







基本介绍
昇思MindSpore介绍
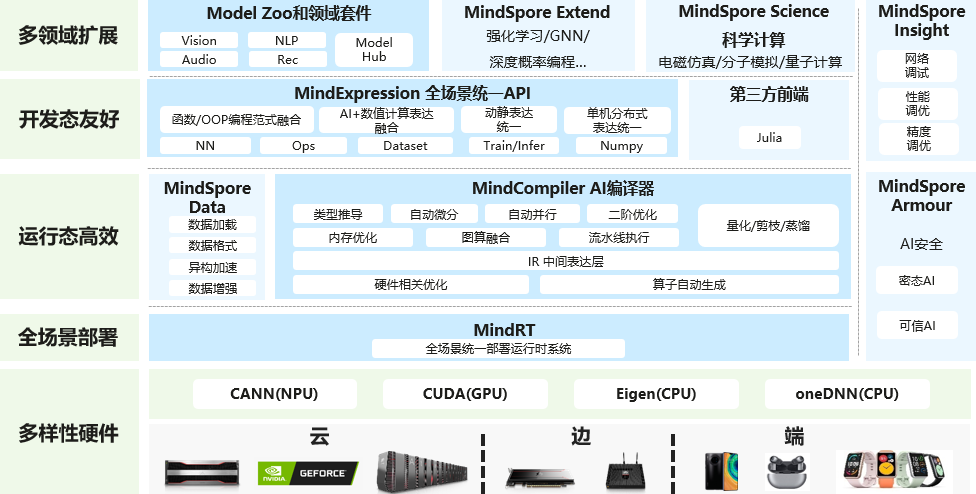
昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景统一部署三大目标。
其中,易开发表现为API友好、调试难度低;高效执行包括计算效率、数据预处理效率和分布式训练效率;全场景则指框架同时支持云、边缘以及端侧场景。
昇思MindSpore总体架构如下图所示:
快速入门
以Mnist数据集为例
处理数据集
- 下载数据集
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)

2. 获取训练集和测试集
train_dataset = MnistDataset('MNIST_Data/train')
test_dataset = MnistDataset('MNIST_Data/test')

3. 对图像数据及标签进行变换处理,然后将处理好的数据集打包为大小为64的batch。
def datapipe(dataset, batch_size):
# 定义图像转换
image_transforms = [
vision.Rescale(1.0 / 255.0, 0), # 归一化
vision.Normalize(mean=(0.1307,), std=(0.3081,)), # 标准化
vision.HWC2CHW() # 转换图像格式
]
# 定义标签转换
label_transform = transforms.TypeCast(mindspore.int32)
# 对数据集进行图像转换
dataset = dataset.map(image_transforms, 'image')
# 对数据集进行标签转换
dataset = dataset.map(label_transform, 'label')
# 对数据集进行批量
dataset = dataset.batch(batch_size)
# 返回处理后的数据集
return dataset

网络构建
用户需要自定义网络时,可以继承nn.Cell类,并重写__init__方法和construct方法。__init__包含所有网络层的定义,construct中包含数据(Tensor)的变换过程。

模型训练
在模型训练中,一个完整的训练过程(step)需要实现以下三步:
- 正向计算:模型预测结果(logits),并与正确标签(label)求预测损失(loss)。
- 反向传播:利用自动微分机制,自动求模型参数(parameters)对于loss的梯度(gradients)。
- 参数优化:将梯度更新到参数上。
MindSpore使用函数式自动微分机制,因此针对上述步骤需要实现:
4. 定义正向计算函数。
5. 使用value_and_grad通过函数变换获得梯度计算函数。
6. 定义训练函数,使用set_train设置为训练模式,执行正向计算、反向传播和参数优化。

定义测试函数用于测试模型性能

测试结果

模型的保存与加载
保存
mindspore.save_checkpoint(model, "model.ckpt")
print("Saved Model to model.ckpt")
加载
# Instantiate a random initialized model
model = Network()
# Load checkpoint and load parameter to model
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load, _ = mindspore.load_param_into_net(model, param_dict)
print(param_not_load)
调用
model.set_train(False)
for data, label in test_dataset:
pred = model(data)
predicted = pred.argmax(1)
print(f'Predicted: "{predicted[:10]}", Actual: "{label[:10]}"')
break
更多细节详见保存与加载。

















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









