







 本文介绍了一种使用TensorFlow实现的手写数字识别方法。通过数据预处理、模型搭建及训练,实现了对MNIST数据集的高效准确识别。
本文介绍了一种使用TensorFlow实现的手写数字识别方法。通过数据预处理、模型搭建及训练,实现了对MNIST数据集的高效准确识别。
导图:
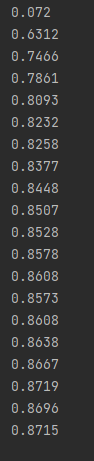
识别准确率:
加入此代码指定用0号GPU计算
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
下面写一下关键的几段代码,add_layer在前面的文章中有讲过就不写了。
一、数据预处理
在预处理过程中,要将数据加载,图像是灰度图,像素的范围是0~255,将其归一化为0 ~ 1,将标签进行独热码处理,最后将[28,28]的图像转为784列
(train_images, train_labels), (test_images, test_labels) = tff.keras.datasets.mnist.load_data()
train_images, test_images = train_images / 255.0, test_images / 255.0#图像归一化
train_labels, test_labels = to_categorical(train_labels), to_categorical(test_labels)
#转换成784列
train_images = train_images.reshape([-1, 784])
test_images = test_images.reshape([-1, 784])
二、预测的准确率
tf.equal()函数是判断两个矩阵的相对应的值是否相等,若相等则返回True,点击此处查看详细用法。
tf.argmax(y_pre, 1)是挑出每一行中最大的值,最大的值就是预测的那个数字。
tf.cast()将True和False转换为0和1,最后求得均值就是预测准确率
def compute_accuracy(v_xs, v_ys):
global prediction#将predication设为全局变量
y_pre = sess.run(prediction, feed_dict={xs: v_xs})
correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1))#如果预测值和测试的真实值的每一行最大元素相同则为True
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))#转换为float32后算平均值得出准确率
return sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys})
三、每次训练取100个图像
train_images.shape[0]指tranin_image的行数,random.sample()在所有行中随机取一百个图像的行数
index = random.sample(range(train_images.shape[0]), 100)
总代码
from __future__ import print_function
import random
import tensorflow as tff
import tensorflow._api.v2.compat.v1 as tf
from keras.utils.np_utils import to_categorical
import matplotlib.pyplot as plt
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
tf.disable_v2_behavior()
(train_images, train_labels), (test_images, test_labels) = tff.keras.datasets.mnist.load_data()
train_images, test_images = train_images / 255.0, test_images / 255.0#图像归一化
train_labels, test_labels = to_categorical(train_labels), to_categorical(test_labels)
#转换成784列
train_images = train_images.reshape([-1, 784])
test_images = test_images.reshape([-1, 784])
def add_layer(inputs, in_size, out_size, activation_function=None):
weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
wx_plus_b = tf.matmul(inputs, weights) + biases
if activation_function is None:
outputs = wx_plus_b
else:
outputs = activation_function(wx_plus_b)
return outputs
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs})
correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1))#如果预测值和测试的真实值的每一行最大元素相同则为True
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))#转换为float32后算平均值得出准确率
return sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys})
xs = tf.placeholder(tf.float32, [None, 784])
ys = tf.placeholder(tf.float32, [None, 10])
prediction = add_layer(xs, 784, 10, activation_function=tf.nn.softmax)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(1000):
# train_images.shape[0]指tranin_image的行数,random.sample()在所有行中随机取一百个图像的行数
index = random.sample(range(train_images.shape[0]), 100)
batch_xs = train_images[index, ]
batch_ys = train_labels[index, ]
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys})
if i % 50 == 0:
print(compute_accuracy(test_images, test_labels))

















 1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









