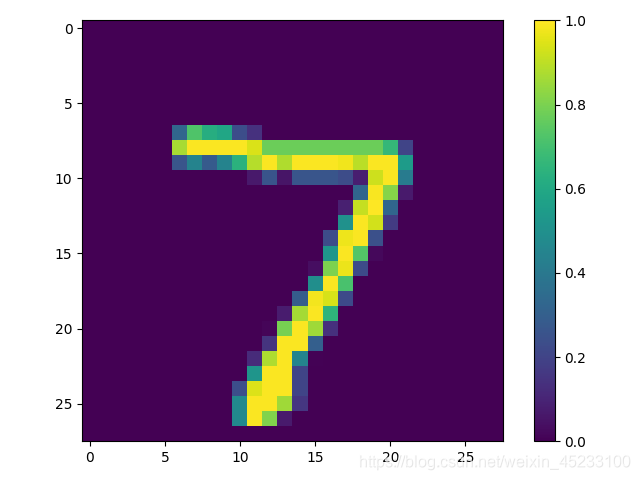
从图像中可以看出这个手写数字是7, 运行后程序输出的结果同样是 7, 这表明我们所训练的模型在这个测试点上预测是准确的. 你可以尝试修改TEST_INDEX的值来检查在不同的测试点处是否预测正确,由于我们的模型总是存在误差,因而必然有某些数据点处模型的预测是失败的,不过大部分情况下仍然是成功的. 这个例子表明使用Python可以用极少的代码量就构建起一个相当强大的机器学习模型并且将其投入使用.
更多机器学习有关的内容将在以后的进阶篇中进行介绍.
数据表示:可视化
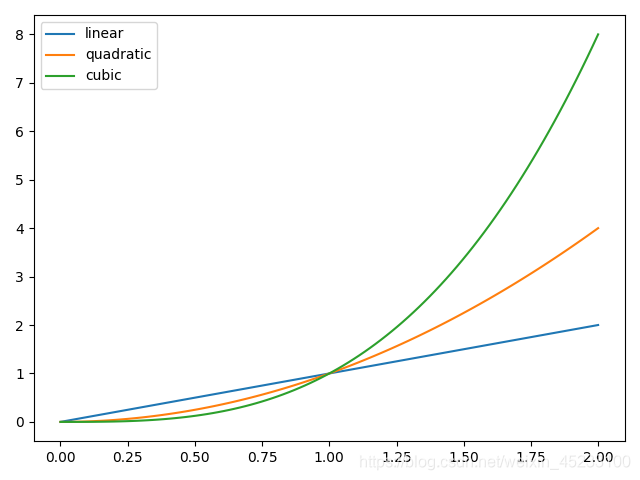
在上一节中我们已经看到了matplotlib的图片显示(实际上是矩阵可视化)功能. matplotlib是一个相当强大的可视化模块,支持各种不同类型的图形绘制,我们可以使用它绘制数学函数或来自真实世界中的数据:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 2, 100)
plt.plot(x, x, label='linear')
plt.plot(x, x**2, label='quadratic')
plt.plot(x, x**3, label='cubic')
plt.legend()
plt.show()
另外再介绍一个绘图模块graphviz, 它使用一种名为dot的标记语言作为规范生成图状结构:
from graphviz import Source, render
source = """
digraph {
dpi = 300
{rank=same; A; B}
A [label="Learn"]
B [label="Code"]
C [label="Sleep"]
A -> B -> C -> A
}
"""
dot = Source(source)
dot.render('life', view=True, format='png')
以下为渲染效果:
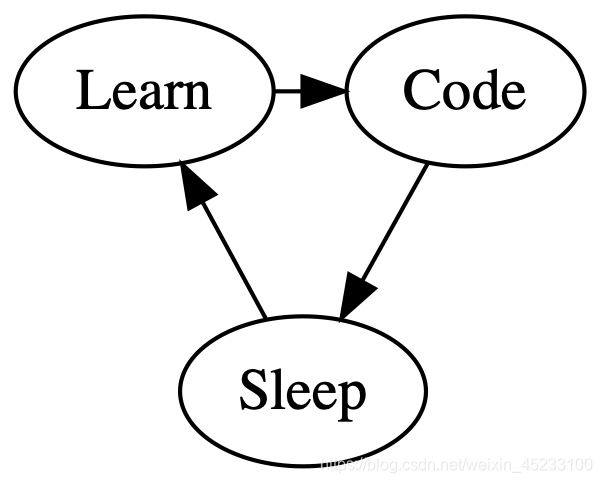
Graphviz高度可定制化,你可以使用它绘制相当复杂并且符合自己要求的图形.
3. Python作为工作流的基础设施
文件管理
管理文件的过程中常常需要完成某些重复性的操作. 例如学校要交社会实践报告,需要把所有报告统一命名为姓名_学号_报告标题 的格式,而我目前一共有一千份报告,需要都加上name_100_的前缀:
repo000.pdf
repo001.pdf
repo002.pdf
...
repo999.pdf
使用bash/zsh/fish等shell提供的命令集是其中一个选择,但在复杂情况下代码的可读性并不好, Python同样可以很好地完成这一文件管理操作:
from pathlib import Path
path_str = 'your_folder/'
path = Path(path_str)
for file in path.iterdir():
file.rename(path_str + 'name_100_' + file.name)
在实际执行时请将path_str = 'your_folder/'中的your_folder修改为你的报告文件所在的文件夹路径.
之后我们就得到了一族重命名过后的文件:
name_100_repo000.pdf
name_100_repo001.pdf
name_100_repo002.pdf
...
name_100_repo999.pdf
创建命令行工具
利用Python的click模块我们能够很容易地创建基于命令行的工具,实现自己的命令集,以实现特定的任务,如果你的工作流非常依赖于命令行环境(这对于程序员,特别是经常在*nix环境下工作的程序员而言是十分常见的),能够快速创建自己的命令是非常方便的. 例如,我希望能够构建一个Todo-List管理系统,利用create, list, finish等命令来添加、查看、完成待办事项,从而在命令行中实现任务管理. 由于命令行的背景知识和实现代码需要较多的篇幅来介绍,限于篇幅,我们将把这部分内容放在进阶内容中的Build Your Own Command Line Toolkit专题进行介绍.
作为其他工具提供的可编程接口
计算机工具,特别是编辑器,通常会提供某些可定制性,特别是可编程性, Python通常会被用在这一场合. 例如,编辑器Sublime提供Python接口用于创建插件,因而你可以使用自己的Python知识来优化自己的编程体验;另外Vim同样也允许使用Python创建插件.
4. 其他模块
除了上面所述的计算、数据分析、以及作为基础设施作用外, 结合第三方模块Python还可以实现:
- 使用
Flask,Django,Tornado等模块,可以使用Python搭建web服务器. - 使用
tkInter,pyQt,wxPython等模块,可以使用Python构建窗口程序. - 使用
Ansible,Salt,OpenStack等模块,可以使用Python进行自动化运维. - …
如果你想找到相应的模块来实现自己想要的功能,可以参考Python的标准库:
https://docs.python.org/3/library/index.html
https://docs.python.org/3/py-modindex.html
当然使用Google同样是不错的选择. 通常被广泛使用的模块都有相应详细的文档支持,可以通过第三方模块所对应的文档进行学习.
5. 可用的学习资源推荐
-
如果你想要自己动手运行本文中的代码,可以参考以下链接安装Python并且搭建Python环境:
https://www.runoob.com/python/python-install.html
https://blog.youkuaiyun.com/ling_mochen/article/details/79314118
-
Python的官方文档提供了详细的入门学习材料,并且目前已经提供了详细的中文支持:
https://docs.python.org/3/tutorial/index.html
https://docs.python.org/zh-cn/3/tutorial/index.html
-
如果你不喜欢读文档而更偏爱在做中学,可以考虑阅读 Learn Python 3 The Hard Way(笨办法学Python3), 此书推崇即使你还不理解你在写什么也要无论如何先敲代码,在写的过程中学习语法. 另外此书的文风特别有趣.
-
毫无疑问,实践是提升语言能力的最好方式. 你可以在语言练习网站里通过反馈来检验自己的理解和编程能力,这里给出几个不错的选择,你可以使用它们练习各种语言的基础能力,不仅仅只限于Python.
https://www.hackerrank.com
https://www.codewars.com
https://leetcode.com
6. 练习题
-
在Python环境下输入
import antigravity会发生什么?(建议做本练习时不要呆在室内,要找一个没有天花板的地方) -
尝试使用Python计算:
23+32,32-23,12*3,11/5. -
尝试计算
11//5, 你发现了什么? -
尝试修改网络爬虫一节
keyword的值,搜索你感兴趣的主题相关的Github项目. -
尝试修改机器学习一节中模型测试代码里
TEST_INDEX的值,看看能否找出一个模型的预测结果和事实不符的测试数据. -
尝试修改graphviz中三个双引号之间的部分,绘制出如下所示的树形结构:
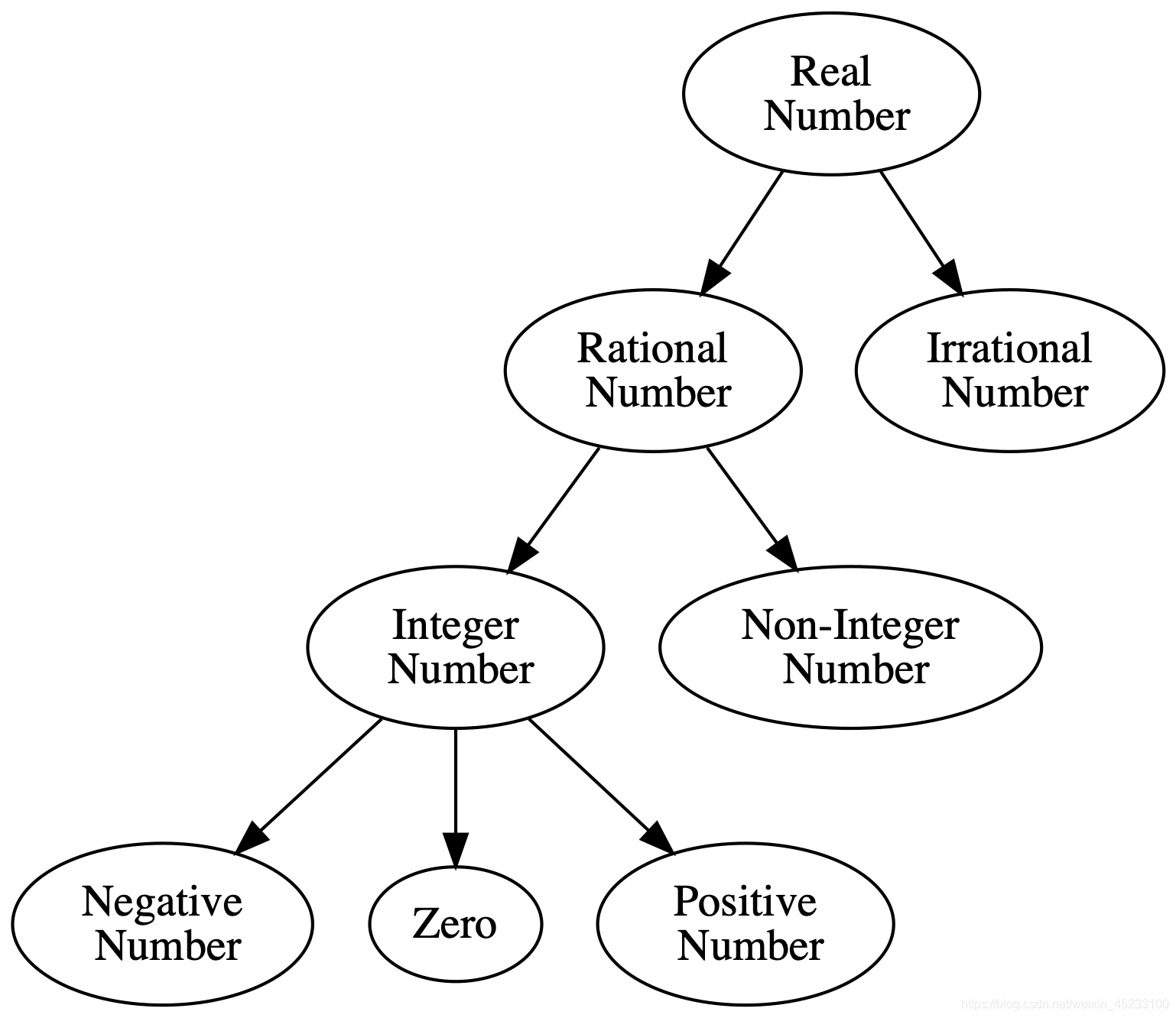
-
通过搜索引擎等渠道查找本文中所涉及的模块的功能.
-
通过搜索引擎等渠道了解Python还有哪些模块、以及它们可以实现怎样的功能.
-
通过搜索引擎等渠道搜索适合自己的Python学习材料.
本文来自Talk of Python公众号,如果想要了解更多信息或者获取上方的练习题答案,请关注我们吧~


















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









