






Hadoop集群完全分布式运行环境搭建
文章目录
- Hadoop集群完全分布式运行环境搭建
- 一、初始机搭建 VMare安装虚拟机
- 1.1 新建虚拟机
- 1.2 新建虚拟机向导
- 1.3 稍后安装操作系统
- 1.4 选择Linux系统对应的CentOS版本
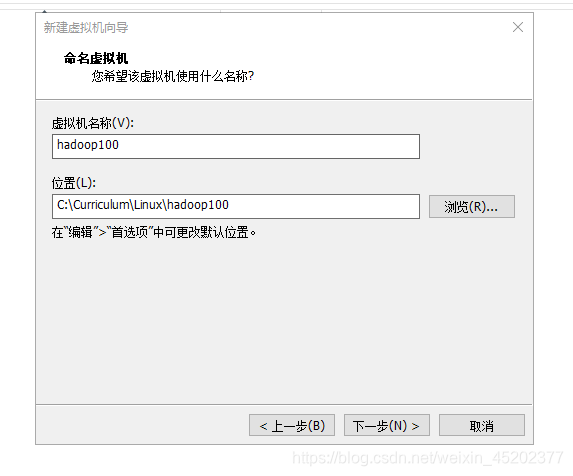
- 1.5 自定义虚拟机名称和安装目录
- 1.6 自定义配置
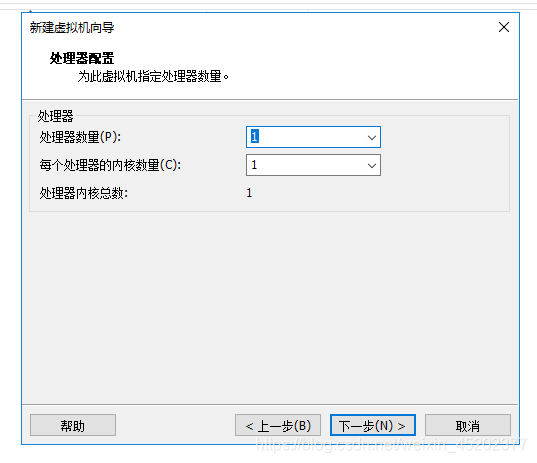
- 1.7 自定义虚拟机内存配置
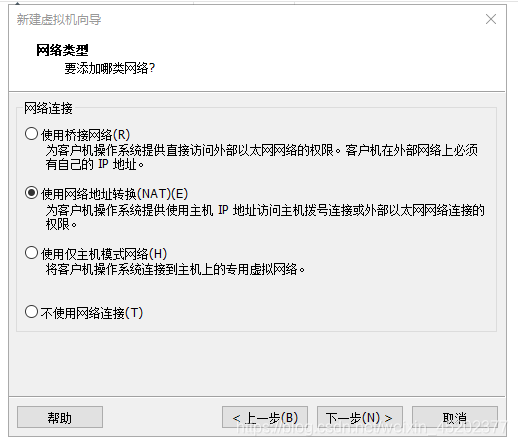
- 1.8 网络选择NAT
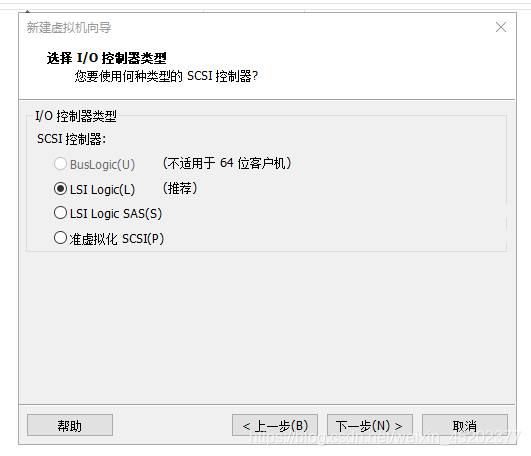
- 1.9 选择IO控制器类型
- 1.10 选择磁盘类型
- 1.11 新建虚拟磁盘
- 1.12 设置磁盘容量
- 1.13 默认磁盘文件
- 1.14 点击完成
- 1.15 点击 虚拟机 - 设置
- 1.16 启动虚拟机
- 1.17 选择第一项
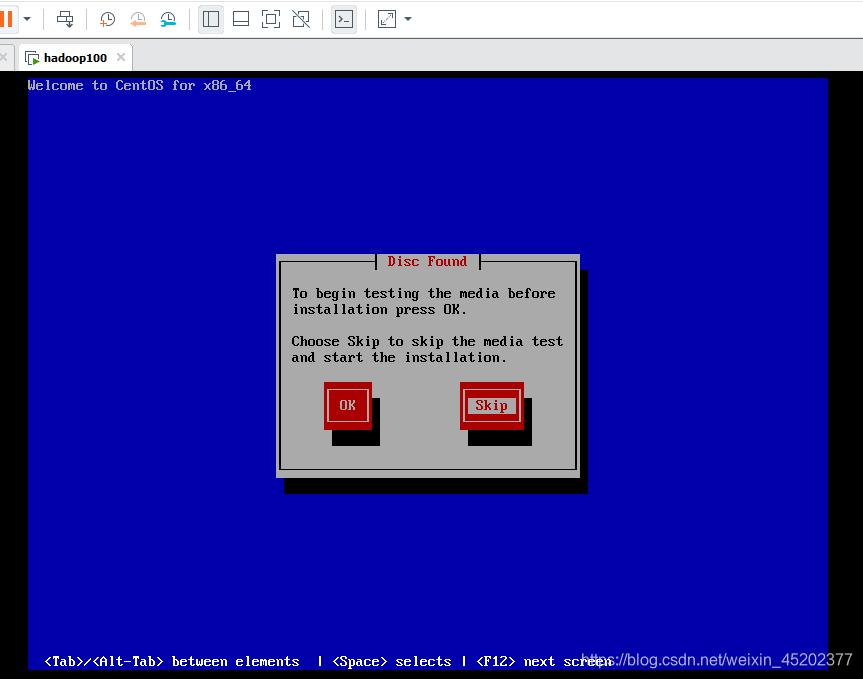
- 1.18 选择 Skip
- 1.19 CentOS欢迎页面,直接点击Next
- 1.20 选择简体中文进行安装
- 1.21 选择语言键盘
- 1.22 选择存储设备
- 1.23 给计算机命名
- 1.24 选择时区
- 1.25 设置root密码
- 1.26 硬盘分区
- 1.27 根分区新建
- 1.28 定制系统软件
- 1.29 语言支持
- 1.30 完成配置,开始安装CentOS
- 1.31 安装完成,重新引导
- 1.32 启动项配置
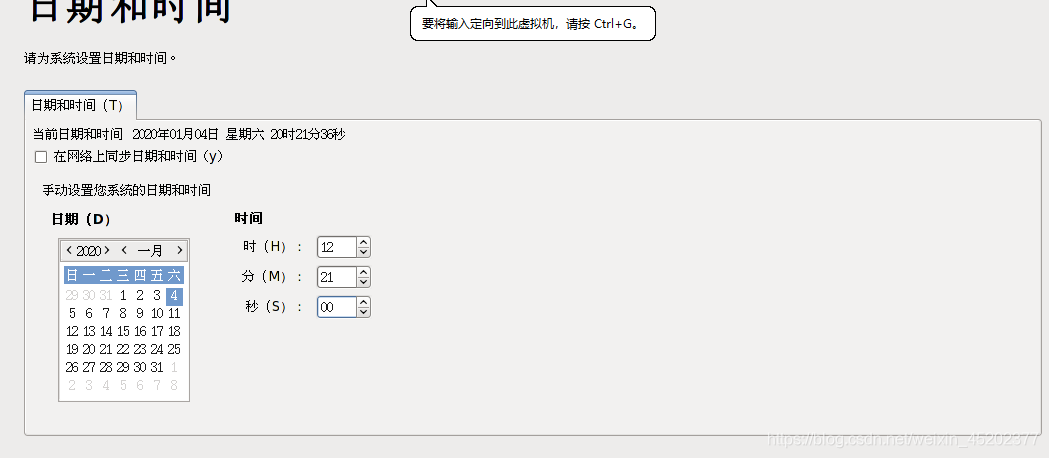
- 1.33 系统时间设置
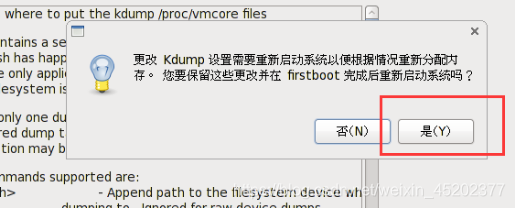
- 1.34 Kdump去掉
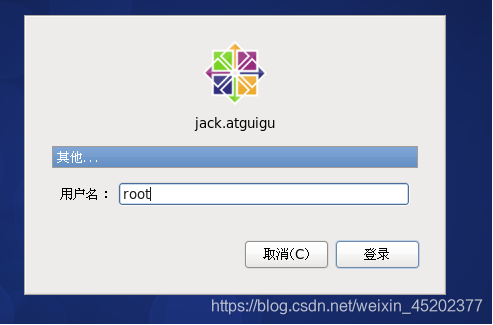
- 1.35 全部配置完成
- 二、初始机网络配置
- 三、hadoop集群机器搭建 - apache模式
软件版本
VMware-workstation-full-15.1.0
CentOS-6.8-x86_64-bin
jdk-8u144-linux-x64.tar
hadoop-2.7.2
一、初始机搭建 VMare安装虚拟机
1.1 新建虚拟机
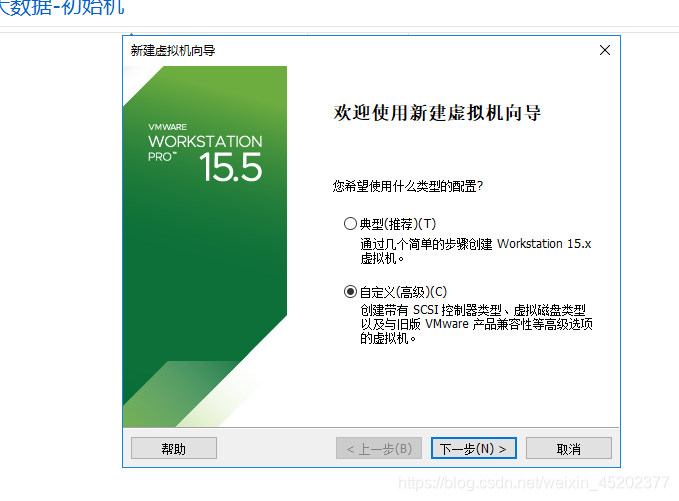
1.2 新建虚拟机向导
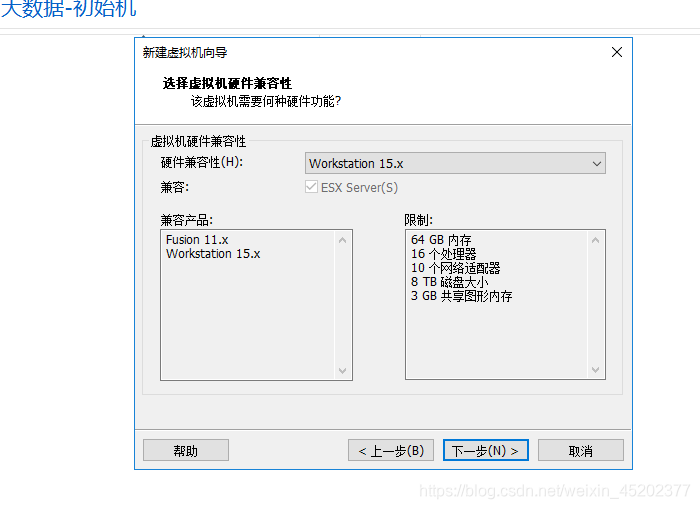
1.3 稍后安装操作系统
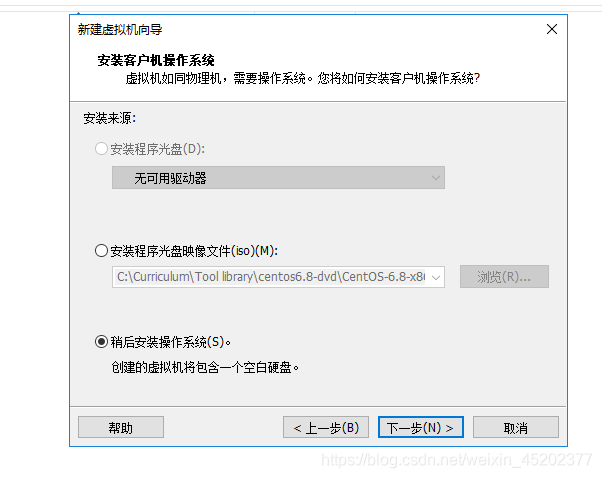
1.4 选择Linux系统对应的CentOS版本
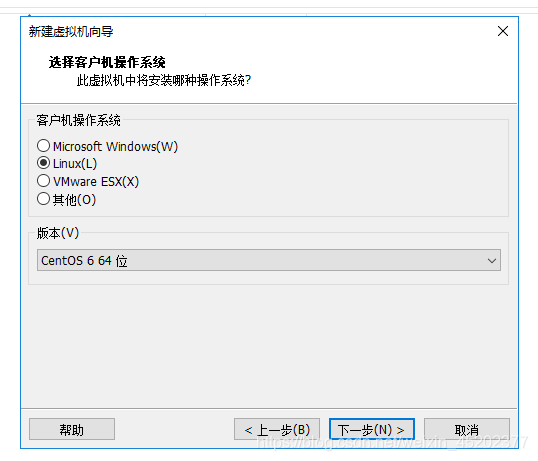
1.5 自定义虚拟机名称和安装目录
1.6 自定义配置
1.7 自定义虚拟机内存配置
默认使用推荐内存1G 不要使用512M,会在安装时出现错误
1.8 网络选择NAT
1.9 选择IO控制器类型
1.10 选择磁盘类型
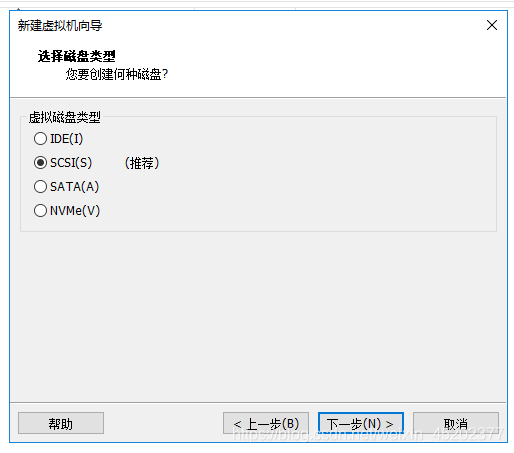
1.11 新建虚拟磁盘
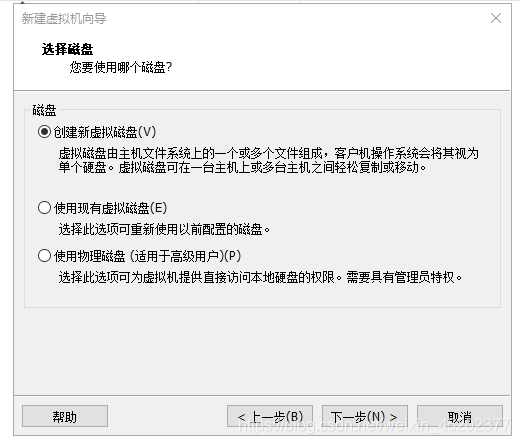
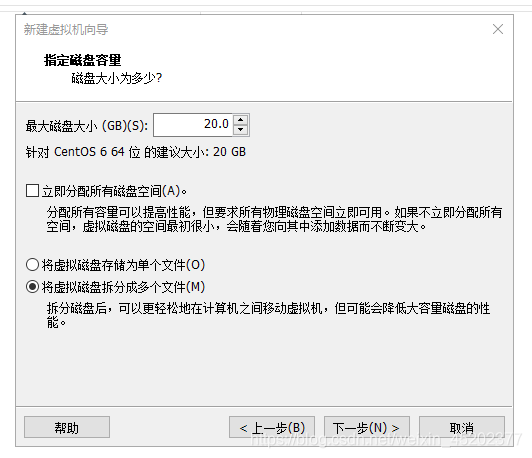
1.12 设置磁盘容量
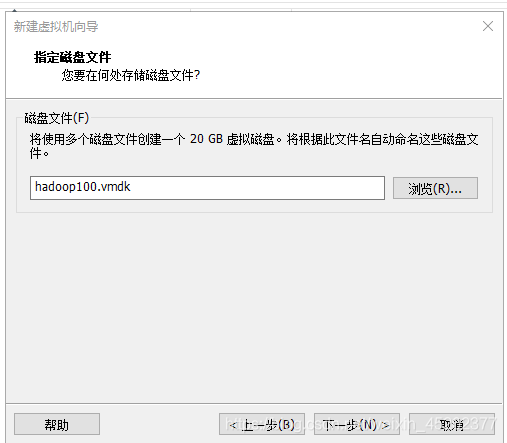
1.13 默认磁盘文件
1.14 点击完成
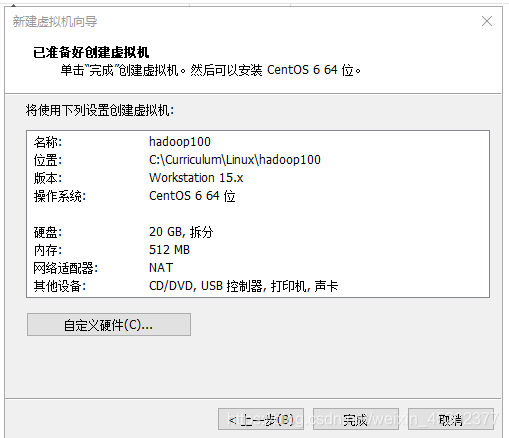
1.15 点击 虚拟机 - 设置
设备状态:启动时链接
使用自定义下载的ISO文件
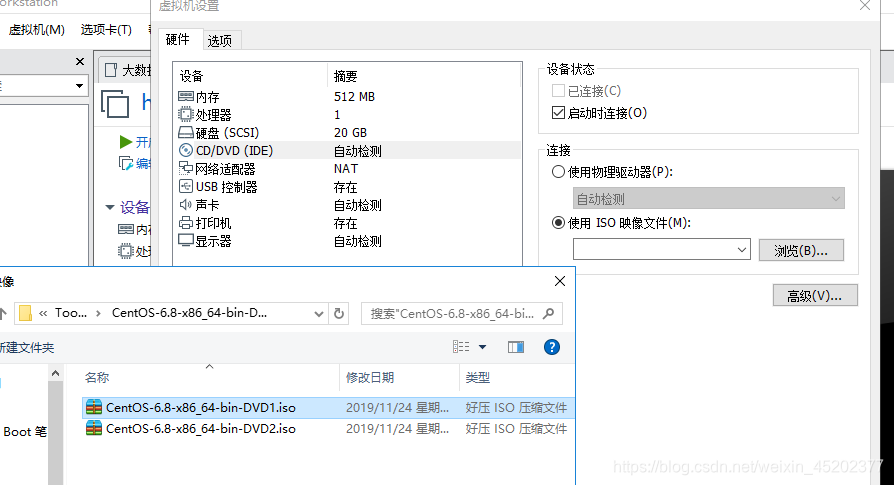
1.16 启动虚拟机
1.17 选择第一项
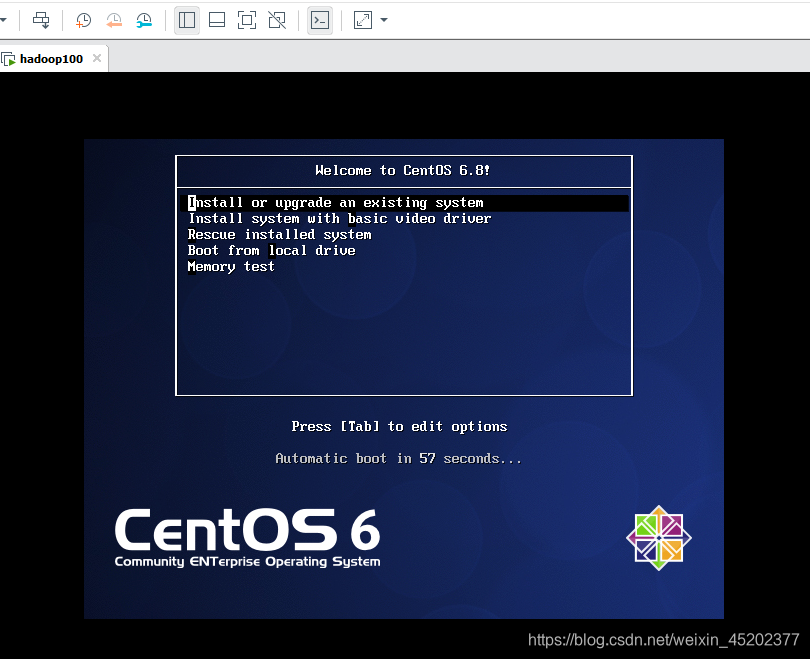
1.18 选择 Skip
1.19 CentOS欢迎页面,直接点击Next

1.20 选择简体中文进行安装
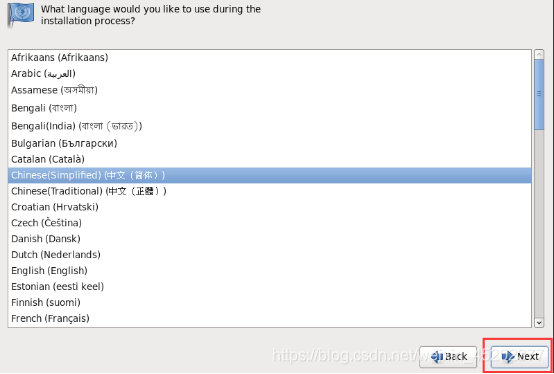
1.21 选择语言键盘
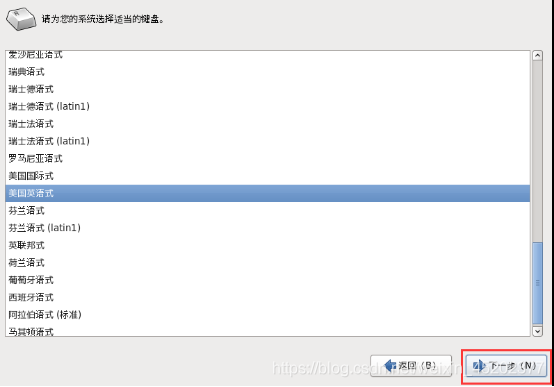
1.22 选择存储设备

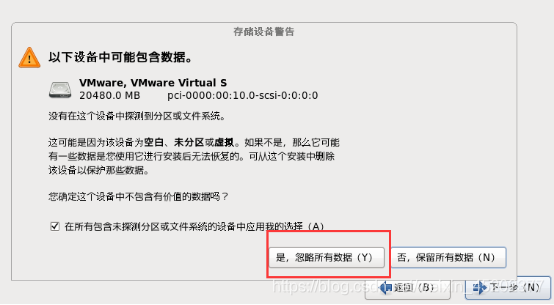
1.23 给计算机命名
这里先不要配置网络,安装完成后再设置,这里手滑多写一个Q
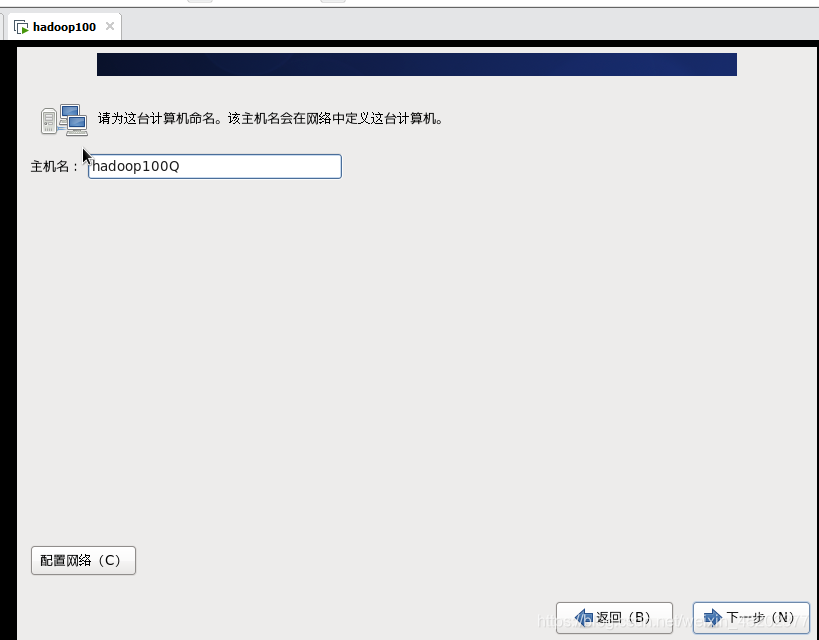
1.24 选择时区
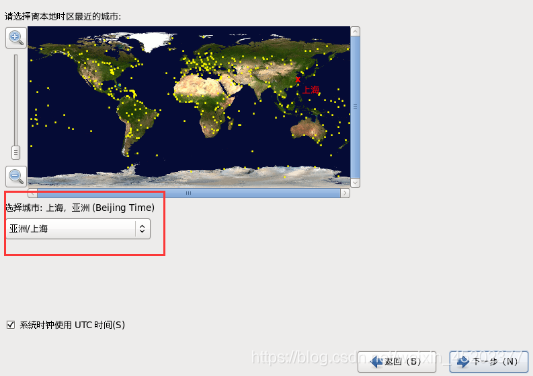
1.25 设置root密码
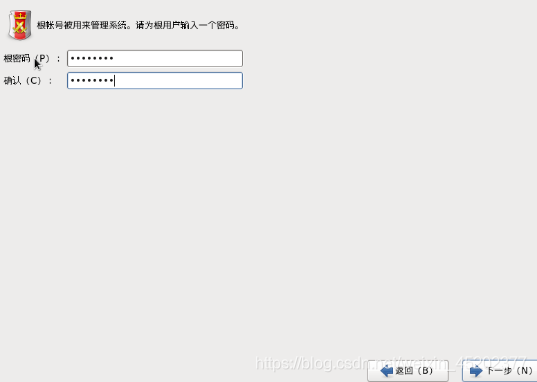
1.26 硬盘分区
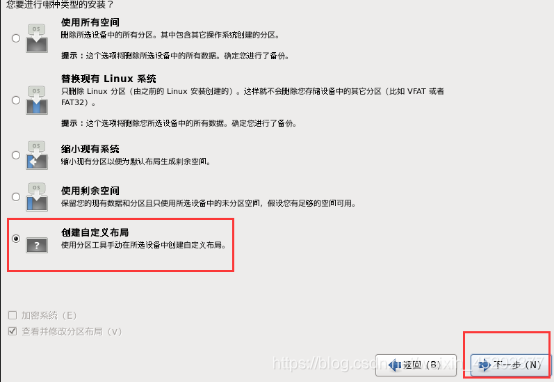
1.27 根分区新建

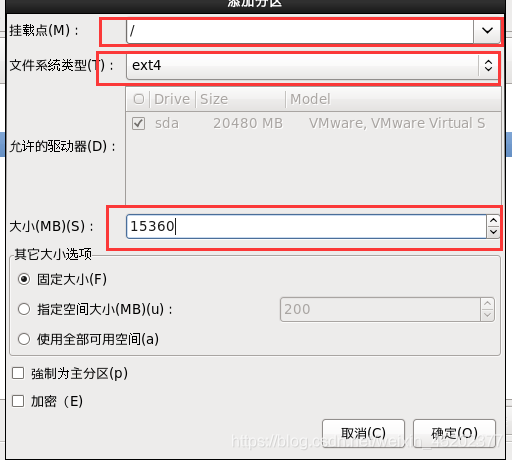
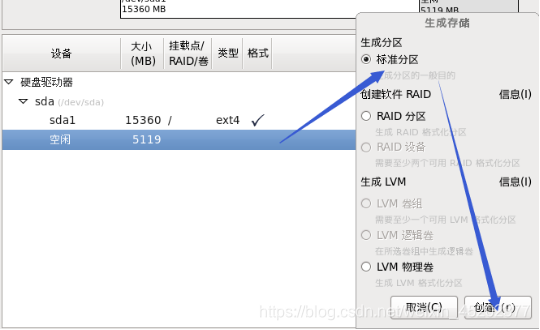
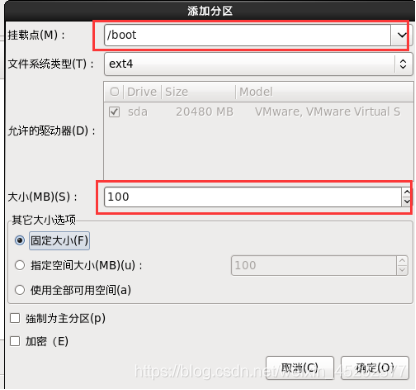
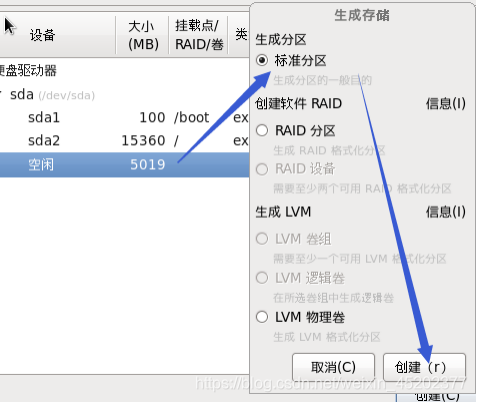
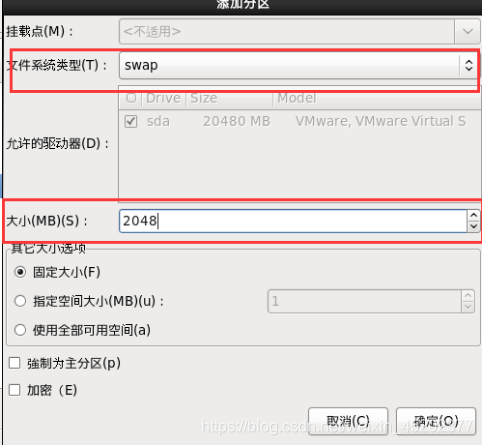
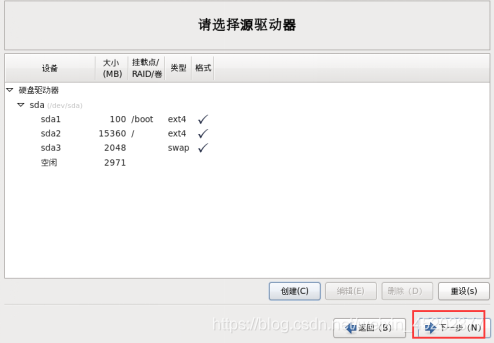
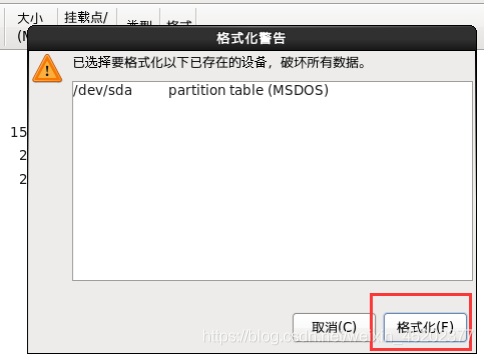
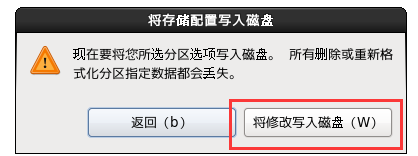
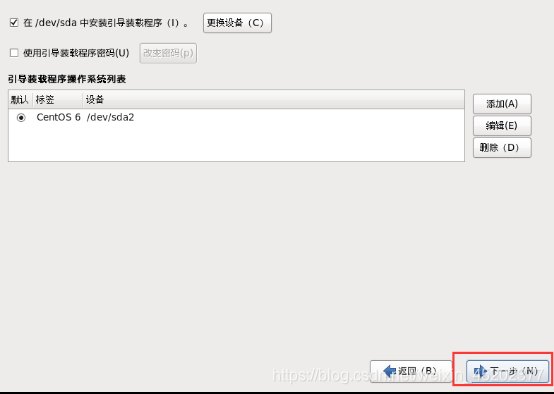
1.28 定制系统软件
因为该centos版本不是MINI版本,可以自定义系统软件,不过建议还是什么都不要定制,需要什么启动虚拟机自己安装
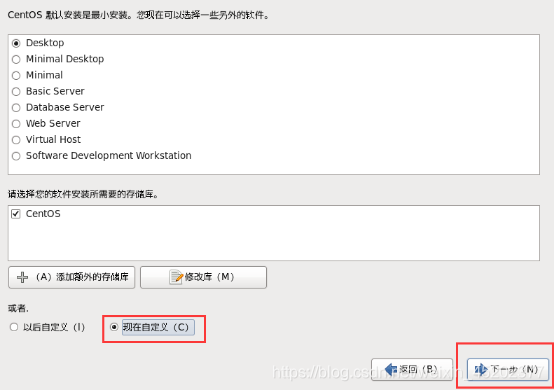
1.29 语言支持
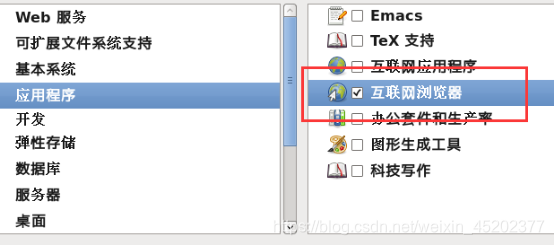
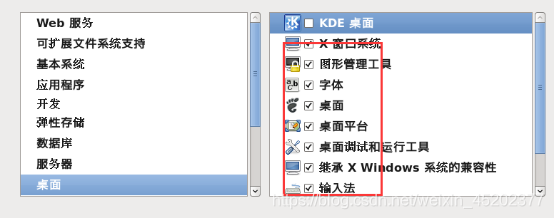
1.30 完成配置,开始安装CentOS
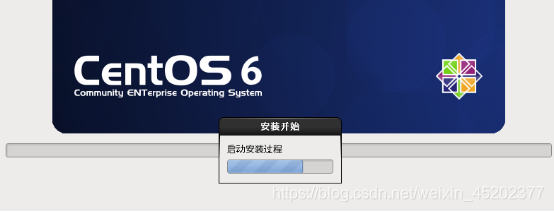
1.31 安装完成,重新引导
1.32 启动项配置


1.33 系统时间设置
可开启在网络上同步日期和时间,或者手动调整时间,或者另行配置时间同步
1.34 Kdump去掉
如果默认没有开启 则不用管

1.35 全部配置完成
重启后用root登陆
二、初始机网络配置
2.1 查看虚拟网络编辑器
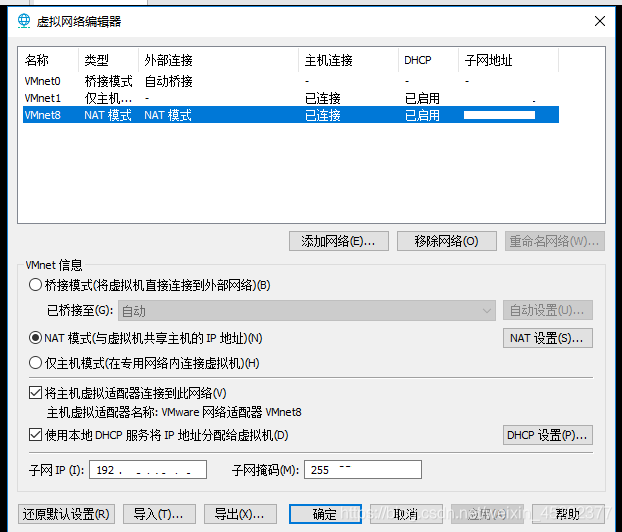
2.2 修改Ip地址
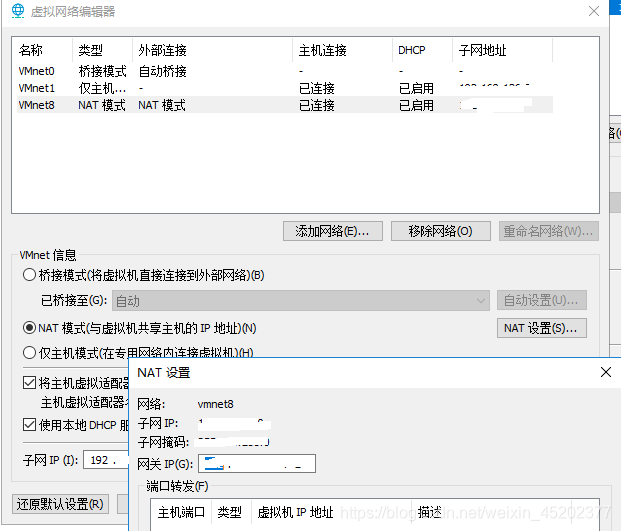
2.3 查看网关
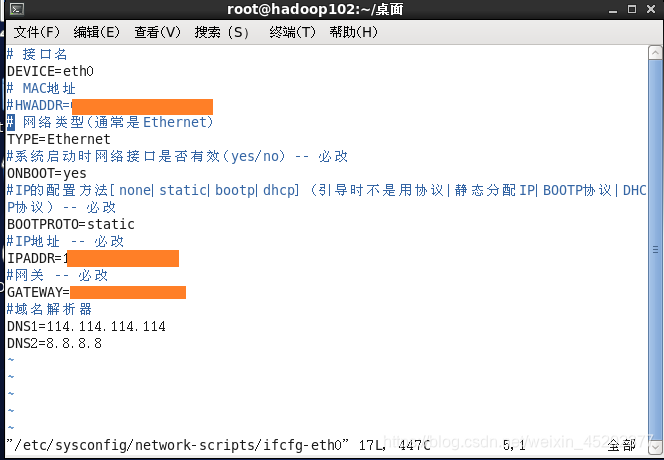
2.4 配置网络ip地址
- 修改IP地址(注释掉MAC地址)

2. 执行
service network restart

2.5 配置主机名
查看当前服务器主机名称
[root@hadoop100 ~]# hostname
修改hostname
[root@hadoop100 ~]$ vim /etc/sysconfig/network
2.6 配置host
[root@hadoop100 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.xx.xx.100 hadoop100
192.xx.xx.101 hadoop101
192.xx.xx.102 hadoop102
192.xx.xx.103 hadoop103
192.xx.xx.104 hadoop104
2.7 windows机器增加hosts
-
进入C:\Windows\System32\drivers\etc路径
-
打开hosts文件并添加如下内容
192.xx.xx.100 hadoop100 192.xx.xx.101 hadoop101 192.xx.xx.102 hadoop102 192.xx.xx.103 hadoop103 192.xx.xx.104 hadoop104
2.8 关闭防火墙和开机自启动
- 查看网络服务的状态
[root@hadoop100 ~]#service iptables status
- 停止网络服务
[root@hadoop100 ~]#service iptables stop
[root@hadoop100 ~]# service iptables stop
iptables:将链设置为政策 ACCEPT:filter [确定]
iptables:清除防火墙规则: [确定]
iptables:正在卸载模块: [确定]
[root@hadoop100 ~]# chkconfig iptables off
- 查看系统中所有的后台服务
[root@hadoop100 ~]#service --status-all
- 关闭iptables服务的开机自启动
[root@hadoop100 ~]#chkconfig iptables off
- 开启iptables服务的开机自启动
[root@hadoop100 ~]#chkconfig iptables on
三、hadoop集群机器搭建 - apache模式
3.1 初始机克隆3台虚拟机
3.2 配置网络,修改主机名,修改Host,权限
三台机器分别调整:
- 修改ip地址
[enzo@hadoop100 ~]$ vim /etc/sysconfig/network-scripts/ifcfg-eth0
- 修改主机名
[enzo@hadoop100 ~]$ vim /etc/sysconfig/network
- 修改网络配置文件
[enzo@hadoop100 ~]$ vim /etc/udev/rules.d/70-persistent-net.rules
删除第一个 eth0 文件,将eth1 改名为 eth0
- reboot重启
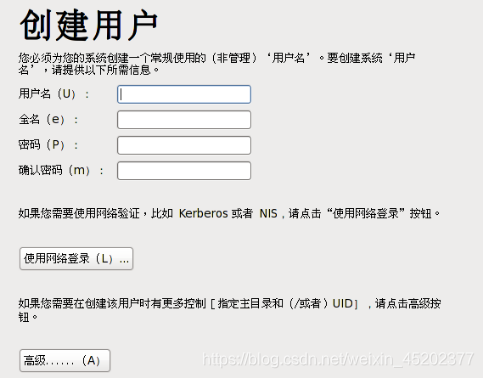
- 账户配置具有root权限
[root@hadoop102 ~]$ vim /etc/sudoers
在root ALL=(ALL) ALL 下面 增加
enzo ALL=(ALL) NOPASSWD:ALL
- 账户授权
[enzo@hadoop102 ~]$ mkdir -p /opt/module
mkdir: 无法创建目录"/opt/module": 权限不够
[enzo@hadoop102 ~]$ sudo mkdir -p /opt/module
[enzo@hadoop102 ~]$ sudo mkdir -p /opt/software
[enzo@hadoop102 ~]$ cd /opt/
[enzo@hadoop102 opt]$ ll
总用量 12
drwxr-xr-x. 2 root root 4096 1月 4 17:02 module
drwxr-xr-x. 2 root root 4096 3月 26 2015 rh
drwxr-xr-x. 2 root root 4096 1月 4 17:02 software
[enzo@hadoop102 opt]$ rm -rf rh/
rm: 无法删除"rh": 权限不够
[enzo@hadoop102 opt]$ sudo rm -rf rh/
[enzo@hadoop102 opt]$ sudo chown enzo:enzo module/ software/
[enzo@hadoop102 opt]$ ll
总用量 8
drwxr-xr-x. 2 enzo enzo 4096 1月 4 17:02 module
drwxr-xr-x. 2 enzo enzo 4096 1月 4 17:02 software
3.2 集群规划
| hadoop102 8G | hadoop 2G | hadoop 4G | |
|---|---|---|---|
| HDFS | NameNode | DataNode | DataNode |
| DataNode | SecondaryNameNode | ||
| YARN | NodeManager | ResourceManager | NodeManager |
| NodeManager |
3.3 安装JDK
-
卸载现有jdk,如没有默认安装,这里则没有内容展示
[root@hadoop102 enzo]# rpm -qa|grep java tzdata-java-2016c-1.el6.noarch java-1.6.0-openjdk-1.6.0.38-1.13.10.4.el6.x86_64 java-1.7.0-openjdk-1.7.0.99-2.6.5.1.el6.x86_64卸载命令
sudo rpm -e 软件包查看jdk全装路径
which java -
上传jdk
上传jdk-8u144-linux-x64.tar.gz到/opt/software目录
-
解压到/opt/module目录
[enzo@hadoop102 software]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/ -
配置JDK环境变量
获取jdk路径 [enzo@hadoop102 jdk1.8.0_144]$ pwd /opt/module/jdk1.8.0_144 修改/etc/profile文件 [enzo@hadoop102 jdk1.8.0_144]$ sudo vim /etc/profile 文件末尾增加 #JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_144 export PATH=$PATH:$JAVA_HOME/bin 使配置生效 [enzo@hadoop102 jdk1.8.0_144]$ source /etc/profile 验证版本 [enzo@hadoop102 jdk1.8.0_144]$ java -version java version "1.8.0_144" Java(TM) SE Runtime Environment (build 1.8.0_144-b01) Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
3.4 安装Hadoop
-
上传hadoop-2.7.2.tar.gz到 /opt/software
-
解压到/opt/module
-
配置hadoop环境变量
-
注意用户权限
[enzo@hadoop102 hadoop-2.7.2]$ pwd /opt/module/hadoop-2.7.2 [enzo@hadoop102 hadoop-2.7.2]$ sudo vim /etc/profile 在profile文件末尾增加 #HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-2.7.2 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin 使配置生效 [enzo@hadoop102 hadoop-2.7.2]$ source /etc/profile 验证版本 [enzo@hadoop102 hadoop-2.7.2]$ hadoop version Hadoop 2.7.2 Subversion Unknown -r Unknown Compiled by root on 2017-05-22T10:49Z Compiled with protoc 2.5.0 From source with checksum d0fda26633fa762bff87ec759ebe689c This command was run using /opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2.jar
3.5 配置集群
-
配置core-site.xml
<configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property> </configuration> -
配置hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144 -
配置hdfs-site.xml
<!-- 生产上是3个副本 本地使用 就放1个 --> <property> <name>dfs.replication</name> <value>1</value> </property> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:50090</value> </property> -
配置yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144 -
配置yarn-site.xml
<!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> -
配置mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144 -
配置mapred-site.xml 将mapred-site.xml.template 重命名为 mapred-site.xml
<!-- 指定MR运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> -
slaves文件修改, 注意不能有空格 回车等
hadoop102 hadoop103 hadoop104
3.6 编写集群分发脚本
两种拷贝方式: scp 和 rsync
scp 实现服务器与服务器之间的数据拷贝
scp -r p d i r / pdir/ pdir/fname u s e r @ h a d o o p user@hadoop user@hadoophost: p d i r / pdir/ pdir/fname
命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点
rsync -rvl p d i r / pdir/ pdir/fname u s e r @ h a d o o p user@hadoop user@hadoophost: p d i r / pdir/ pdir/fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
sync和scp区别:
-
用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新
-
scp是把所有文件都复制过去
xsync脚本: 循环复制文件到所有节点的相同目录下,将该脚本放在/home/enzo/bin目录下,enzo用户可以在系统的任何位置直接执行脚本
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=103; host<105; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
修改脚本xsync具有执行权限
[enzo@hadoop102 bin]$ chmod 777 xsync
3.7 ssh免密登陆
[enzo@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
[enzo@hadoop102 ~]$ cd .ssh/
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
[enzo@hadoop102 .ssh]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/enzo/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/enzo/.ssh/id_rsa.
Your public key has been saved in /home/enzo/.ssh/id_rsa.pub.
The key fingerprint is:
f0:60:62:3d:0f:f1:bd:20:99:77:1c:36:5f:37:ac:02 enzo@hadoop102
The key's randomart image is:
+--[ RSA 2048]----+
| . + o..|
| . = E + . o.|
| o @ + = . . |
| . o X o o . |
| S . . |
| |
| |
| |
| |
+-----------------+
将公钥拷贝到要免密登录的目标机器上
[enzo@hadoop102 .ssh]$ ssh-copy-id hadoop102
[enzo@hadoop102 .ssh]$ ssh-copy-id hadoop103
[enzo@hadoop102 .ssh]$ ssh-copy-id hadoop104
因为这里的hadoop103上有yarn,所以免密在103上也执行一遍
3.8 集群内容同步
通过xsync脚本和scp方式同步以上更新的全部内容及文件,注意用户权限和授权
同步/etc/profile
[enzo@hadoop102 ~]$ sudo scp /etc/profile root@hadoop103:/etc/profile
[enzo@hadoop102 ~]$ sudo scp /etc/profile root@hadoop104:/etc/profile
同步/opt
[enzo@hadoop102 ~]$ xsync /opt/
3.9 集群时间同步
如果当前虚拟机时间没有问题,则不用修改
-
主机检查ntp是否安装
[root@hadoop102 enzo]# rpm -qa|grep ntp fontpackages-filesystem-1.41-1.1.el6.noarch ntpdate-4.2.6p5-10.el6.centos.x86_64 ntp-4.2.6p5-10.el6.centos.x86_64 -
主机修改ntp配置文件
[root@hadoop102 enzo]# vim /etc/ntp.conf 修改内容如下 修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间) #restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为 restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap 修改2(集群在局域网中,不使用其他互联网上的时间) server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst为 #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst 添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步) server 127.127.1.0 fudge 127.127.1.0 stratum 10 [root@hadoop102 enzo]# vim /etc/sysconfig/ntpd 增加内容如下(让硬件时间与系统时间一起同步) SYNC_HWCLOCK=yes 重新启动ntpd服务 [root@hadoop102 enzo]# service ntpd status ntpd 已停 [root@hadoop102 enzo]# service ntpd start 正在启动 ntpd: [确定] 设置ntpd服务开机启动 [root@hadoop102 enzo]# chkconfig ntpd on -
从机同步时间
[root@hadoop103 enzo]# crontab -e
编写定时任务如下:
每十分钟从hadoop102同步一次时间
*/10 * * * * /usr/sbin/ntpdate hadoop102
-
以上内容是三台集群中 其他从机同步主机时间
主机同步网络时间配置参考
3.10 启动集群
-
第一次启动集群,需要格式化namenode
如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据) [enzo@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -format -
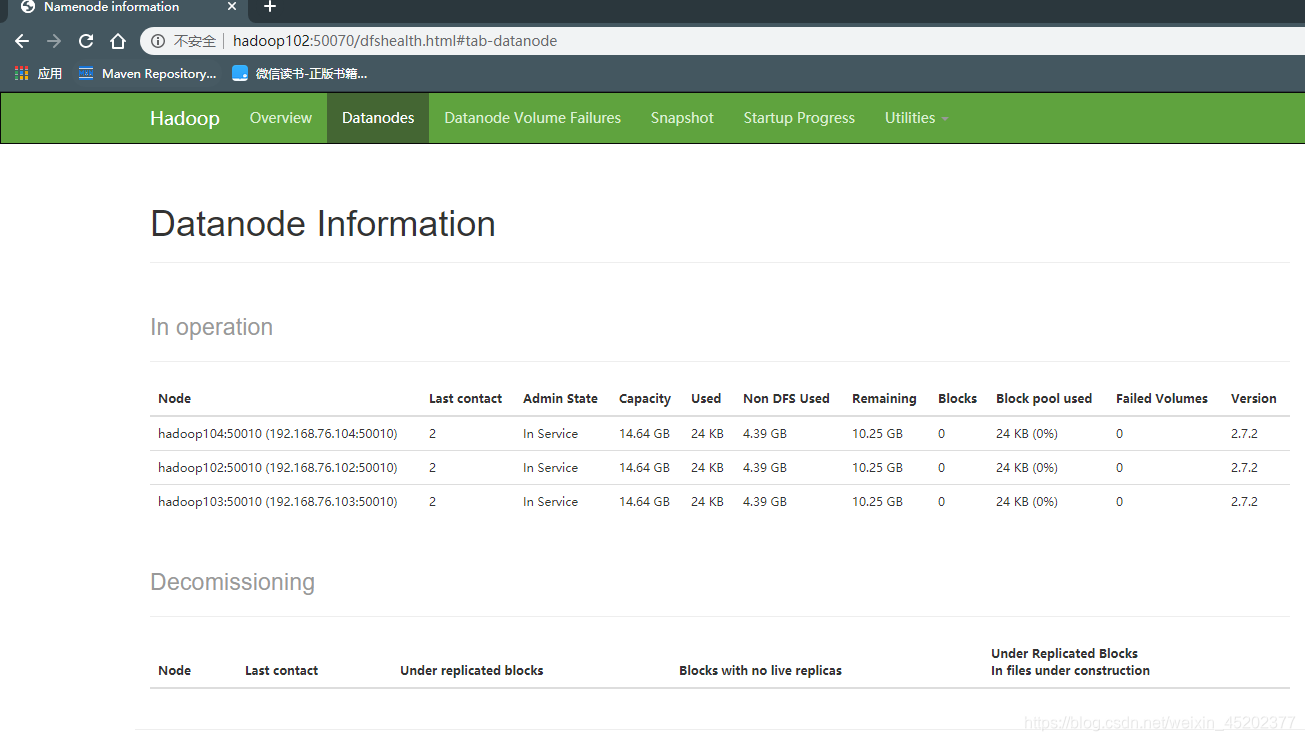
启动HDFS
[enzo@hadoop102 ~]$ start-dfs.sh Starting namenodes on [hadoop102] hadoop102: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-enzo-namenode-hadoop102.out hadoop103: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-enzo-datanode-hadoop103.out hadoop102: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-enzo-datanode-hadoop102.out hadoop104: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-enzo-datanode-hadoop104.out Starting secondary namenodes [hadoop104] hadoop104: starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-enzo-secondarynamenode-hadoop104.out [enzo@hadoop102 ~]$ jps 2934 NameNode 3273 Jps 3035 DataNode [enzo@hadoop103 ~]$ jps 2503 DataNode 2574 Jps [enzo@hadoop104 hadoop]$ jps 2662 Jps 2475 DataNode 2574 SecondaryNameNode浏览器输入ip地址:50070 显示集群正常,启动成功
-
启动YARN
[enzo@hadoop103 ~]$ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-enzo-resourcemanager-hadoop103.out hadoop102: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-enzo-nodemanager-hadoop102.out hadoop104: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-enzo-nodemanager-hadoop104.out hadoop103: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-enzo-nodemanager-hadoop103. [enzo@hadoop103 ~]$ jps 3174 NodeManager 2951 DataNode 3209 Jps 3070 ResourceManager
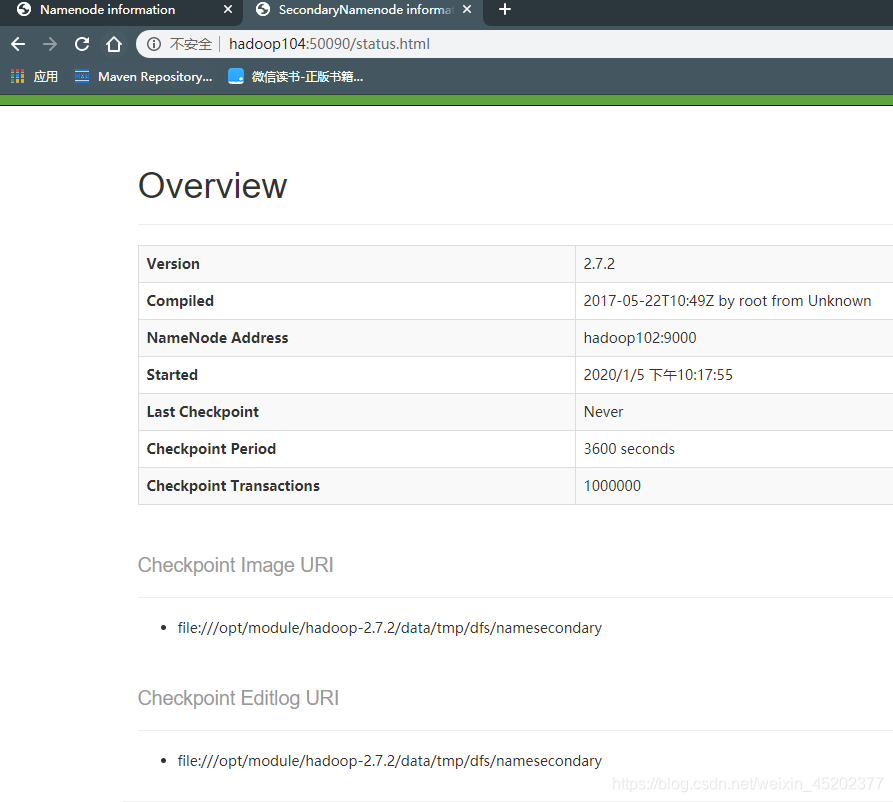
- Web端查看SecondaryNameNode
3.11 集群启动/停止总结
- 各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2)启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
2.各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh / stop-yarn.sh

















 1327
1327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









