







 本文详细介绍了MySQL的执行流程,包括建立连接、查询缓存、解析器、优化器和执行器的工作原理。重点讨论了SQL解析的词法分析和语法分析,以及优化器如何选择执行计划。在执行器阶段,解释了数据缓冲区的使用和binlog的记录规则。最后,总结了整个查询过程的关键步骤。
本文详细介绍了MySQL的执行流程,包括建立连接、查询缓存、解析器、优化器和执行器的工作原理。重点讨论了SQL解析的词法分析和语法分析,以及优化器如何选择执行计划。在执行器阶段,解释了数据缓冲区的使用和binlog的记录规则。最后,总结了整个查询过程的关键步骤。
- 执行流程图
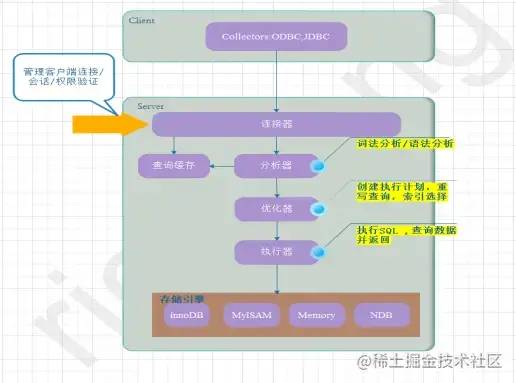
1. 建立连接
默认如果超过 8 小时没有发生过数据传输服务端就会自动关闭该连接。可以通过 wait_timeout 参数来设置超时时间。
2. 查询缓存
如果缓存命中,直接返回结果,如果缓存没有,则继续往下走。
-- 查询缓存相关设置
SHOW VARIABLES LIKE '%query_cache%';
-- 开启查询缓存
SET GLOBAL query_cache_type = ON;
注意!mysql8.0版本以后,缓存被官方删除掉了。
如果在一个写多读少的环境中,缓存会频繁的新增和失效。对于某些更新压力大的数据库来说,查询缓存的命中率会非常低,推荐将缓存放在客户端
Mysql缓存相关知识
1、Adaptive Hash Index (AHI) 自适应 hash
2、Mysql 内存区域分布
3. 解析器
如果查询缓存未开启 (query_cache_type = OFF)或者 未命中 的情况则会走正常的查询流程
SQL解析由 词法分析 和 语法/语义分析 两个部分组成。
1.词法分析
词法分析主要是把输入转化成一个个 Token。其中 Token 中包含 Keyword(也称symbol)和 非 Keyword。简单说就是对一段连的原始 SQL 语句进行分解,得到一个个独立的单词,并且组织成为单词的形式。
例如:SQL语句
SELECT `name` FROM user_table
在分析之后,会得到 4 个 Token, 其中有 2 个 Keyword,分别为 SELECT 和 FROM具体代码实现在 sql/lex.h 和 sql/sql_lex.cc 文件中。
| Keyword | Keyword | 非Keyword | 非Keyword |
| SELECT | FROM | name |
|
mysql-server/sql/lex.h 下图部分 Keyword 关键字截图

2.语法分析
对词法解析后的单词链进行语法结构分析,构造出SQL语法树,然后生成语义特征。
语法树是一个树形结构。
在上面几步完成之后会产生一个 AST 解析树,提供给优化器使用。Mysql 的这部分代码在 sql/sql_yacc.yy,共有18万行。
相关知识
Abstract Syntax Tree(AST) 抽象语法树
4.优化器
一条SQL能够进入到优化器阶段,表示sql是符合Mysql的标准语义规则的并且可以执行的。
优化器首先会解析语法树,然后对SQL进行改写、成本计算、选择索引、执行计划选择…
这块比较核心且复杂,不在此详细介绍。
在这个阶段是自动按照执行计划进行预处理,mysql会计算各个执行方法的最佳时间,最终确定一条执行的sql交给最后的执行器
相关知识
1、SQL查询成本组成
2、优化器优化时,索引的选择
3、数据字典和统计信息
4、优化器配置
5、RBO(Rule-Based Optimization) 基于规则的优化器
6、CBO(Cost-Based Optimization) 基于代价(成本)的优化器
5.执行器
1、首先判断数据是否在 db buffer 存在,如果存在且可用,则直接获取该数据而不是从数据库文件中去查询数据,同时根据 LRU 算法增加其访问计数。
2、若数据不在缓冲区中,则服务器进程将从数据库文件中查询相关数据,并把这些数据放入到数据缓冲区中(buffer cache)。
若数据存在于 db buffer,其可用性检查方式为:查看 db buffer 块的头部是否有事务,
1、如果有事务,则从回滚段中读取数据。
2、如果没有事务,则比较 select 的 scn 和 db buffer 块头部的 scn。
如果前者小于后者,仍然要从回滚段中读取数据;
如果前者大于后者,说明这是一非脏缓存,可以直接读取这个 db buffer 块的中内容。
在执行完以后会将具体的操作记录到 binlog 中,需要注意的一点是: **select不会记录到binlog中,**只有updat、delete、insert 才会记录到 binlog 中。而 update 会采用两阶段提交的方式,记录到 redolog 中。
6.返回结果
Query请求完成后,将结果集返回给连接的进/线程模块 (返回的也可以是相应的状态标识,如成功或失败等), 连接进/线程模块 进行后续的清理工作,并继续等待请求或断开与客户端的连接。
总结
1、客户端对Mysql建立连接,超时自动关闭。
2、查询缓存(效率高但命中率低,8.0已取消)。
3、SQL分析器构造语法树交由优化器处理。
4、查询优化器根据配置优化出一条它认为的最佳sql,交给执行器处理。
5、执行器执行SQL语句。
6、返回结果集或对应标识。


















 5492
5492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









