






 本文详细介绍了MAE模型的三个关键部分:编码器、基于ViT的patch处理和位置编码,以及随机遮罩的过程。特别提到一个关于遮罩操作的复杂性,解释了遮罩后的特征维度变化。
本文详细介绍了MAE模型的三个关键部分:编码器、基于ViT的patch处理和位置编码,以及随机遮罩的过程。特别提到一个关于遮罩操作的复杂性,解释了遮罩后的特征维度变化。
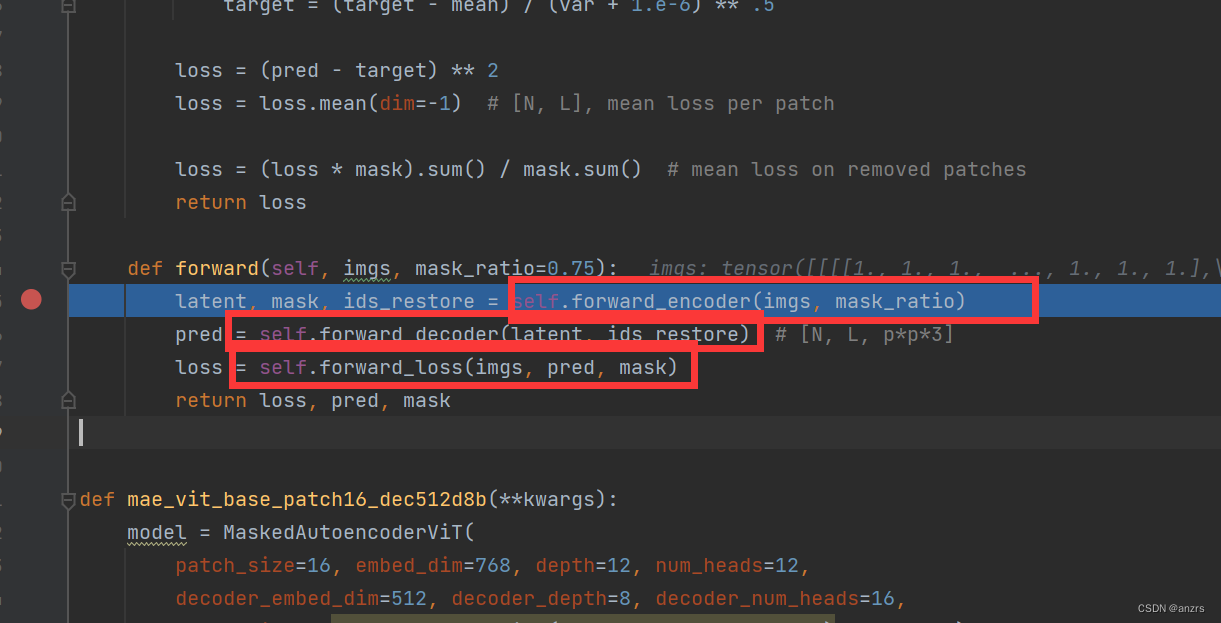
1.可以看到,整个MAE逻辑上很简单,就包括三个部分,(1)encoder(2)decoder(3)forwardloss。让我们看看这三个部分都是什么东西。
2.encoder中learnable的部分,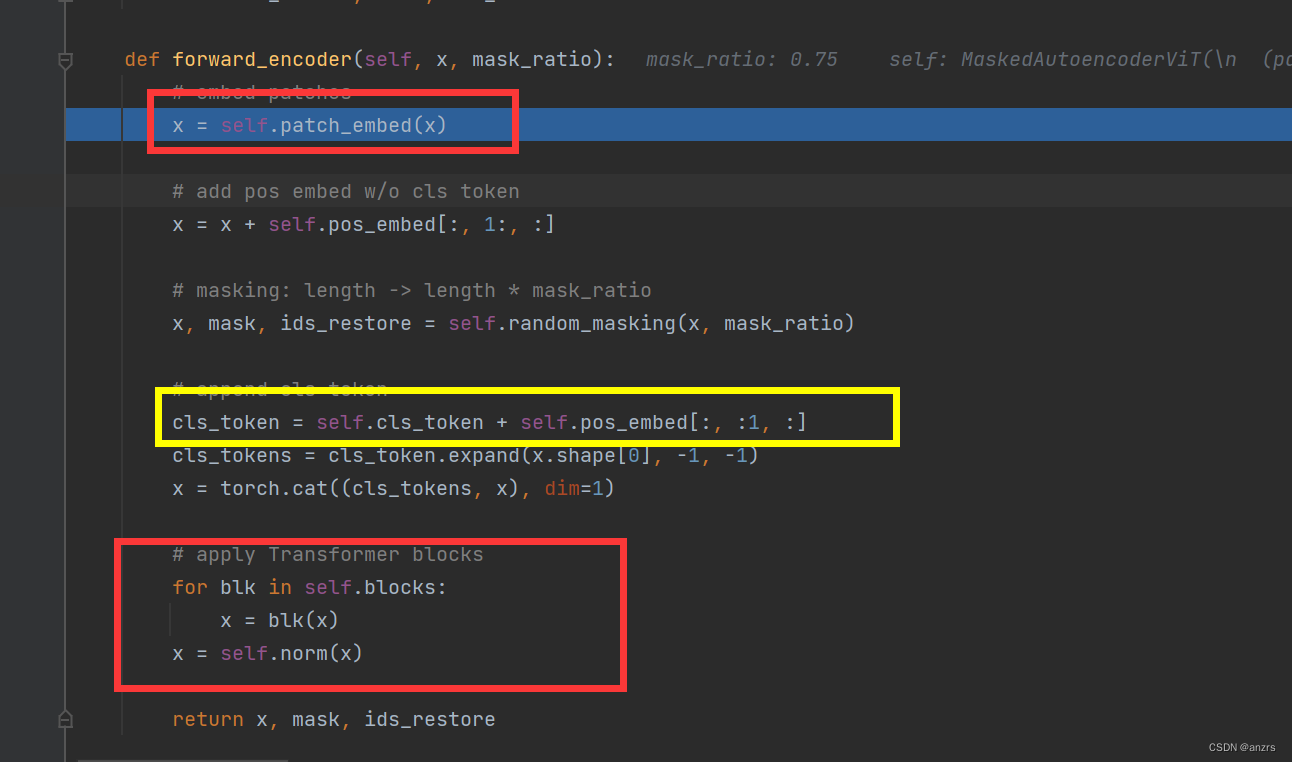 3.这个patch就是标准的vit patch,进入之前图像的尺寸是3,224,224.
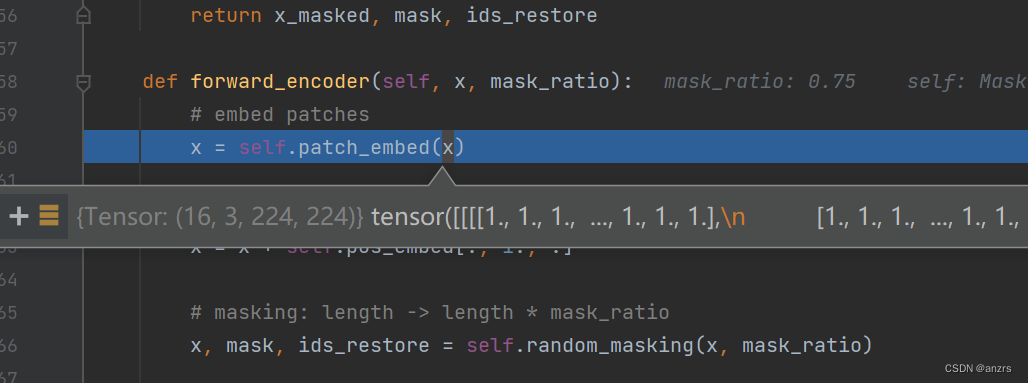
3.这个patch就是标准的vit patch,进入之前图像的尺寸是3,224,224.
4.将三维度的变成二维度的。
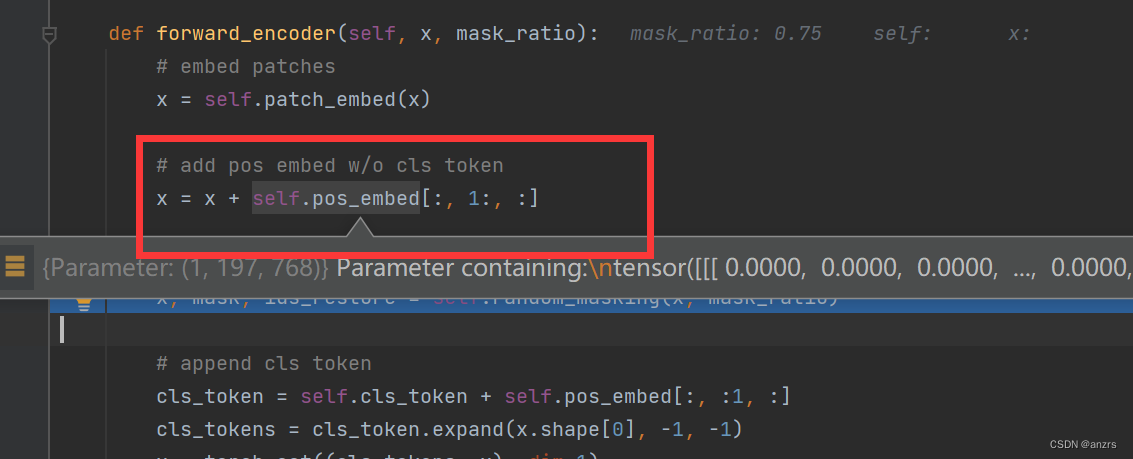
5,将进行patch编码后的img的hidden feature进行添加位置编码。
6.输入进random masking的x,是16,196,768尺寸的,也就是二维的。
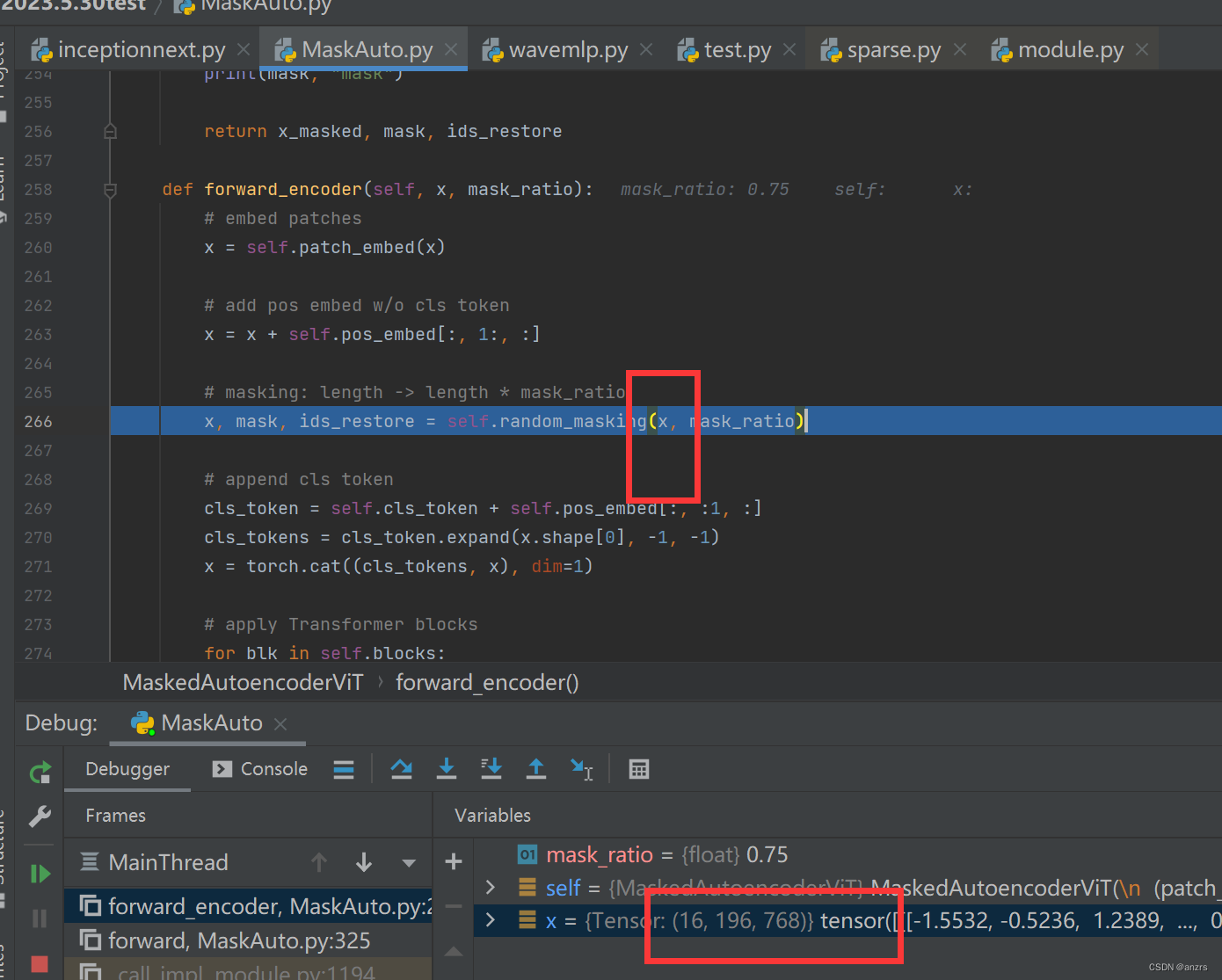
7.下面进进入random,mask了,可以看到进入的尺寸是16,196,768。
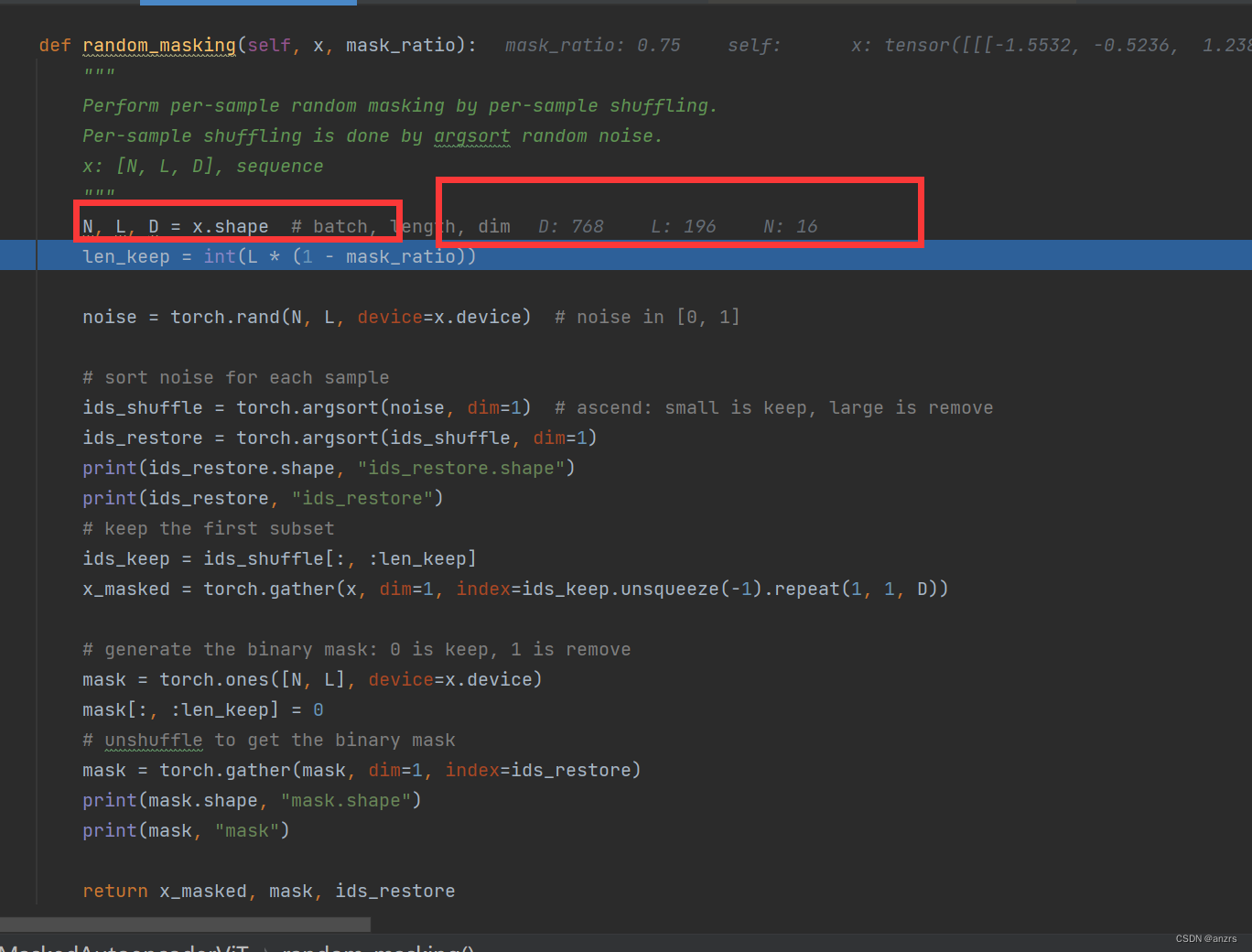
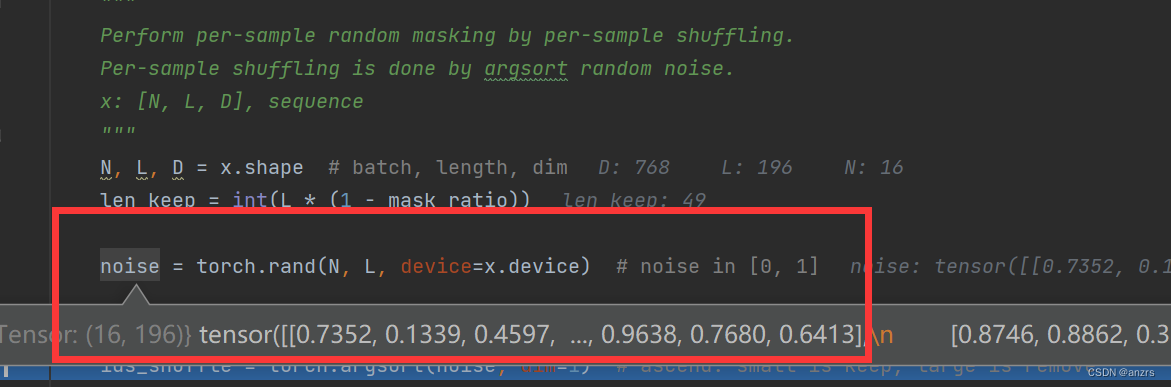
8.噪声的尺寸是,16,196的维度的。
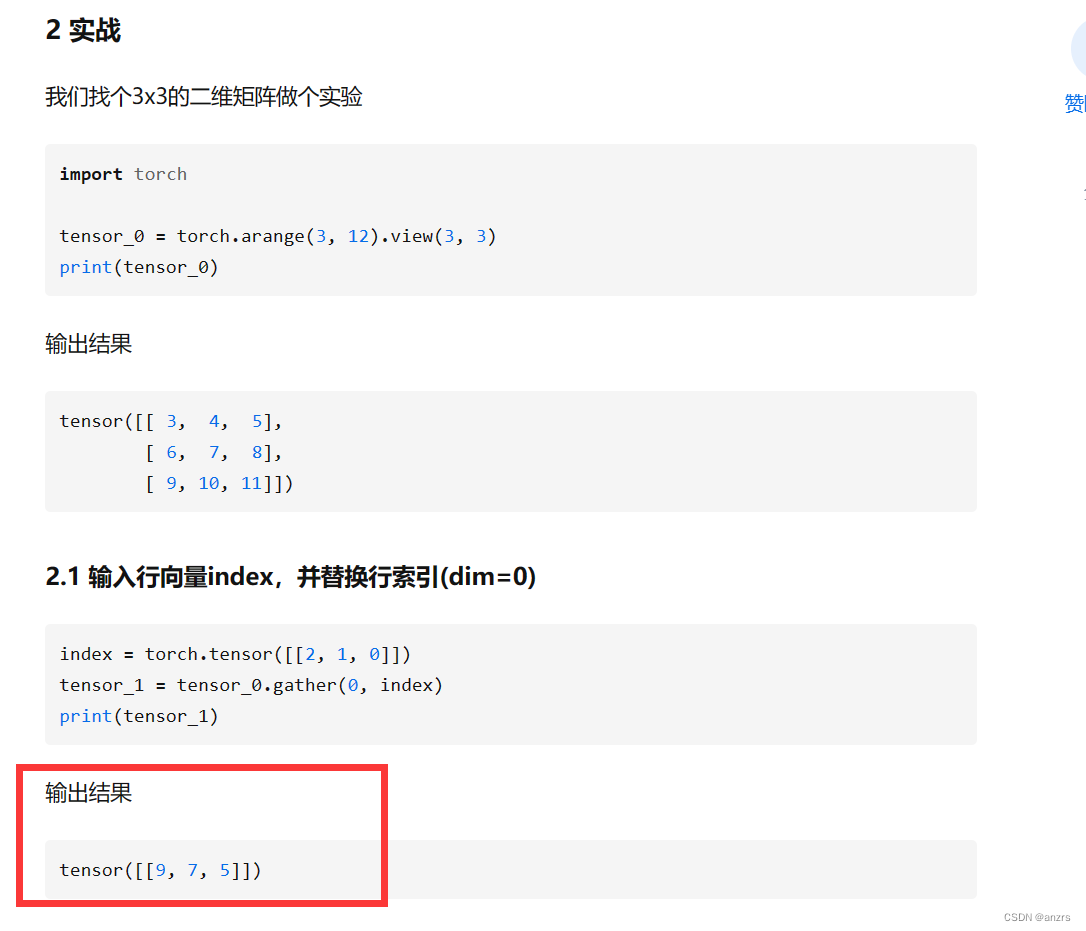
9.这里就比较麻烦了,这个x_masked的,这个是
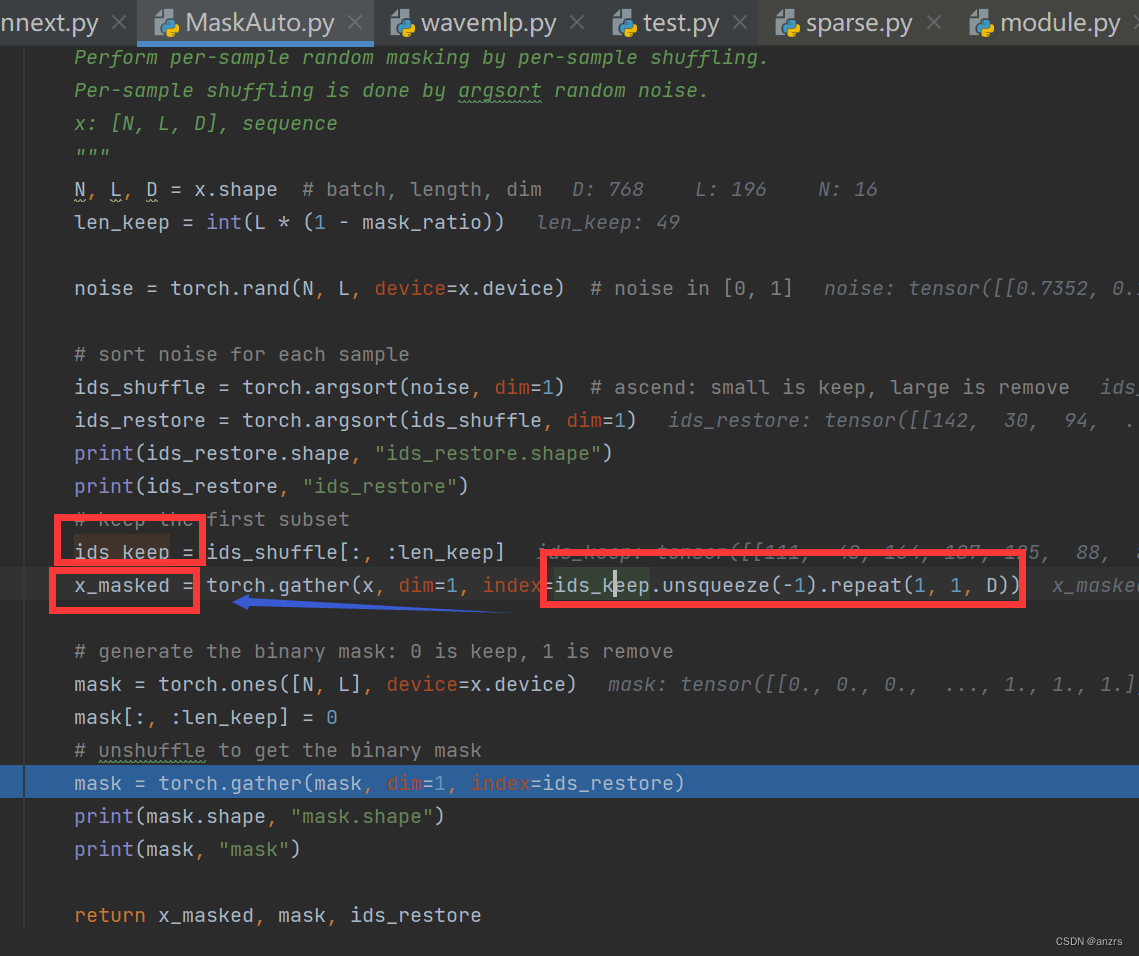 这个尺寸是16,49,768维度的,也就是说,这是被mask的x,也就是这是灰色的那些值。
这个尺寸是16,49,768维度的,也就是说,这是被mask的x,也就是这是灰色的那些值。 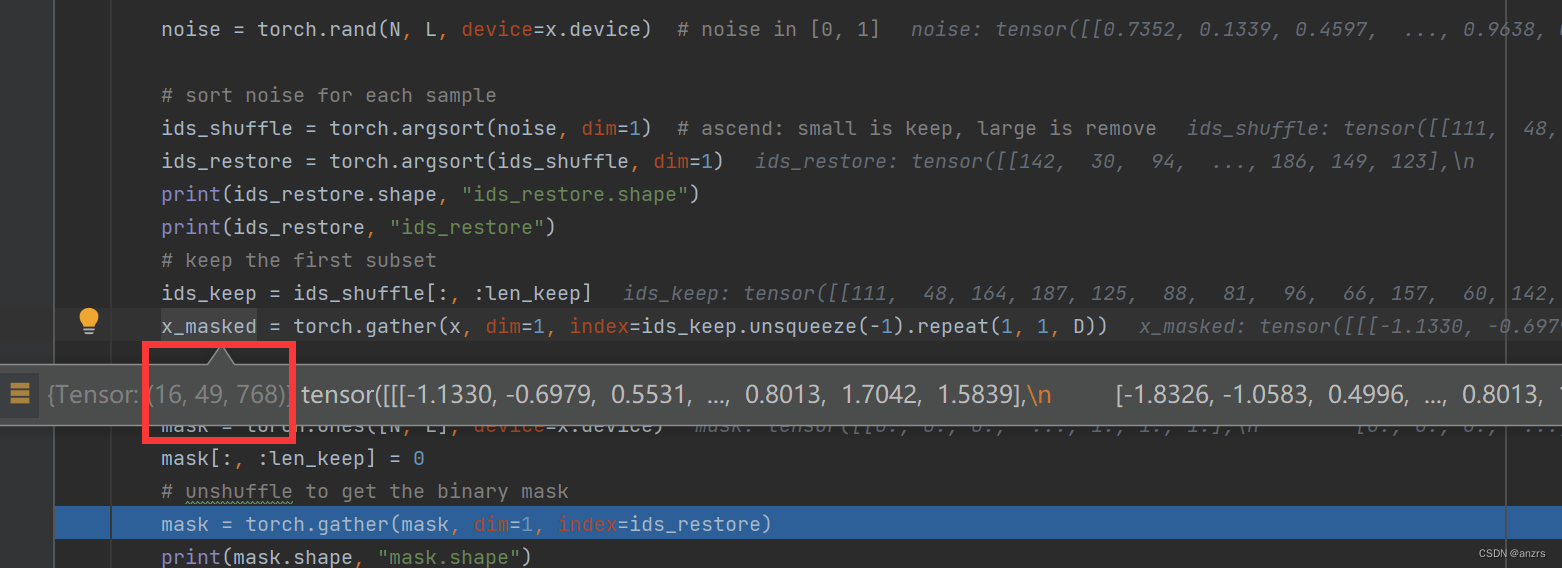
 这个黄色部分一下子理解不来,这个mask是为啥呢?
这个黄色部分一下子理解不来,这个mask是为啥呢?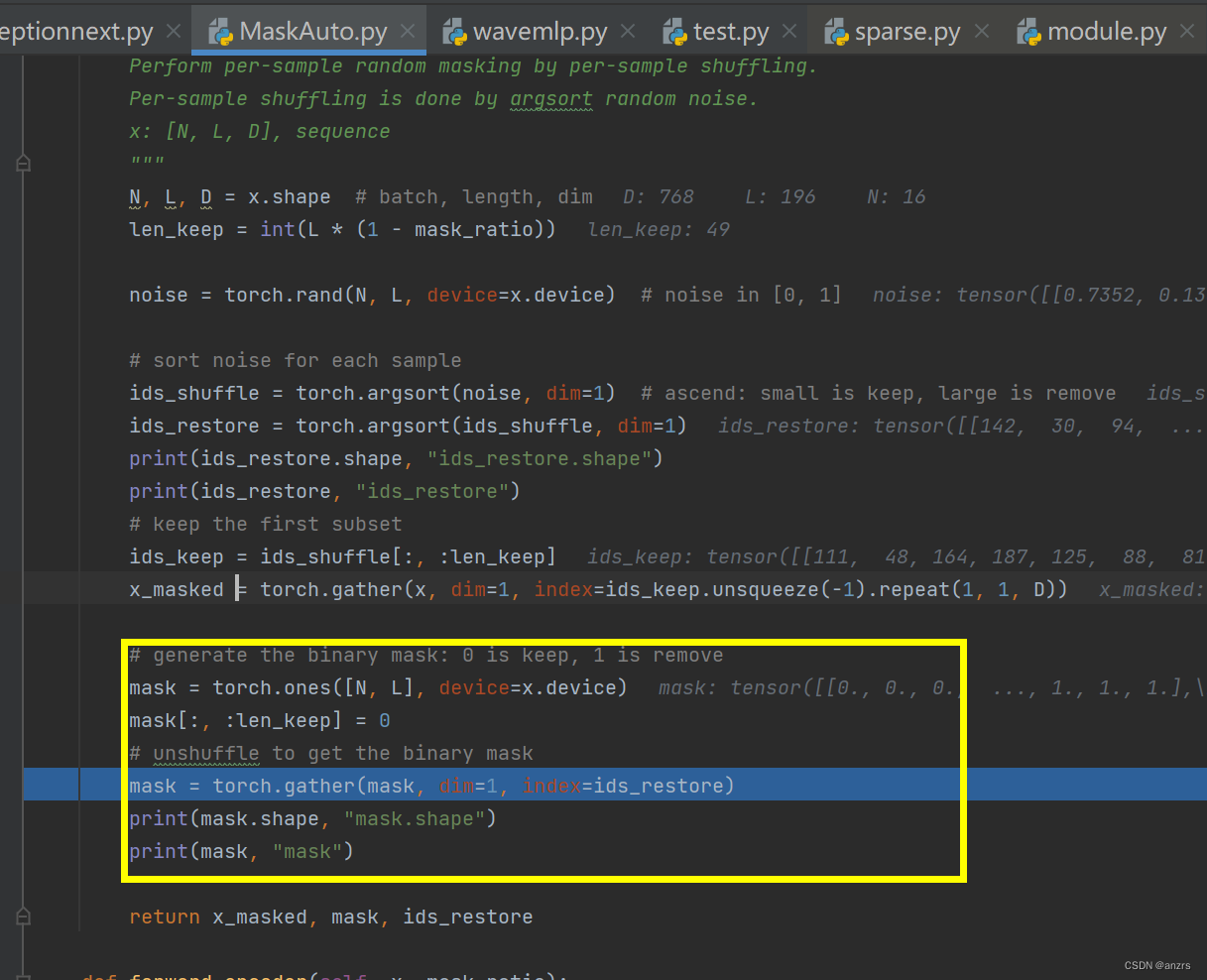


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









