






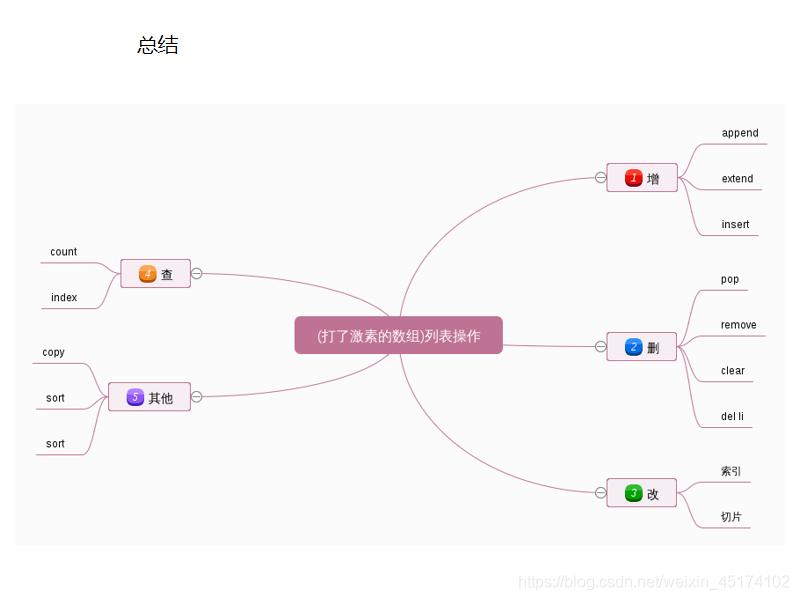
1.序列
成员有序排列的,且可以通过下标偏移量访问到它的一个或者几个成员,这类类型统称为序列。
序列数据类型包括:字符串,列表,和元组类型。
特点: 都支持下面的特性
索引与切片操作符
成员关系操作符(in , not in)
连接操作符(+) & 重复操作符(*)
2.列表
数组: 存储同一种数据类型的集和。scores=[12,95.5]
列表(打了激素的数组): 可以存储任意数据类型的集和。
1)列表的创建
创建一个空列表
list = []
创建一个包含元素的列表,元素可以是任意类型,
包括数值类型,列表,字符串等均可, 也可以嵌套列表。
list = [“fentiao”, 4, ‘gender’]
list = [[‘粉条’, 100], [“粉丝”, 90], [“粉带”, 98]]
2)列表特性
#1.连接操作符和重复操作符
print([1,2]+[2,3]) #[1, 2, 2, 3]
print([1,2]*3) ##[1, 2, 1, 2, 1, 2]
#2.成员操作符(in,not in )
print(1 in [1,2]) # True
"""
布尔类型
True:1
False:0
"""
print(1 in ['a',True,[1,2]]) #True 因为结果True相当于1
print(1 in ['a',False,[1,2]]) #False 因为False相当于0
#3.索引
li = [1,2,3,[1,'b',3]]
print(li[0]) #1
print(li[-1]) #[1,'b',3]
print(li[-1][1]) #1
print(li[3][-1]) #3
#4.切片
li = ['172','25','254','100']
print(li[:2])
print(li[1:])
print(li[::-1])
print('-'.join(li[3:0:-1]))
print('-'.join(li[1:][::-1])) ##俩个切片,先顺序在逆序
#5.for循环
names = ['1','2','3']
for name in names:
print(f"name{name}")
3)列表的常用方法(包括增删改查)
#1.增加
li = [1,2,3]
#1-1)追加
li.append(4)
print(li) #[1, 2, 3, 4]
#1-2)列表指定位置添加
li.insert(0,'cat')
print(li) #['cat', 1, 2, 3, 4]
li.insert(1,'cat')
print(li) #['cat', 'cat', 1, 2, 3, 4]
#1-3)一次追加多个元素
li = [1,2,3]
li.extend([4,5,6])
print(li) #[1, 2, 3, 4, 5, 6]
#2 修改
li = [1,2,3]
li[0] = 'cat'
print(li) #['cat', 2, 3]
li[2] = 'westos'
print(li) #['cat', 2, 'westos']
li[:2] = [1,1]
print(li) # [1, 1, 'westos']
#3 查看 通过索引和切片查看元素,查看索引值和出现次数
li = [1,2,3,1,1,3]
print(li.count(1)) # 3
print(li.index(3)) # 2
# 4.删除
# 4-1)根据索引删除
li = [1,2,3]
delete_num = li.pop(-1)
print(li) #[1,2]
# 4-2)根据value值删除
li= [1,2,3]
li.remove(3)
print(li) #[1,2]
# 4-3) 全部清空
li= [1,2,3]
li.clear()
print(li) #[]
#5.其他操作
li = [1,2,3,4]
li.reverse() ##反转
print(li) ##[4,3,2,1]
li.sort() ##sort排序默认由小到大,如果想由大到小排序,设置reverse=True
print(li) #[1, 2, 3, 4]
li.sort(reverse=True)
print(li) #[4, 3, 2, 1]
li1= li.copy() ##复制,id不同
print(id(li1),id(li)) #31081896 31083056
print(li,li1) #[4, 3, 2, 1] [4, 3, 2, 1]
del li ##直接删除li 列表
3.元组
1)元组的操作
元组的操作格式为:
定义空元组 tuple = ()
定义单个值的元组 tuple = (fentiao,)
一般的元组 tuple = (fentiao, 8, male)
# 元组简单示例
tuple1=(1,2.2,'das',[1,2,3])
print(tuple1)
#1.元组的创建
t1 = () ##空元组
print(t1,type(t1)) #() <class 'tuple'>
t2 = (1,) #重点:元组单个元素一定要加逗号
print(t2,type(t2)) #(1,) <class 'tuple'>
t3 = (1,1.1,True)
print(t3,type(t3)) #(1, 1.1, True) <class 'tuple'>
#2.特性
## 2.1 连接操作符和重复操作符
print((1,2,3)+(4,)) #(1, 2, 3, 4)
print((1,2,3)*3) #(1, 2, 3, 1, 2, 3, 1, 2, 3)
## 2.2 成员操作符in,not in
print(1 in (1,2,3))
## 2.3 切片
t = (1,2,3)
print(t[0]) #1
print(t[:]) #(1, 2, 3)
print(t[-1]) #3
print(t[::-1]) #(3, 2, 1)
print(t[:2]) #(1, 2)
# 3.常用方法:count和index,元组是不可变类型(不能增删改)
t = (1,2,3,4,1,1)
print(t.count(1)) #3
print(t.index(1)) #0
2) 命名元组的操作
Tuple还有一个兄弟,叫namedtuple。虽然都是tuple,但是功能更为强大
collections.namedtuple(typename, field_names)
typename:类名称
field_names: 元组中元素的名称

tuple = ('westos',18,'西安') #普通元组
##命名元组解决了读代码的烦恼
from collections import namedtuple ##命名元组的用法
#1.创建命名元组对象User
User = namedtuple('User',('name','age','city'))
# 2.给命名元组传值
user1 = User('westos',18,'xian')
# 3.打印命名元组
print(user1) #User(name='westos', age=18, city='xian')
print(user1.name) #westos
print(user1.age) #18
print(user1.city) #xian
3) 地址引用和深拷贝和浅拷贝
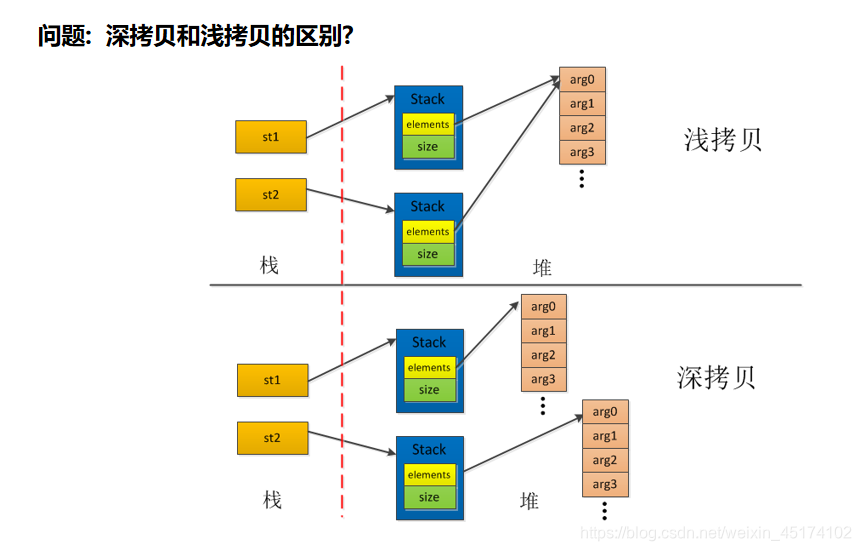
问题: 深拷贝和浅拷贝的区别?/python中如何拷贝一个对象?
赋值: 创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。(=)
浅拷贝: 对另外一个变量的内存地址的拷贝,这两个变量指向同一个内存地址的变量值。(li.copy(), copy.copy())
公用一个值;
这两个变量的内存地址一样;
对其中一个变量的值改变,另外一个变量的值也会改变;
深拷贝: 一个变量对另外一个变量的值拷贝。(copy.deepcopy())
两个变量的内存地址不同;
两个变量各有自己的值,且互不影响;
对其任意一个变量的值的改变不会影响另外一个;

"""
深拷贝和浅拷贝最根本的区别在于是否真正获取一个对象的复制实体,而不是引用。
假设B复制了A,修改A的时候,看B是否发生变化:
如果B跟着也变了,说明是浅拷贝,拿人手短!(修改堆内存中的同一个值)
如果B没有改变,说明是深拷贝,自食其力!(修改堆内存中的不同的值)
"""
# 1. 值的引用
"""
赋值: 创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。(=)
"""
nums1 = [1,2,3,]
nums2 = nums1 ##此时指向同一个内存空间
nums1.append(4)
print(nums1) #[1, 2, 3, 4]
print(nums2) #[1, 2, 3, 4]
#2. 拷贝:浅拷贝和深拷贝
#2-1)浅拷贝
"""
浅拷贝: 对另外一个变量的内存地址的拷贝,这两个变量指向同一个内存地址的变量值。(li.copy(), copy.copy())
公用一个值;
这两个变量的内存地址一样;
对其中一个变量的值改变,另外一个变量的值也会改变;
应用场景:核心: 如果列表的元素包含可变数据类型, 一定要使用深拷贝。
"""
n1 = [1,2,3]
n2 = n1.copy() ##n1.copy和ni[:]都可以实现拷贝
print(id(n1),id(n2)) ##copy指向不同的内存空间,所以互不影响
n1.append(4)
print(n1) #[1, 2, 3, 4] ##相当于打印一份,然后在一份上做修改,不影响另一份
print(n2) #[1, 2, 3]
#2-2)深拷贝
"""
如果列表的元素包含可变数据类型,一定要使用深拷贝
可变数据类型(可增删改的): list
不可变数据类型(变量指向的内存空间的值不会改变): str,tuple,nametuple
"""
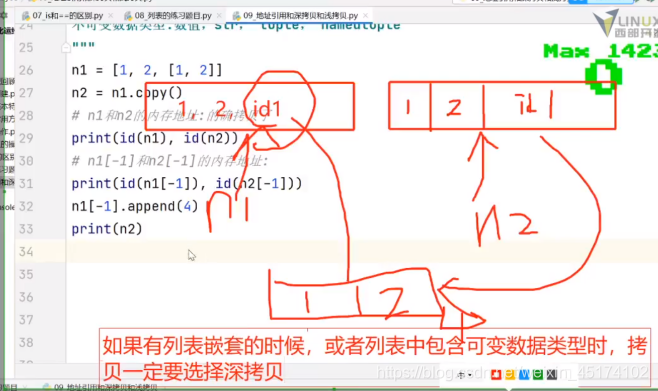
n1 = [1,2,[1,2]]
n2 = n1.copy()
##查看n1和n2的内存地址,发现进行了拷贝
print(id(n1),id(n2)) #16971096 16665136
#n1[-1]和n2[-1]的内存地址
print(id(n1[-1]),id(n2[-1])) #17020328 17020328
n1[-1].append(4)
print(n1) #[1, 2, [1, 2, 4]]修改成功
print(n2) #[1, 2, [1, 2, 4]]也随之发生改变
#2-3)如何实现深拷贝copy.deepcopy
"""
深拷贝: 一个变量对另外一个变量的值拷贝。(copy.deepcopy())
两个变量的内存地址不同;
两个变量各有自己的值,且互不影响;
对其任意一个变量的值的改变不会影响另外一个;
"""
import copy
n1 = [1,2,[1,2]]
n2 = copy.deepcopy(n1)
##查看n1和n2的内存地址,发现进行了拷贝
print(id(n1),id(n2)) #16971096 16665136
#n1[-1]和n2[-1]的内存地址
print(id(n1[-1]),id(n2[-1])) #26564608 26565248
n1[-1].append(4)
print(n1) #[1, 2, [1, 2, 4]]修改成功
print(n2) #[1, 2, [1, 2]]
4.is和==的区别
问题: is和==两种运算符在应用上的本质区别是什么?
1). Python中对象的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。
2). is和==都是对对象进行比较判断作用的,但对对象比较判断的内容并不相同。
3). ==用来比较判断两个对象的value(值)是否相等;(type和value)
is也被叫做同一性运算符, 会判断id是否相同;(id, type 和value)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









