







题目:
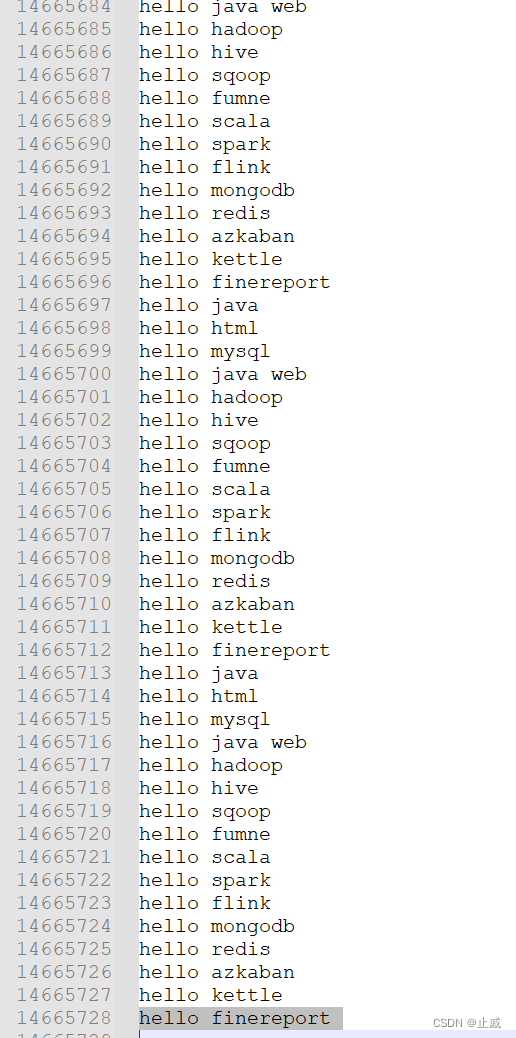
自己创建一个txt文本,按下图形式输入多行单词,不同单词之间用空格隔开,最后要求统计各单词出现的次数。
第一种方式:单线程
import java.io.*;
import java.util.Map;
import java.util.TreeMap;
public class WordCountTest {
public static void main(String[] args) {
//记录运行起始时间;System.currentTimeMillis()记录当前系统时间,单位:ms
long start = System.currentTimeMillis();
FileReader fr=null;
BufferedReader br=null;
//我们需要以键值对的形式来存放单词(key)及其出现的次数(value)
//1、TreeMap中所有元素都是有某一固定的顺序的,如果需要得到一个有序的结果,应选择TreeMap;HashMap中的元素是没有顺序的
//2、HashMap和TreeMap都不是线程安全的;
//3、HashMap继承AbstractMap类;覆盖了hashcode() 和equals() 方法,以确保两个相等的映射返回相同的哈希值;
//TreeMap继承SortedMap类;他保持键的有序顺序;
//4、HashMap:基于hash表实现的;使用HashMap要求添加的键类明确定义了hashcode() 和equals() (可以重写该方法);为了优化HashMap的空间使用,可以调优初始容量和负载因子;
//TreeMap:基于红黑树实现的;TreeMap就没有调优选项,因为红黑树总是处于平衡的状态;
//5、HashMap:适用于Map插入,删除,定位元素;
//TreeMap:适用于按自然顺序或自定义顺序遍历键(key);
Map<String, Integer> wordMap = new TreeMap<>();
try {
fr = new FileReader("word.txt");
br = new BufferedReader(fr);//利用BufferedReader的高效率,读取文件内容
String tempStr = "";//定义一个空字符串,用来后面的接受读取的数据
int num = 0;//读取行数
while ((tempStr = br.readLine()) != null) {
String[] splitStr = tempStr.trim().split("\\s");//trim()去掉字符串前尾空格,split按空格分割成若干个String数组
for (int i = 0; i < splitStr.length; i++) {
//判断集合中的关键词(key)部分是否包含数组中的元素;
if (wordMap.containsKey(splitStr[i])) {
//获取对应key的value值并+1,赋值给count;
Integer count = wordMap.get(splitStr[i]) + 1;
//将count值覆盖原有的value值;
wordMap.put(splitStr[i], count);
} else {
//如果集合中没有数组中的元素,就将该数组元素对应的value值计为1;
wordMap.put(splitStr[i], 1);
}
}
}
//增强for遍历集合key,value值
for (String key :
wordMap.keySet()) {
Integer wordNum = wordMap.get(key);
System.out.println(key + "出现的次数为:" + wordNum);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//输出最后运行的总用时,当前系统时间-起始系统时间
long totalTime = System.currentTimeMillis() - start;
System.out.println("运算总时长:" + totalTime + "ms");
}
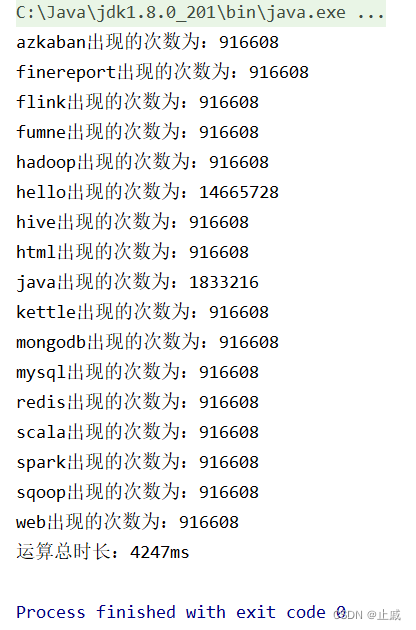
}运行结果:
第二种方式:多线程
第一步:创建一个WordCount1类继承Runnable接口,定义一个Map型的集合map和String类型的空字符串content,重写构造方法,将String类型的变量作为形参,构造体中将传进来的实参初始化成员变量content,并将重写run方法(利用split()方法,将利用trim()方法去除头尾空格的this.content,以空格<"\\s">分成若干个数组,然后判断map中的key是否包含每个数组存放的单词,不包含将该单词作为key,value=1,放进map集合,意思就是该单词就出现了一次;如果key包含该单词,就将其对应的value值加1,value值就是单词出现的次数,对原来的value进行覆盖。最后,遍历单词key值出现次数。)
import java.util.HashMap;
import java.util.Map;
public class WordCount1 implements Runnable{
String content="";
Map<String,Integer>map=new HashMap<>();
public WordCount1(String content){
this.content=content;
}
@Override
public void run() {
String[] splitStr = content.trim().split("\\s");
for (int i = 0; i < splitStr.length; i++) {
if(map.containsKey(splitStr[i])){
Integer count = map.get(splitStr[i]) + 1;
map.put(splitStr[i],count);
}else{
map.put(splitStr[i],1);
}
}
for (String key :
map.keySet()) {
Integer wordNum = map.get(key);
System.out.println(key+"出现的次数为:"+wordNum);
}
}
}第二步:
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class WordCountTest2 {
//定义一个Map集合,key是String类型,value是Map类型;
static Map<String, Map<String,Integer>>threadMap=new TreeMap<>();
public static void main(String[] args) {
//记录起始时间:当前系统时间;
long start = System.currentTimeMillis();
FileReader fr=null;
BufferedReader bf=null;
int lineNum=0;//记录行数
// 线程池:减少资源的浪费,通过ExecutorService获得线程,可以有效的控制最大并发线程数,提高系统资源的使用率
//Executors.newCachedThreadPool(),创建的都是非核心线程,最大线程数为Interge的最大值空闲线程存活时间是1分钟。如果有大量耗时的任务,则不适该创建方式。它只适用于生命周期短的任务。
ExecutorService executorService = Executors.newCachedThreadPool();
try {
fr=new FileReader("word.txt");
bf=new BufferedReader(fr);
StringBuffer listStrBuf = new StringBuffer();
String lineStr="";
while ((lineStr=bf.readLine())!=null){
listStrBuf.append(lineStr+" ");//让空的listStrBuf后面追加,读取的字符串,字符串之间以空格分开;
lineNum++;//每加一次,行号加1;
if(lineNum%1000==0){//“word.txt”中的1000行数据,为每个线程的工作量,lineNum%1000为每个线程完成次数,等于0的时候,代表一个线程完成一遍统计;
//新建一个线程,将读取的listStrBuf中这一行的数据塞给它,run方法中定义了,记录每个word的方法;
WordCount1 wordCount1 = new WordCount1(listStrBuf.toString());
//记录完毕后,listStrBuf中这一行的数据清空;
listStrBuf.delete(0,listStrBuf.length());
//重新起一个线程;
Thread thread = new Thread(wordCount1);
//提交执行thread的任务;
executorService.execute(thread);
threadMap.put("thread-"+lineNum/1000,wordCount1.map);
//key:"thread-"+lineNum/1000;执行次数
//value:wordCount1.map
}
}
//每个线程的工作量为1000行,最后可能存在不满足一次工作量的情况(体现为listStrBuf不为空),这种情况下,单独统计!
if(listStrBuf.toString().length()>0){
WordCount1 wordCount1 = new WordCount1(listStrBuf.toString());
Thread thread = new Thread((wordCount1));
executorService.execute(thread);
threadMap.put("thread-last",wordCount1.map);
}
System.out.println("读取文件的总行数:"+lineNum);
//到这一步,所有word出现的次数已经统计完毕。
executorService.shutdown();//调用shutdown()方法:则不能再往线程池中添加任何任务,否则将会抛出RejectedExecutionException异常。但是,此时线程池不会立刻退出,直到添加到线程池中的任务都已经处理完成,才会退出。
HashMap<String, Integer> mapResult = new HashMap<>();//创建一个新的集合来存放最终的key:word,value:word的出现的次数;
//********************************************************************************************************************************************************
//将最终结果输出到一个新的txt文本文件中,<最后看这里,前面不用管这里>
FileWriter fw=null;
BufferedWriter bfw=null;
try {
fw=new FileWriter("word2.txt");
bfw=new BufferedWriter(fw);
} catch (IOException e) {
e.printStackTrace();
}
//**********************************************************************************************************************************************************
while (true){
if(executorService.isTerminated()){
for (String key: //thread-1 thread-2...thread-last
threadMap.keySet()) {//增强for,获取threadMap的key值赋值给变量key;
Map<String, Integer> perThreadWordNum = threadMap.get(key);//由于定义的threadMap集合value为Map类型的集合,定义Map类型集合来接受key对应的value值;
Set<String> perThreadWords = perThreadWordNum.keySet();//获取上一步新集合中的key值,String类型,用set集合存放;
Iterator<String> iterator = perThreadWords.iterator();//set无序集合,用迭代或者增强for遍历,将遍历的值用String类型的word变量接收;
while(iterator.hasNext()){
String word = iterator.next();
//判断上面新定义的HashMap类型的集合:mapResult中是否包含【上面遍历threadMap中value里的Map类型的key(set型集合perThreadWords中的元素值)=word】word;
if(mapResult.containsKey(word)){
//如果包含word,将对应word出现的次数记录下来,包含各线程统计的word出现次数:wordsNum和已经统计的word出现次数:haveNum。两者相加为最终word出现次数;
Integer wordsNum = perThreadWordNum.get(word);
Integer haveNum = mapResult.get(word);
mapResult.put(word,wordsNum+haveNum);//相同的word会覆盖value值,key是唯一的;
}else{
mapResult.put(word,perThreadWordNum.get(word));
//如果mapResult中没有word,将word作为key值,各线程统计的次数作为value值赋值存入mapResult集合;
}
}
}
Set<String> resultwords = mapResult.keySet();
for (String word :
resultwords) {
System.out.println(word + ":" + mapResult.get(word));
bfw.append(word+"总共出现了"+ mapResult.get(word)+"次");
bfw.newLine();
bfw.flush();
}
break;
}
}
bfw.close();
fw.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
long totalTime = System.currentTimeMillis() - start;
System.out.println("运算总时长:"+totalTime+"ms");
}
}
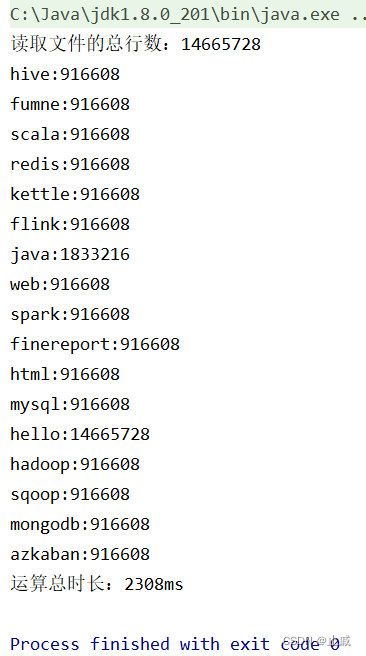
运行结果:
附加题:将上述运算结果统计到一个新的txt文本中。
运行结果: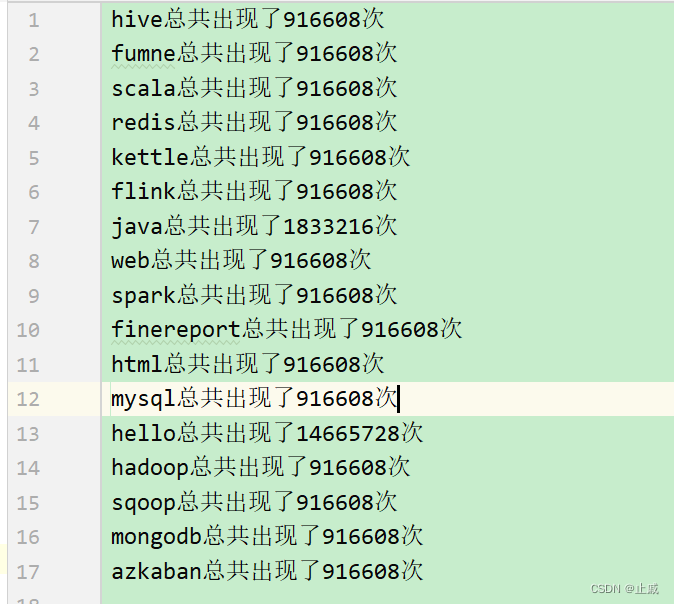
总结:
在数据量足够多的情况下,多线程的方式明显比单线程的方式运算速度快;但不是线程越多越好,处于中间值最好。一般数据量少的,单线程就能搞定,多线程部署太烦了。

















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









