






 本文详细介绍了Python编程中的列表生成式、生成器及其应用场景,如内存优化和性能提升。接着讨论了装饰器的概念、用途和实现方式,包括有参装饰器,并通过实例展示了其在函数运行时间计算中的应用。此外,还探讨了内置高阶函数如map、reduce、filter和sorted的使用方法。这些内容对于理解和提升Python编程能力至关重要。
本文详细介绍了Python编程中的列表生成式、生成器及其应用场景,如内存优化和性能提升。接着讨论了装饰器的概念、用途和实现方式,包括有参装饰器,并通过实例展示了其在函数运行时间计算中的应用。此外,还探讨了内置高阶函数如map、reduce、filter和sorted的使用方法。这些内容对于理解和提升Python编程能力至关重要。
一.生成式详解
列表生成式就是一个用来生成列表的特定语法形式的表达式。是Python提供的一种生成列表的简洁形式, 可快速生成一个新的list。
普通的语法格式:[exp for iter_var in iterable]
带过滤功能语法格式: [exp for iter_var in iterable if_exp]
循环嵌套语法格式: [exp for iter_var_A in iterable_A for iter_var_B in iterable_B]
列表生成式:
#1 普通:需求:生成100个验证码(4个字母组成的验证码)
import string,random
codes = []
for count in range(100):
code = "".join(random.sample(string.ascii_letters,4))
codes.append(code)
print(codes)
#2列表生成式
codes = ["".join(random.sample(string.ascii_letters,4)) for i in range(100)]
print(codes)
#3.需求:找出1-100之间可以被3整除的数
#2-1)普通
nums = []
for num in range(101):
if num%3==0:
nums.append(num)
print(nums)
优化:
nums = [num for num in range(101) if num%3==0]
print(nums)

二.生成器详解
什么叫生成器?
在Python中,一边循环一边计算的机制,称为生成器:Generator。
什么时候需要使用生成器?
性能限制需要用到,比如读取一个10G的文件,如果一次性将10G的文件加载到内存处理的话(read方法),内存肯定会溢出;但使用生成器把读写交叉处理进行,比如使用(readline和readlines)就可以再循环读取的同时不断处理,这样就可以节省大量的内存空间.
如何创建生成器?
第一种方法: 列表生成式的改写。 []改成()
第二种方法: yield关键字。
如何打印生成器的每一个元素呢?
通过for循环, 依次计算并生成每一个元素。
如果要一个一个打印出来,可以通过next()函数获得生成器的下一个返回值。
生成器的特点是什么?
解耦. 爬虫与数据存储解耦;
减少内存占用. 随时生产, 即时消费, 不用堆积在内存当中;
可不终止调用. 写上循环, 即可循环接收数据, 对在循环之前定义的变量, 可重复使用;
生成器的循环, 在 yield 处中断, 没那么占 cpu.
#1.生成式:缺点:
# - 需要等待长时间
# - 会将值返回
num = [i**2 for i in range(1000)]
print(num)
#2.生成器实现的第一种方法:将生成式改写成生成器,使用()
nums = (i**2 for i in range(1000))
print(nums) #<generator object <genexpr> at 0x016CCFB0>
for num in nums:
print(num)
#3.生成器实现的第二种方法:yield关键字,使用next进行依次访问
# return: 函数遇到return就返回,return后面的代码并不会执行
# yield: 遇到yield,则停止执行代码,当再次调用next方法时,会从上次停止的地方继续执行
# (带有yield的函数是一个迭代器,函数返回某个值时,会停留在某个位置,返回函数值后,
# 会在前面停留的位置继续执行,直到程序结束)
def login():
a =1
return 'login'
print(a) #不会打印a的值
result = login()
print(result)
def login():
print('step 1')
yield 1 ##返回数字1,输出1,
print('step 2')
yield 2
print('step 3')
yield 3
#如果函数里面有yield关键字,说明函数的返回值就是一个生成器
g = login()
print(next(g)) #step 1 , 1
print(next(g)) #step 2 , 2
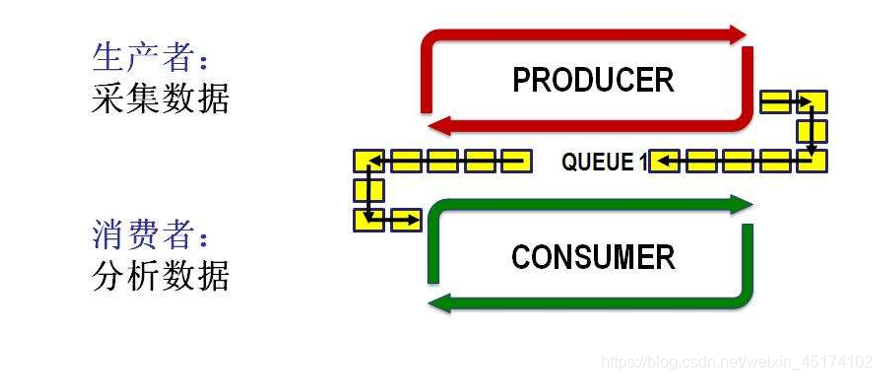
生产者消费者问题是多线程并发中一个非常经典的问题,也是在互联网面试求职中会经常问到的一个题。
顾名思义,单生产者-单消费者模型中只有一个生产者和一个消费者,生产者不停地往队列库中放入产品,消费者则从队列库中取走产品。
生产者-消费者模型有如下几个特点:
1、队列库容积有一定的限制,只能容纳一定数目的产品。
2、如果生产者生产产品的速度过快,则需要等待消费者取走产品之后,产品库不为空才能继续往产品库中放如新的产品。
3、如果消费者取走产品的速度过快,则可能面临产品库中没有产品可使用的情况,此时需要等待生产者放入一个产品后,消费者才能继续工作。
专业术语描述:
1、当队列元素已满的时候,阻塞插入操作;
2、当队列元素为空的时候,阻塞获取操作;
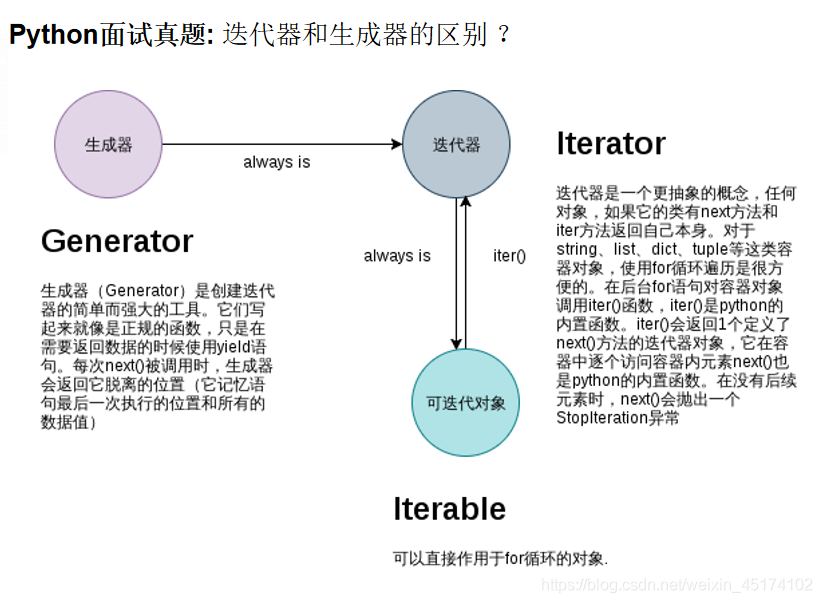
三.生成器、迭代器与可迭代对象
迭代是访问容器元素的一种方式。迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。
可迭代对象:可以直接作用于for循环的对象(如何判断是否可以迭代?)
一类是集合数据类型,如list, tuple,dict, set,str等;
一类是generator,包括生成器和带yield的generator function。
注意:
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数
四.闭包
什么是闭包?如何实现闭包?
闭包就是指有权访问另一个函数作用域中的变量的函数。
创建闭包最常见方式,就是在一个函数内部创建另一个函数。
常见形式: 内部函数使用了外部函数的临时变量,且外部函数的返回值是内部函数的引用。
闭包的一个常用场景就是装饰器。
#1. 时间戳的拓展
import time
print(time.time()) #1612668195.066301从1970年到现在经历的秒数
start_time = time.time()
time.sleep(2)
end_time = time.time()
print(end_time-start_time) #2.00152587890625
# #2.闭包
# #2-1)函数里面嵌套函数
def timieit():
def wrpper(): ##遇到定义函数并不会执行函数
print('wrpper')
print('timieit')
timieit() #timieit
#2-2)外部函数的返回值是内部函数的引用
def timieit():
def wrpper(): ##遇到定义函数并不会执行函数
print('wrpper')
print('timieit')
return wrpper
in_fun = timieit()
in_fun() #timieit wrpper
#2-3)内部函数可以使用外部函数的变量
def timieit(name):
def wrpper(): ##遇到定义函数并不会执行函数
print('wrpper'+name)
print('timieit')
return wrpper
in_fun = timieit(name='westos')
in_fun() #timeit wrpperwestos
#小示例
def lin_conf(a:int,b:int):
def line(x):
print(a*x+b)
return a*x+b
return line
line1 = lin_conf(1,1)
line2 = lin_conf(2,1)
line3 = lin_conf(3,1)
print(line1(3)) # 4,4
print(line2(3)) # 7,7
五.装饰器
1.什么是装饰器?
器指的是工具,而程序中的函数就是具备某一功能的工具,所以装饰器指的是为被装饰器对象添加额外功能的工具/函数。
2.为什么使用装饰器?
如果我们已经上线了一个项目,我们需要修改某一个方法,但是我们不想修改方法的使用方法,这个时候可以使用装饰器。因为软件的维护应该遵循开放封闭原则,即软件一旦上线运行后,软件的维护对修改源代码是封闭的,对扩展功能指的是开放的。
装饰器的实现必须遵循两大原则:
封闭: 对已经实现的功能代码块封闭。 不修改被装饰对象的源代码
开放: 对扩展开发
装饰器其实就是在遵循以上两个原则的前提下为被装饰对象添加新功能。
3.如何实现装饰器?
装饰器本质上是一个函数,该函数用来处理其他函数,它可以让其他函数在不需要修改代码的前提下增加额外的功能,装饰器的返回值也是一个函数对象。
4.装饰器的应用场景是什么?
装饰器经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等应用场景。
5. 万能装饰器的实现
"""
装饰器的万能模板:
def 装饰器名称(f):
@wraps(f) # 保留被装饰函数的属性信息和帮助文档
def wrapper(*args, **kwargs):
# 执行函数之前做的事情
result = f(*args, **kwargs)
# 执行函数之后做的事情
return result
return wrapper
"""
#需求:计算函数的运行时间
import time
from functools import wraps
from functools import lru_cache ##系统内置的装饰器,处理缓存的
def timeit(f): ##写一个形参,来表示装饰的函数
"""计时器装饰器"""
@wraps(f) ##保留被装饰函数的属性信息和帮助文档
def wrapper(*args,**kwargs): ##args 元组 kwargs 字典
"""wrapper内部函数"""
start = time.time()
result = f(*args,**kwargs)
end = time.time()
print(f'函数{f.__name__}运行时间为{end-start}秒')
return result
return wrapper ##函数名加(),是执行函数
@timeit
def login():
"""login doc"""
print('login...')
login()
#爬取图片
@timeit #使用前面的计时器装饰器
def crawl():
import requests
url = 'https://images.techhive.com/images/article/2013/09/linux-penguin-100055693-large.jpg'
content = requests.get(url).content
with open('doc/python.jpg', 'wb') as f:
f.write(content)
print("下载图片成功")
6.有参装饰器
#需求:计算函数的运行时间
import time
from functools import wraps
from functools import lru_cache ##系统内置的装饰器,处理缓存的
def timeit(args='seconds'):
def desc(f): ##写一个形参,来表示装饰的函数
"""计时器装饰器"""
@wraps(f) ##保留被装饰函数的属性信息和帮助文档
def wrapper(*args,**kwargs): ##args 元组 kwargs 字典
"""wrapper内部函数"""
start = time.time()
result = f(*args,**kwargs)
end = time.time()
if args == 'seconds':
print(f'函数{f.__name__}运行时间为{end-start}秒')
elif args == 'minutes':
print(f'函数{f.__name__}运行时间为{(end - start)/60}秒')
return result
return wrapper ##函数名加(),是执行函数
return desc
@timeit(args='minutes') #@timeit() @desc ===>login=desc(login)
def login():
"""login doc"""
print('login...')
login()
- 多个装饰器
def is_login(f):
def wrapper1(*args, **kwargs):
print('is_login, 用户是否登录')
result = f(*args, **kwargs)
return result
return wrapper1
def is_permission(f):
def wrapper2(*args, **kwargs):
print('is_permission, 用户是否有权限')
result = f(*args, **kwargs)
return result
return wrapper2
# 规则: 先装饰,再执行.被装饰的顺序是从下到上,执行装饰器内容是从上到下
@is_login # show_hosts=is_login(wrapper2) show_hosts=wrapper1
@is_permission # 装饰顺序:show_hosts = is_permission(show_hosts) show_hosts=wrapper2
def show_hosts():
print("显示所有的云主机")
show_hosts()
"""
执行顺序
--: show_hosts()
1). wrapper1()
2). wrapper2()
3). show_hosts()
"""
六.内置高阶函数
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返
回一个函数!Python对函数式编程提供部分支持。
# 1. map函数
# map() 会根据提供的函数对指定序列做映射
result = map(lambda x: x ** 2, [1, 2, 4, 5])
print(list(result)) #[1, 4, 16, 25]
# 当序列多于一个时,map可以并行(注意是并行)地对每个序列执行
result = map(lambda x, y: x + y, [1, 2, 3], [4, 5, 6])
print(list(result)) #[5, 7, 9]
# 2. reduce函数
# reduce() 函数会对参数序列中元素进行累积
from functools import reduce
# (((1+2)+3)+4)+5=reduce result
result = reduce(lambda x, y: x + y, [1, 2, 3, 4, 5])
print(result) #15
# 练习: 求1*2*..10的结果, 用reduce和匿名函数实现
result = reduce(lambda x,y: x*y, range(1, 11))
print(result) #3628800
# 3. filter:
# filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表
# 筛选所有的偶数
result = filter(lambda x: x % 2 == 0, [1, 2, 4, 5, 8])
print(list(result)) #[2, 4, 8]
# 筛选所有的奇数
result = filter(lambda x: x % 2 != 0, [1, 2, 4, 5, 8])
print(list(result)) #[1, 5]
# 4. sorted:
# sorted() 函数对所有可迭代的对象进行排序操作。返回重新排序的列表
result = sorted([1, 29, 2, 3])
print(result) #[1, 2, 3, 29]
# reverse: 排序规则,True 降序 ,False 升序(默认)
result = sorted([0, 29, 2, 0], reverse=True)
print(result) #[29, 2, 0, 0]
# key: 主要是用来进行比较的元素,只有一个参数
result = sorted([0, 8, 9, 0, 16], key=lambda x:0 if x==0 else 1)
print(result) #[0, 0, 8, 9, 16]

















 477
477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









