







网络构建
神经网络模型是由神经网络层和Tensor操作构成的,mindspore.nn提供了常见神经网络层的实现,在MindSpore中,Cell类是构建所有网络的基类,也是网络的基本单元。一个神经网络模型表示为一个Cell,它由不同的子Cell构成。使用这样的嵌套结构,可以简单地使用面向对象编程的思维,对神经网络结构进行构建和管理。
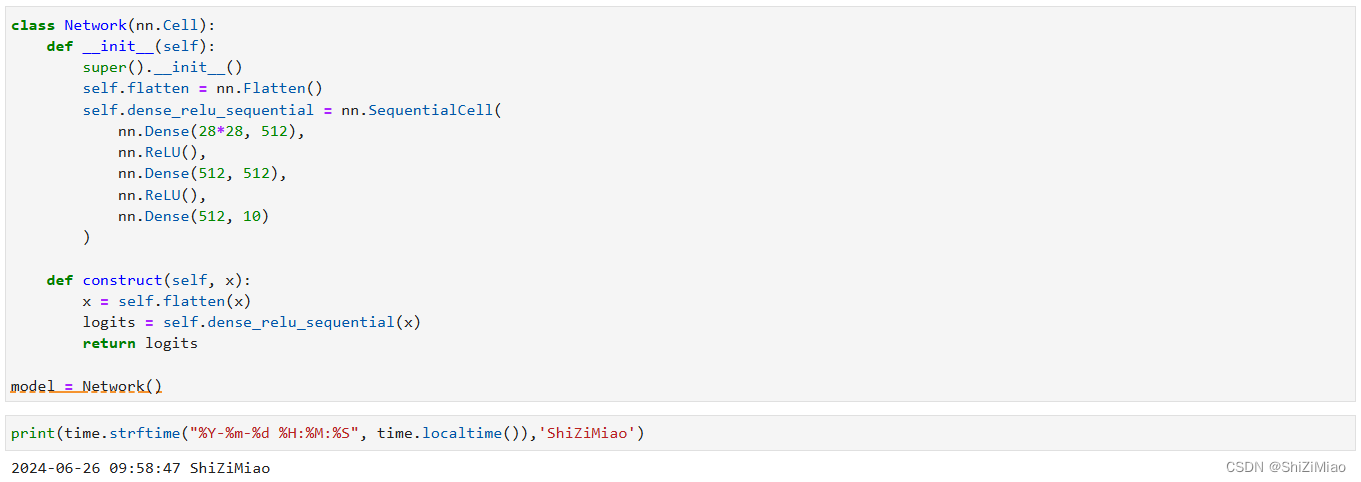
定义模型类
当我们定义神经网络时,可以继承nn.Cell类,在__init__方法中进行子Cell的实例化和状态管理,在construct方法中实现Tensor操作。
construct意为神经网络(计算图)构建,相关内容详见使用静态图加速。


模型层

nn.Flatten
实例化nn.Flatten层,将28x28的2D张量转换为784大小的连续数组。

nn.Dense
nn.Dense为全连接层,其使用权重和偏差对输入进行线性变换。

nn.ReLU
nn.ReLU层给网络中加入非线性的激活函数,帮助神经网络学习各种复杂的特征。

nn.SequentialCell
nn.SequentialCell是一个有序的Cell容器。输入Tensor将按照定义的顺序通过所有Cell。我们可以使用SequentialCell来快速组合构造一个神经网络模型。
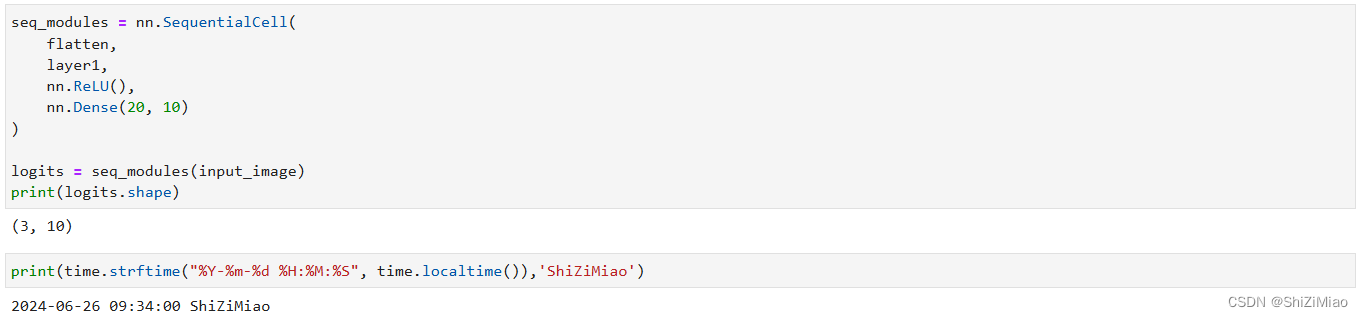
nn.Softmax
最后使用nn.Softmax将神经网络最后一个全连接层返回的logits的值缩放为[0, 1],表示每个类别的预测概率。axis指定的维度数值和为1。

模型参数
网络内部神经网络层具有权重参数和偏置参数(如nn.Dense),这些参数会在训练过程中不断进行优化,可通过 model.parameters_and_names() 来获取参数名及对应的参数详情。

函数式自动微分
神经网络的训练主要使用反向传播算法,模型预测值(logits)与正确标签(label)送入损失函数(loss function)获得loss,然后进行反向传播计算,求得梯度(gradients),最终更新至模型参数(parameters)。自动微分能够计算可导函数在某点处的导数值,是反向传播算法的一般化。自动微分主要解决的问题是将一个复杂的数学运算分解为一系列简单的基本运算,该功能对用户屏蔽了大量的求导细节和过程,大大降低了框架的使用门槛。
MindSpore使用函数式自动微分的设计理念,提供更接近于数学语义的自动微分接口grad和value_and_grad。下面我们使用一个简单的单层线性变换模型进行介绍。
函数与计算图
计算图是用图论语言表示数学函数的一种方式,也是深度学习框架表达神经网络模型的统一方法。我们将根据下面的计算图构造计算函数和神经网络。
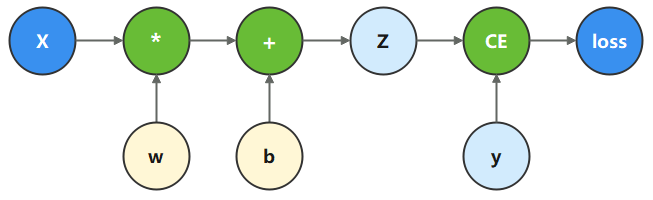

微分函数与梯度计算
为了优化模型参数,需要求参数对loss的导数:
∂
loss
∂
w
\frac{\partial \operatorname{loss}}{\partial w}
∂w∂loss和
∂
loss
∂
b
\frac{\partial \operatorname{loss}}{\partial b}
∂b∂loss,此时我们调用mindspore.grad函数,来获得function的微分函数。
这里使用了grad函数的两个入参,分别为:
fn:待求导的函数。grad_position:指定求导输入位置的索引。
由于我们对
w
w
w和
b
b
b求导,因此配置其在function入参对应的位置(2, 3)。
使用
grad获得微分函数是一种函数变换,即输入为函数,输出也为函数。

神经网络梯度计算
前述章节主要根据计算图对应的函数介绍了MindSpore的函数式自动微分,但我们的神经网络构造是继承自面向对象编程范式的nn.Cell。接下来我们通过Cell构造同样的神经网络,利用函数式自动微分来实现反向传播。
首先我们继承nn.Cell构造单层线性变换神经网络。这里我们直接使用前文的
w
w
w、
b
b
b作为模型参数,使用mindspore.Parameter进行包装后,作为内部属性,并在construct内实现相同的Tensor操作。

模型训练
模型训练一般分为四个步骤:
- 构建数据集。
- 定义神经网络模型。
- 定义超参、损失函数及优化器。
- 输入数据集进行训练与评估。
现在我们有了数据集和模型后,可以进行模型的训练与评估。
构建数据集
首先从数据集 Dataset加载代码,构建数据集。

定义神经网络模型
从网络构建中加载代码,构建一个神经网络模型。
定义超参、损失函数和优化器
超参
超参(Hyperparameters)是可以调整的参数,可以控制模型训练优化的过程,不同的超参数值可能会影响模型训练和收敛速度。目前深度学习模型多采用批量随机梯度下降算法进行优化,随机梯度下降算法的原理如下:
w t + 1 = w t − η 1 n ∑ x ∈ B ∇ l ( x , w t ) w_{t+1}=w_{t}-\eta \frac{1}{n} \sum_{x \in \mathcal{B}} \nabla l\left(x, w_{t}\right) wt+1=wt−ηn1x∈B∑∇l(x,wt)
公式中, n n n是批量大小(batch size), η η η是学习率(learning rate)。另外, w t w_{t} wt为训练轮次 t t t中的权重参数, ∇ l \nabla l ∇l为损失函数的导数。除了梯度本身,这两个因子直接决定了模型的权重更新,从优化本身来看,它们是影响模型性能收敛最重要的参数。一般会定义以下超参用于训练:
-
训练轮次(epoch):训练时遍历数据集的次数。
-
批次大小(batch size):数据集进行分批读取训练,设定每个批次数据的大小。batch size过小,花费时间多,同时梯度震荡严重,不利于收敛;batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值,因此需要选择合适的batch size,可以有效提高模型精度、全局收敛。
-
学习率(learning rate):如果学习率偏小,会导致收敛的速度变慢,如果学习率偏大,则可能会导致训练不收敛等不可预测的结果。梯度下降法被广泛应用在最小化模型误差的参数优化算法上。梯度下降法通过多次迭代,并在每一步中最小化损失函数来预估模型的参数。学习率就是在迭代过程中,会控制模型的学习进度。

损失函数
损失函数(loss function)用于评估模型的预测值(logits)和目标值(targets)之间的误差。训练模型时,随机初始化的神经网络模型开始时会预测出错误的结果。损失函数会评估预测结果与目标值的相异程度,模型训练的目标即为降低损失函数求得的误差。
常见的损失函数包括用于回归任务的nn.MSELoss(均方误差)和用于分类的nn.NLLLoss(负对数似然)等。 nn.CrossEntropyLoss 结合了nn.LogSoftmax和nn.NLLLoss,可以对logits 进行归一化并计算预测误差。

优化器
模型优化(Optimization)是在每个训练步骤中调整模型参数以减少模型误差的过程。MindSpore提供多种优化算法的实现,称之为优化器(Optimizer)。优化器内部定义了模型的参数优化过程(即梯度如何更新至模型参数),所有优化逻辑都封装在优化器对象中。在这里,我们使用SGD(Stochastic Gradient Descent)优化器。
我们通过model.trainable_params()方法获得模型的可训练参数,并传入学习率超参来初始化优化器。

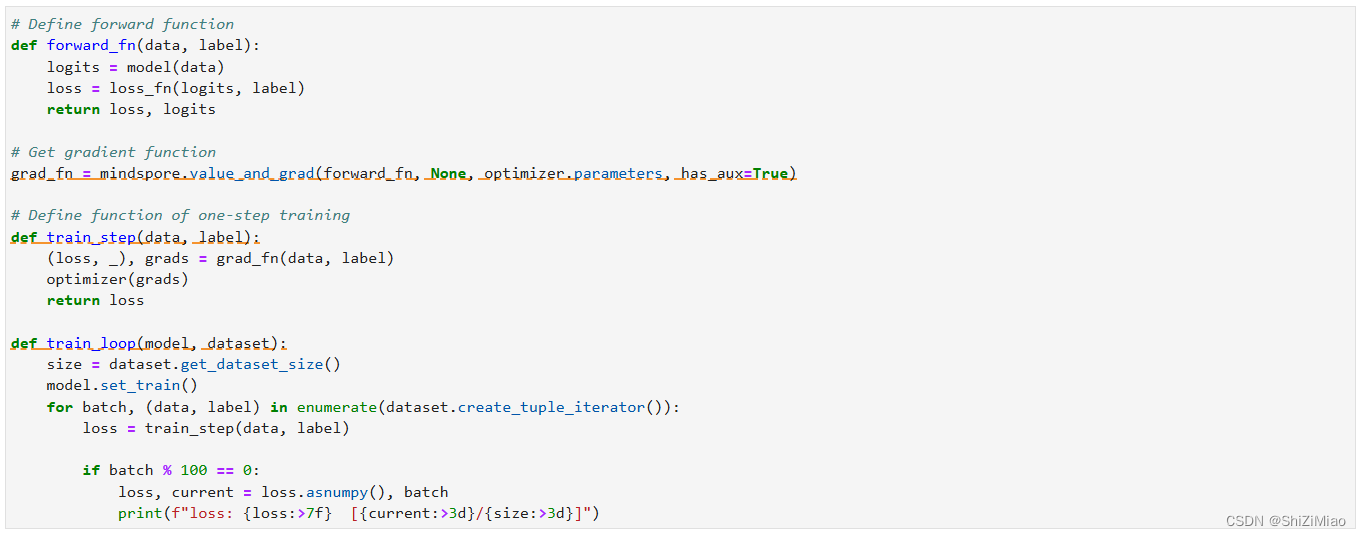
训练与评估
设置了超参、损失函数和优化器后,我们就可以循环输入数据来训练模型。一次数据集的完整迭代循环称为一轮(epoch)。每轮执行训练时包括两个步骤:
- 训练:迭代训练数据集,并尝试收敛到最佳参数。
- 验证/测试:迭代测试数据集,以检查模型性能是否提升。
接下来我们定义用于训练的train_loop函数和用于测试的test_loop函数。


保存与加载
保存和加载模型权重
保存模型使用save_checkpoint接口,传入网络和指定的保存路径:

保存和加载MindIR
除Checkpoint外,MindSpore提供了云侧(训练)和端侧(推理)统一的中间表示(Intermediate Representation,IR)。可使用export接口直接将模型保存为MindIR。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









