



 本文探讨了Q-Learning算法在无学习经历时如何通过试错学习,并根据Q表选择动作。Q表的更新基于未来奖励的预期,这种得分反映了行为的长期影响。尽管最佳行为可能不会总是被选择,存在一定概率探索其他行为,以避免过拟合。随着学习的深入,未来的奖励对当前状态的影响会逐渐衰减。
本文探讨了Q-Learning算法在无学习经历时如何通过试错学习,并根据Q表选择动作。Q表的更新基于未来奖励的预期,这种得分反映了行为的长期影响。尽管最佳行为可能不会总是被选择,存在一定概率探索其他行为,以避免过拟合。随着学习的深入,未来的奖励对当前状态的影响会逐渐衰减。
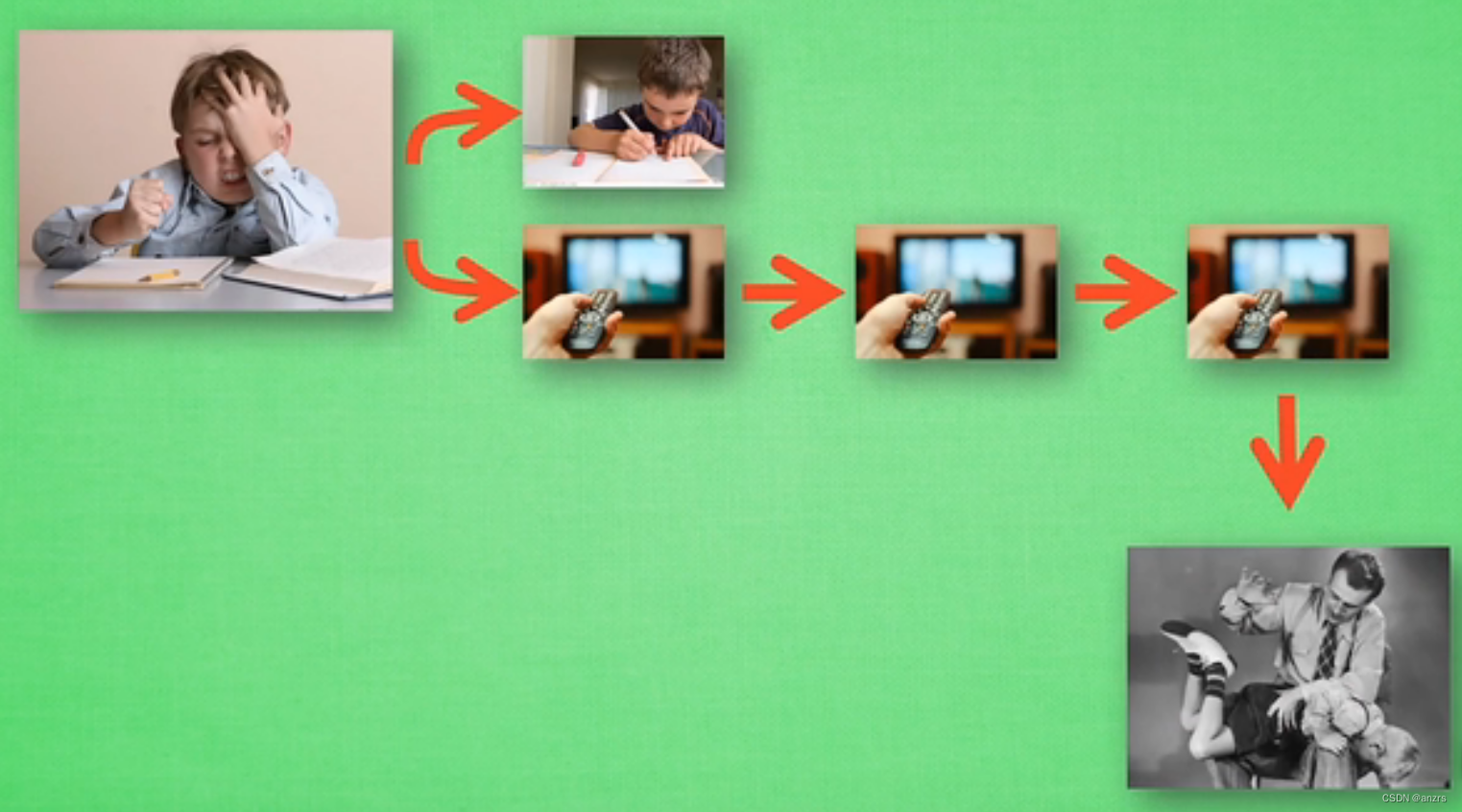
没有任何的学习经历,经过随机的action三次看电视,最终获得了惩罚,会记下这次经历。 QLearning会将没有写完作业就看电视这个行为记录为负面的行为。
有了学习经历后,会根据Q表来判断哪个收益较大来进行action的选择。

虽然没有做出a2这个动作,但是可以根据在s2下进行a2的动作对在s1状态下做出a2进行打分,从而进行更新Q表。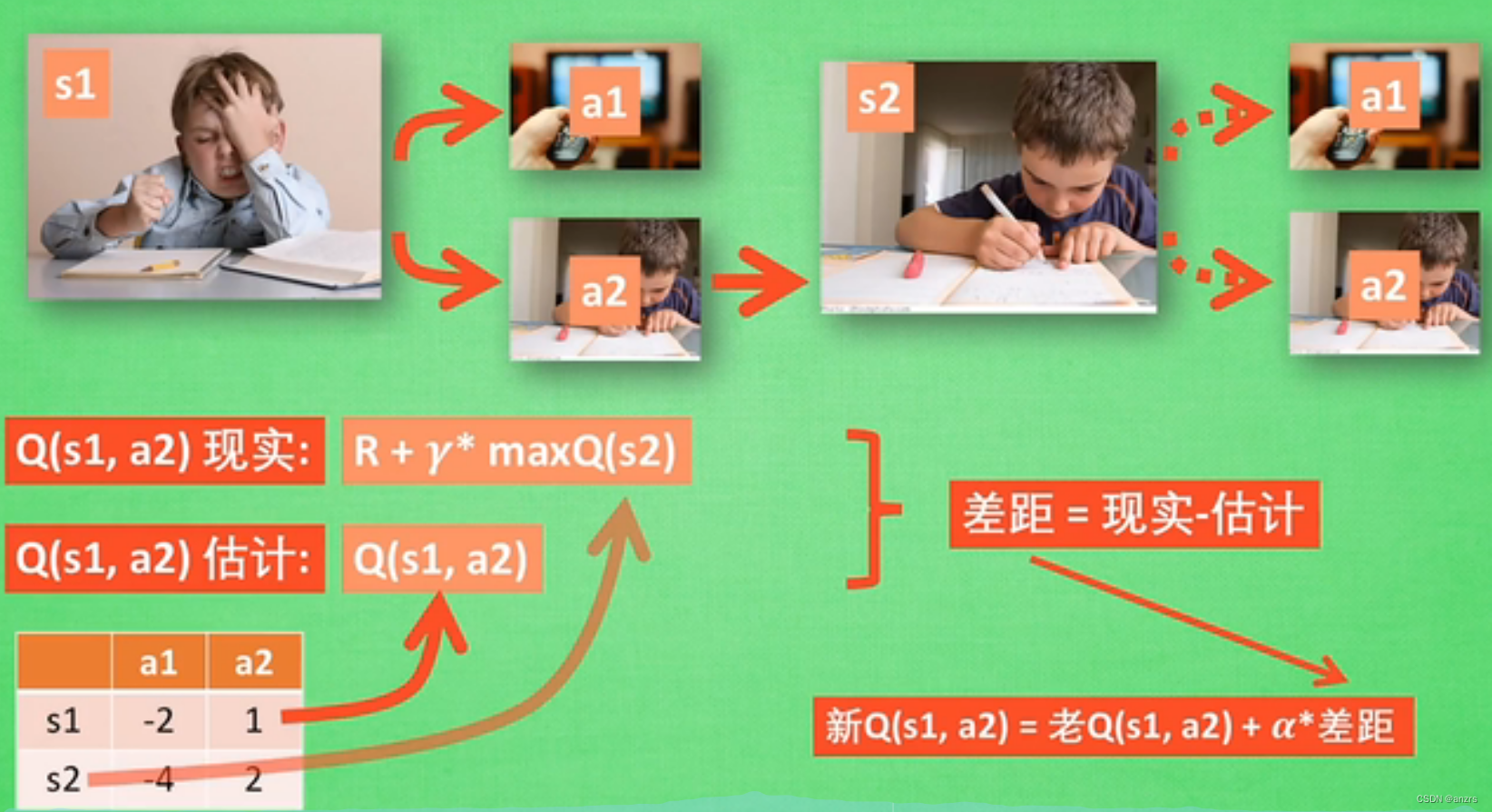
对这个公式的理解:也就是说,根据表的得分就相当于一个局部的最优值?然后根据每次动作会对后面产生的影响,从而更新这步动作的得分。得分是一个深远的影响,但是他的值是暂时的,是会根据每部动作产生变化?

这个值,是行为产生的随机性,也就是说并不是说得分最好的行为就一定会被选择,会有一定的概率来选择其他的行为。这类似于避免一个过拟合?让行为进行探索,并不是说得分好就一定是最好的?

对于Qs1来说,以后的奖励对他的权重会没那么大,会有一个衰减的过程。


















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









