






 本文详细解读了HashMap在JDK1.7与1.8版本间的变化,涉及容量计算、负载因子选择、链表转红黑树策略,以及性能提升的原因。重点介绍了为何设置0.75为负载因子,以及链表长度8作为转换阈值的科学依据。
本文详细解读了HashMap在JDK1.7与1.8版本间的变化,涉及容量计算、负载因子选择、链表转红黑树策略,以及性能提升的原因。重点介绍了为何设置0.75为负载因子,以及链表长度8作为转换阈值的科学依据。
HashMap
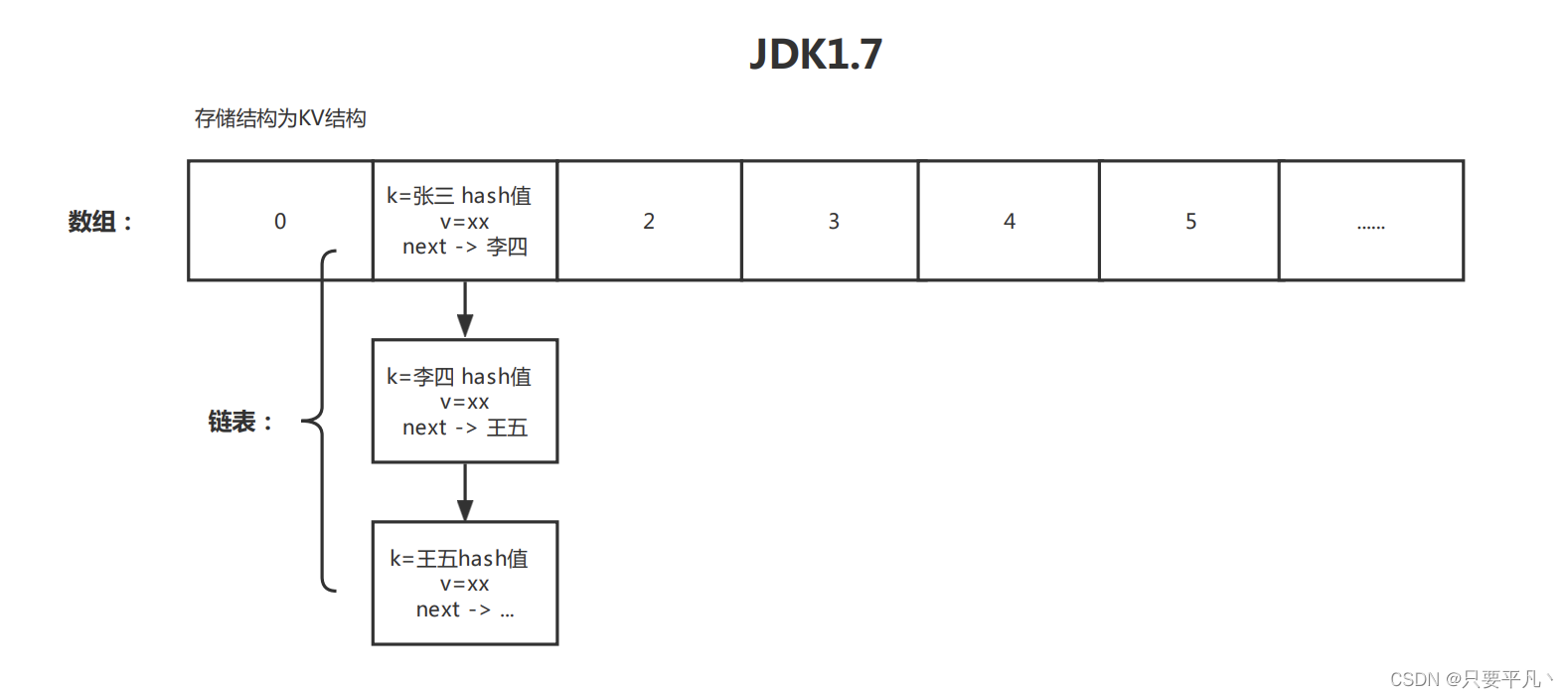
JDK1.7及之前版本的hashMap数据结构为数组+链表,JDK1.8及以后版本数据结构为数组+链表+红黑树,hashmap的容量指的是数组的大小,HashMap的get、put的时间复杂度是O(1)。
重要成员变量:
DEFAULT_INITIAL_CAPACITY = 1 << 4:Hash表默认初始容量,通过位运算设置容量
MAXIMUM_CAPACITY = 1 << 30:最大Hash表容量
DEFAULT_LOAD_FACTOR = 0.75f:默认加载因子,到达容量的百分之75之后就会扩容
TREEIFY_THRESHOLD = 8:链表转红黑树阈值
UNTREEIFY_THRESHOLD = 6:红黑树转链表阈值
MIN_TREEIFY_CAPACITY = 64:链表转红黑树时hash表最小容量阈值,达不到优先扩容。
JDK1.8引入了红黑树数据结构,当链表长度>8链表转红黑树阈值:TREEIFY_THRESHOLD = 8,并且数组长度>= 64时链表转红黑树时hash表最小容量阈值:MIN_TREEIFY_CAPACITY = 64,会把链表转成红黑树,不足64时会先扩容。
加载因子为什么是0.75?
1、当加载因子设置较大的时候,容量也就越大,扩容发生的频率就越低,浪费的空间会比较小,但此时发生 Hash冲突的几率就会提升。HashMap操作链表的时间复杂度是O(n),所以会导致运行效率降低。
2、当加载因子设置较小的时候,容量变小,发生哈希冲突的可能性也会比较小,但会浪费更多的空间,此时运行效率会提高。
其实根据牛顿二项式计算出来的最合适的结果是0.6913,但java综合了以上情况就取了一个 0.5 到 1.0 的平均数 0.75 作为加载因子
为什么链表长度大于8时再转红黑树?
在加载因子是0.75的时候,根据柏松分布概率统计学可以计算出:一个链表可能到达的长度的概率。
在JDK1.8HashMap源码中也有标注这个概率:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million //再多的话,概率就不到千万分之一了
随着链表长度越来越大,到达这个长度的概率也就越来越低,链表长度达到8的概率会极小,所以用8来做这个转红黑树的分界点。
基于红黑树的优化,在数据量较大时,JDK1.8比1.7会有5%-10%左右的性能提升,但数据量小的时候,1.7要比1.8性能更好。
JDK1.7HashMap数据结构:
HashMap整体是一个数组,数组的每个位置是一个链表,链表用来解决hash冲突问题,链表每个节点中的Value就是我们存储的Object,插入链表时采用的是头插法,新插入的数据会在最前边,旧的数据会在后边。
源码分析
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
//初始化数组
inflateTable(threshold);
}
//如果key的值为空,直接put一个空的Key
if (key == null)
return putForNullKey(value);
//计算hashCode,内部会通过位运算让hash值更加散列,尽量避免hash冲突
int hash = hash(key);
//传入hash值和数组长度,用hash & length -1,计算索引
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//判断KV是否存在
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
//如果存在,覆盖旧值
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//put进HashMap
addEntry(hash, key, value, i);
return null;
}
//初始化数组
private void inflateTable(int toSize) {
//校验容量是否是2的指数次幂,不是的话强行把size转化为最接近并且>=size的2的指数次幂的值
int capacity = roundUpToPowerOf2(toSize);
//容量*0.75
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//创建指定容量的Entry
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
/**
* put进HashMap
**/
void addEntry(int hash, K key, V value, int bucketIndex) {
//长度大于初始化长度*0.75(阈值),同时桶不为null
if ((size >= threshold) && (null != table[bucketIndex])) {
//扩容为原来的2倍
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//创建Entry的方法
createEntry(hash, key, value, bucketIndex);
}
扩容的长度是原来的2倍,并进行数据转移
void resize(int newCapacity) {
//先将旧的数组值赋值给oldTable
Entry[] oldTable = table;
//旧的数组长度
int oldCapacity = oldTable.length;
//旧的数组等于最大长度
if (oldCapacity == MAXIMUM_CAPACITY) {
//赋值为最新值
threshold = Integer.MAX_VALUE;
return;
}
//根据新的长度创建新的Table
Entry[] newTable = new Entry[newCapacity];
//把旧数组的数据转移到新数组中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
//计算容量*负载因子
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* 转移数据
**/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//遍历原来的数组
for (Entry<K,V> e : table) {
//遍历数组下面的链表
while(null != e) {
//取链表的头部节点的下一个节点数据,也就是数组中的数据
Entry<K,V> next = e.next;
if (rehash) {
//重新计算hash值
e.hash = null == e.key ? 0 : hash(e.key);
}
//计算出新的位置
int i = indexFor(e.hash, newCapacity);
//放入到对应位置
e.next = newTable[i];
//把旧的链表的头节点赋值给新数组中链表的头节点
newTable[i] = e;
//指向链表下一个节点,如果下一个节点为null的话就会跳出循环
e = next;
}
}
}
头插法存在的环形链表问题
JDK1.7中的头插法在扩容时会有一个问题,就是在扩容中转移数据时,会把链表中的数据顺序颠倒过来,在单线程中没有什么影响,但是在多线程中,会出现环形链表。
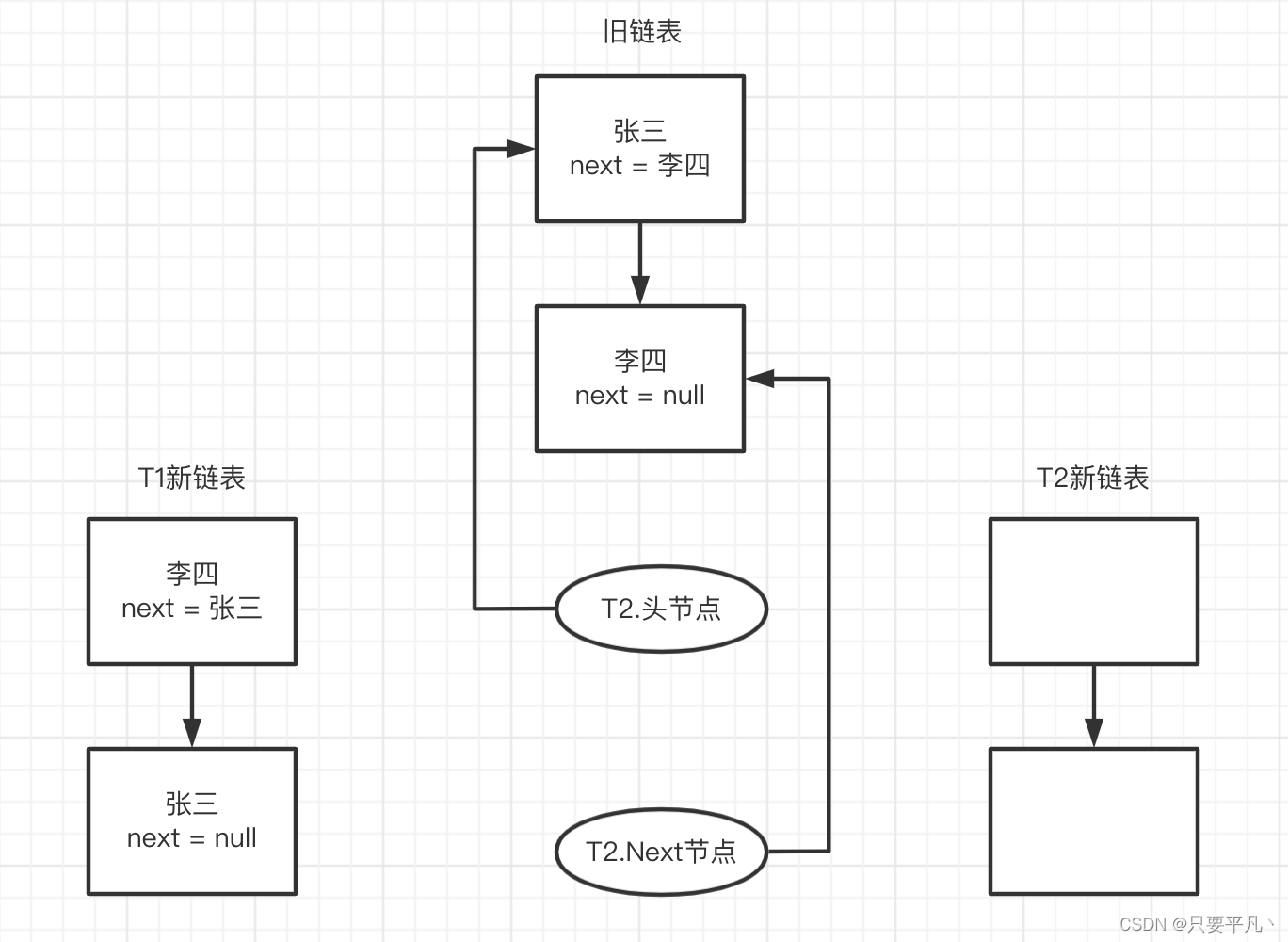
例如两个线程T1,T2对同一个HashMap进行扩容,会生成两个新的数组,并且两个线程在操作同一个链表,链表长度为2。
1、T2执行transfer遍历链表时执行到代码:
Entry<k,v> next = e.next;
此时头节点、Next节点指针分别指向了旧链表张三、李四,但还没对节点进行移动,就切换到了T1,T1执行完移动操作,此时状态如下:
T2.头节点、T2.Next节点为指针
2、此时线程又切换到T2,T1已经完成了移动,但指针还没变动,此时状态如下:
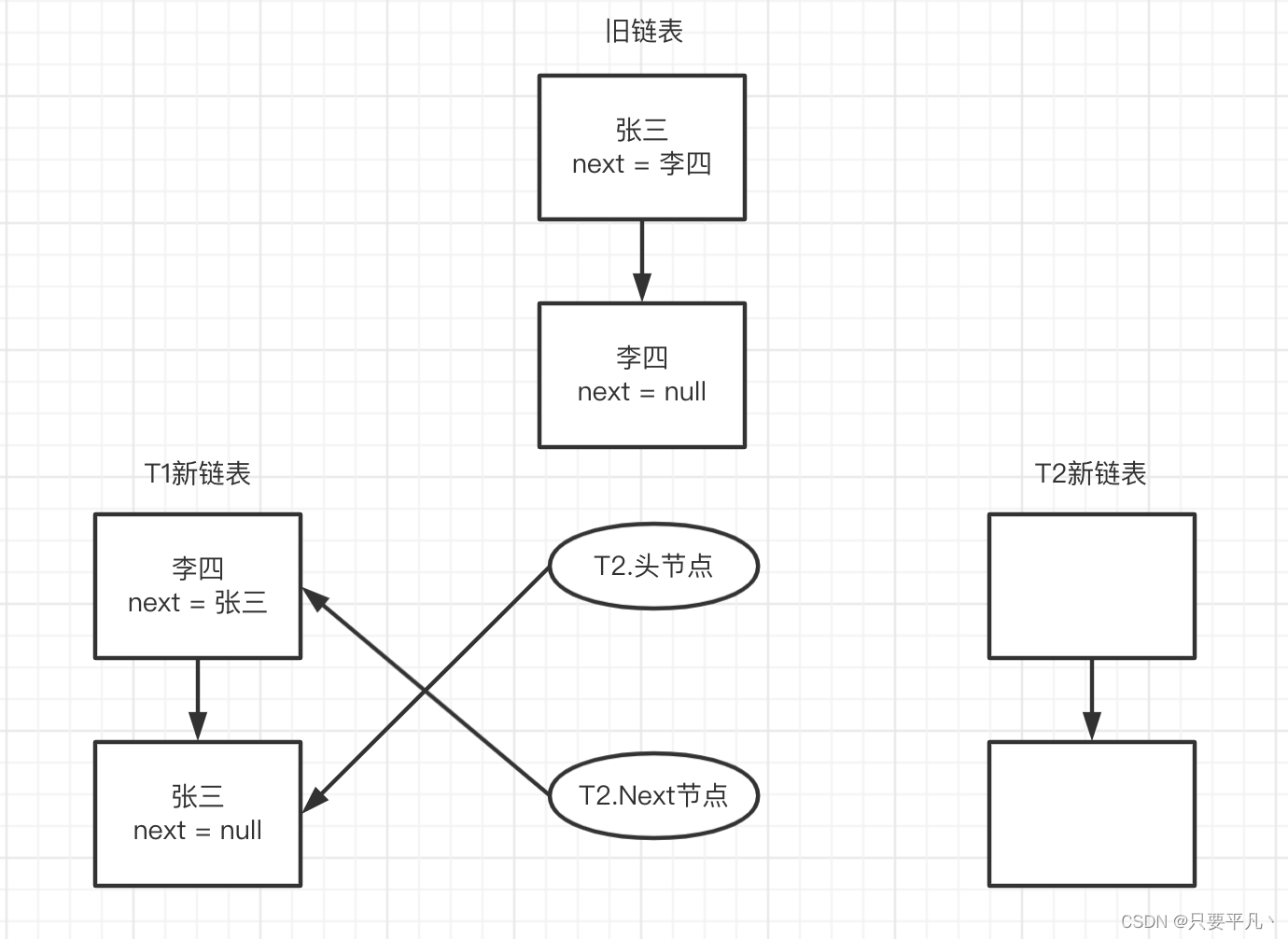
3、T2.Next指针的next指向从null变成了张三,继续执行后续代码:
e.next = newTable[i];
newTable[i] = e;
e = next;
此时张三的next = null,所以把newTable[i]指向null,再把头指针张三赋值给newTable[i],此时T2新链表头节点 = 张三,最后把next李四指向头节点,状态如下:
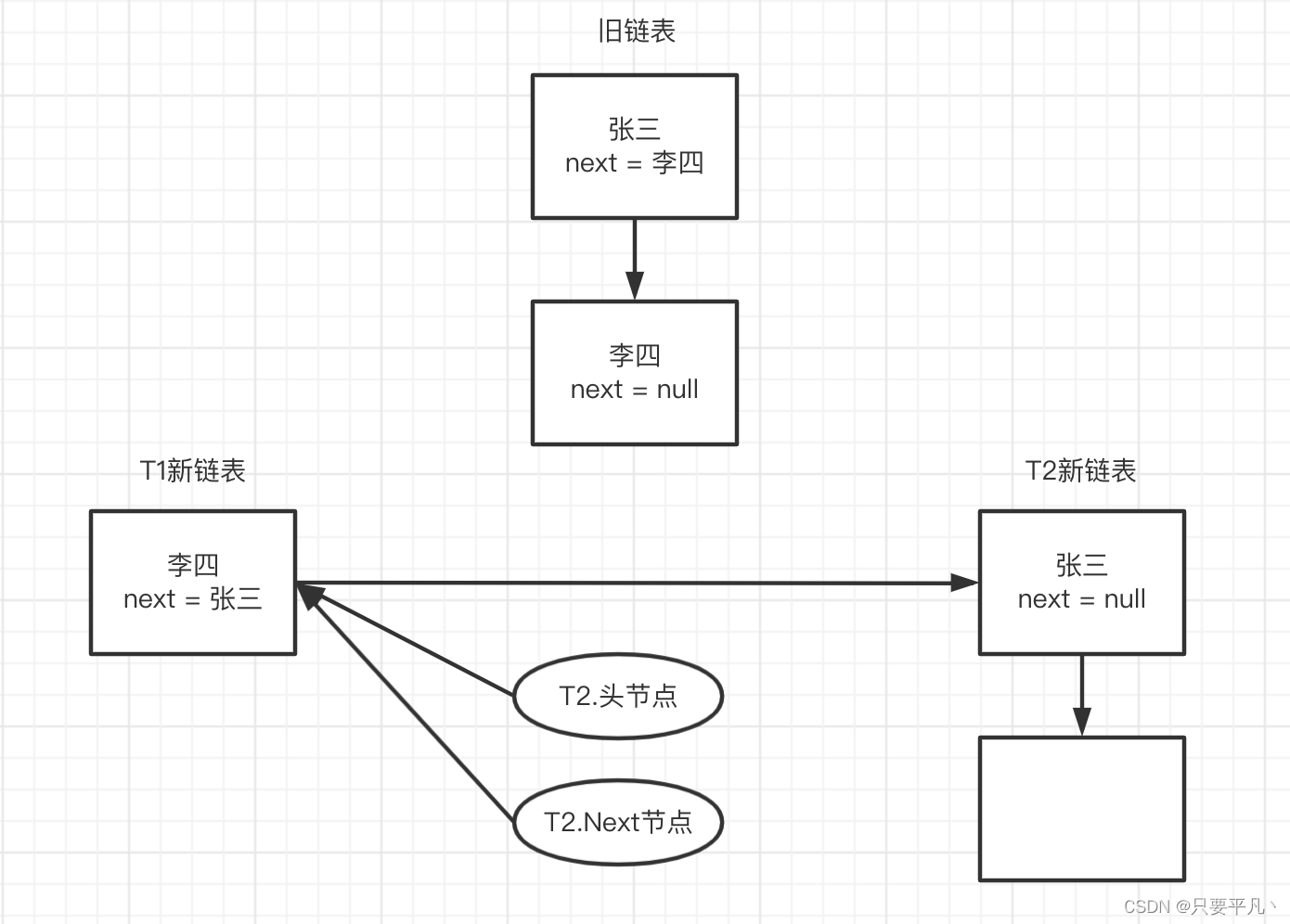
4、此时T2.头节点不为null,所以进行第二轮循环,执行代码:
Entry<k,v> next = e.next;
e.next = newTable[i];
newTable[i] = e;
e = next;
此时T2.头节点指向李四,next指向张三,把newTable[i]赋值给李四的next,然后再把李四赋值给T2新链表的头节点,最后把头节点指向张三,状态如下:
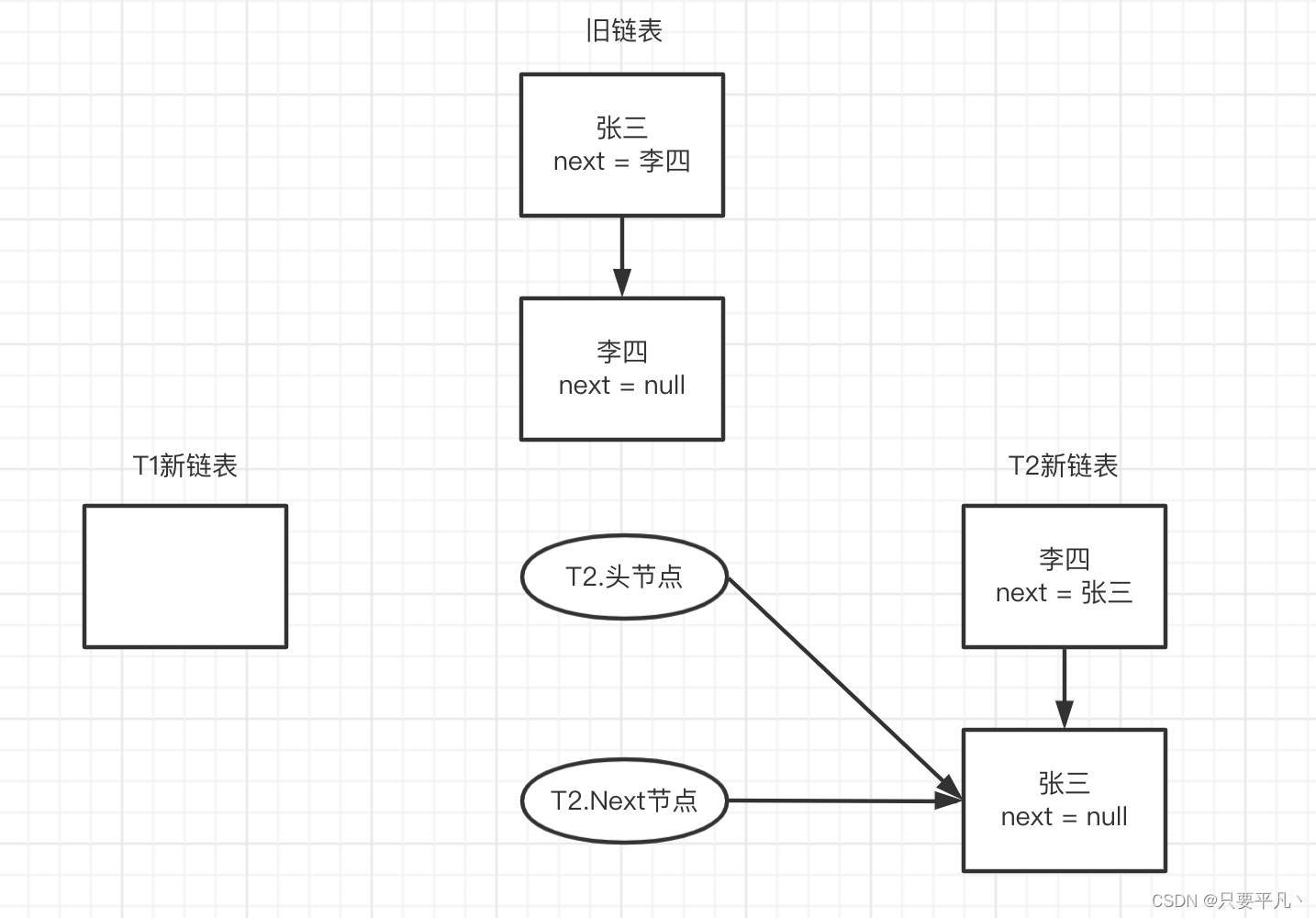
5、此时头节点还不=null,进行第三轮循环,执行代码:
Entry<k,v> next = e.next;
e.next = newTable[i];
newTable[i] = e;
e = next;
因为此时T2.头节点指向的张三,张三的next节点为null,所以next指向null,newTable[i]此时为李四,所以e.next = 李四,再把张三指向T2新链表的头节点,然后把头节点赋为null,终止了循环,状态如下:
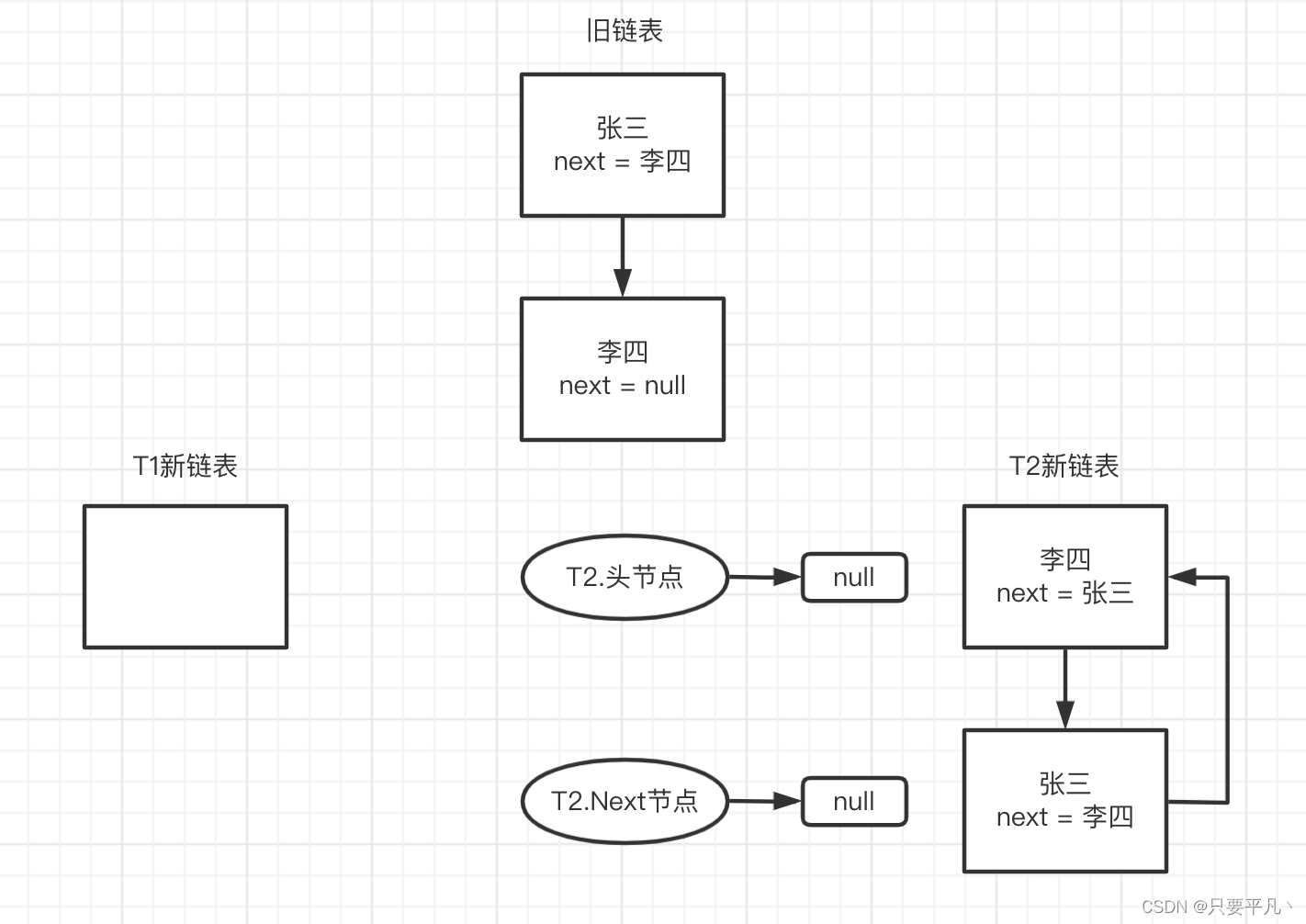
此时链表内形成闭环,此时再往链表中put新值时会循环判断链表中是否存在此key,但此时链表中已经形成了闭环,next指针永远不会是空,所以会出现死循环。
JDK1.8解决环形链表问题
对链表的数据迁移做了优化,用两组高低指针来记录元素变化。
源码分析:
else{ //低位指针
Node<K, V> loHead = null, loTail = null;
//高位指针
Node<K, V> hiHead = null, hiTail = null;
Node<K, V> next;
do {
next = e.next;
//当前节点哈希值 & 旧的数组长度 == 0 用低位指针指向
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
//当前节点哈希值 & 旧的数组长度 > 0 用高位指针指向
} else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
//把低位指针指向的节点移动到新数组中索引相同位置上
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
//把高位的移动到数组索引+旧数组长度的位置上
newTab[j + oldCap] = hiHead;
}
}
例:
一个数组大小是16,索引为3的位置有一个链表
扩容做数据迁移时,会根据当前链表每个节点的HashCode & 16计算的值做判断
因为二进制的值不管怎么&计算,都只会有两种结果,要么是0要么是&符号后边的值
如果 == 0,就用低位指针指向这个节点;如果 > 0,就用高位指针指向这个节点
假如当前链表有3个节点,第一个是由低位指针指向,第二个是由高位指针指向,第三个又是低位指针指向
此时就会取消第一和第二个节点之间的指针,把第一个直接指向第三个,最终会形成高低位两个链表。
在数据转移时,会把低位指针指向的节点移动到新数组中索引为3的位置上
把高位的移动到3+16的位置,3是旧链表索引位置,16是旧的数组长度,while结束后再根据指针进行赋值
因为数组扩容一定是2的指数次幂,所以根据此算法移动后,还是可以根据&计算来get出高位指针的值
总结:jdk1.8 是等链表整个while循环结束后,才去做转移赋值,未赋值之前使用局部变量 loHead 和 hiHead 两组指针来记录高低位,低位转移到原索引位置,高位转移到原索引+旧数组长度的索引位置,get时也是通过位运算来取高位值,因为是局部变量,所以多线程的情况下,是没有问题的。这种算法还可以应用在分库分表和在线扩容上
ConcurrentHashMap
ConcurrentHashMap的数据结构与HashMap基本类似,区别在于:
1、ConcurrentHashMap在put时加了同步机制(分段锁)保证线程安全,写同步,读无锁;
2、扩容时老数据的转移是并发执行的,这样扩容的效率更高。
3、ConcurrentHashMap的K、V不能为空,HashMap可以。
4、JDK1.8的ConcurrentHashMap采用尾插法
数据结构:
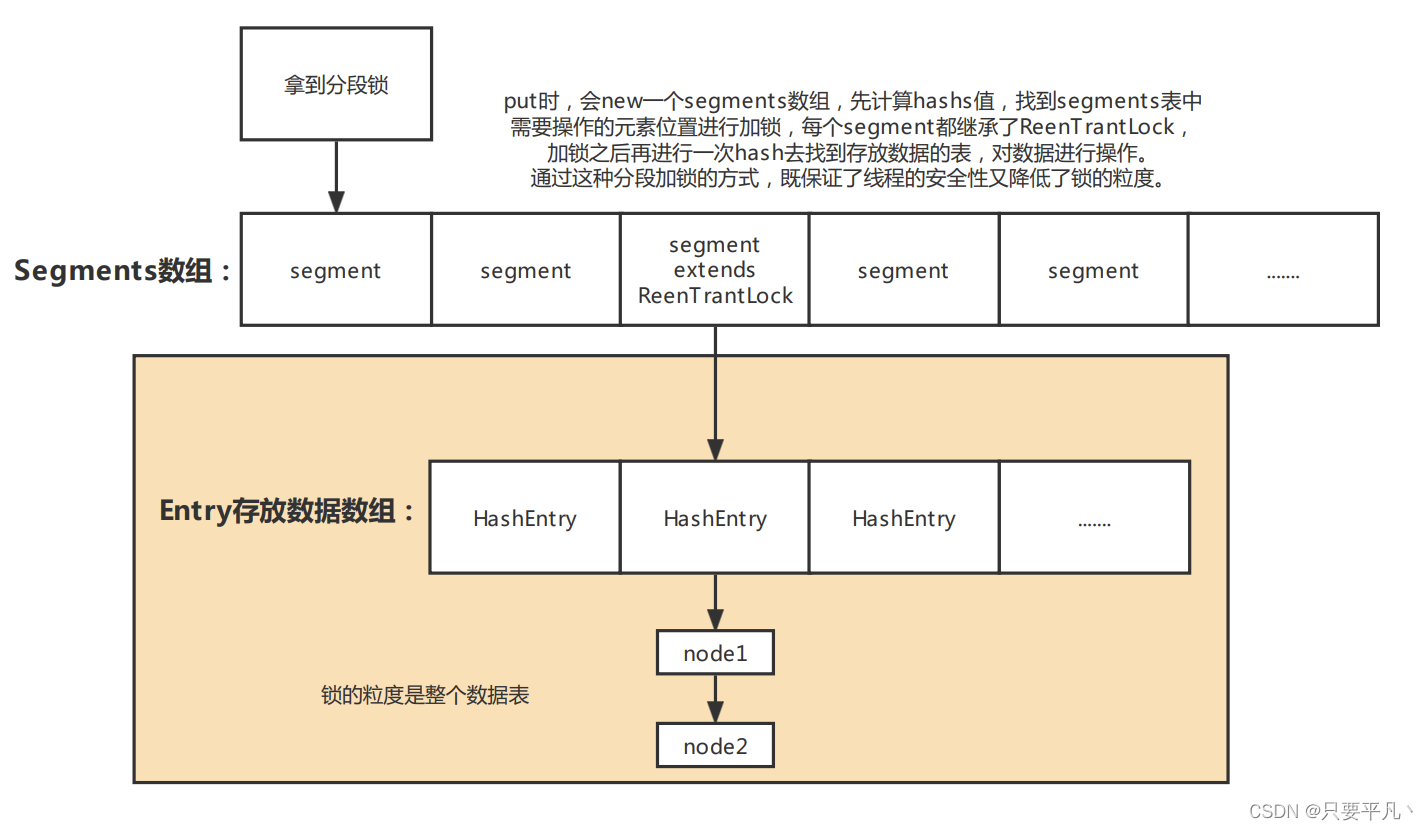
JDK1.7中 ConcurrentHashMap基于ReentrantLock实现分段锁:
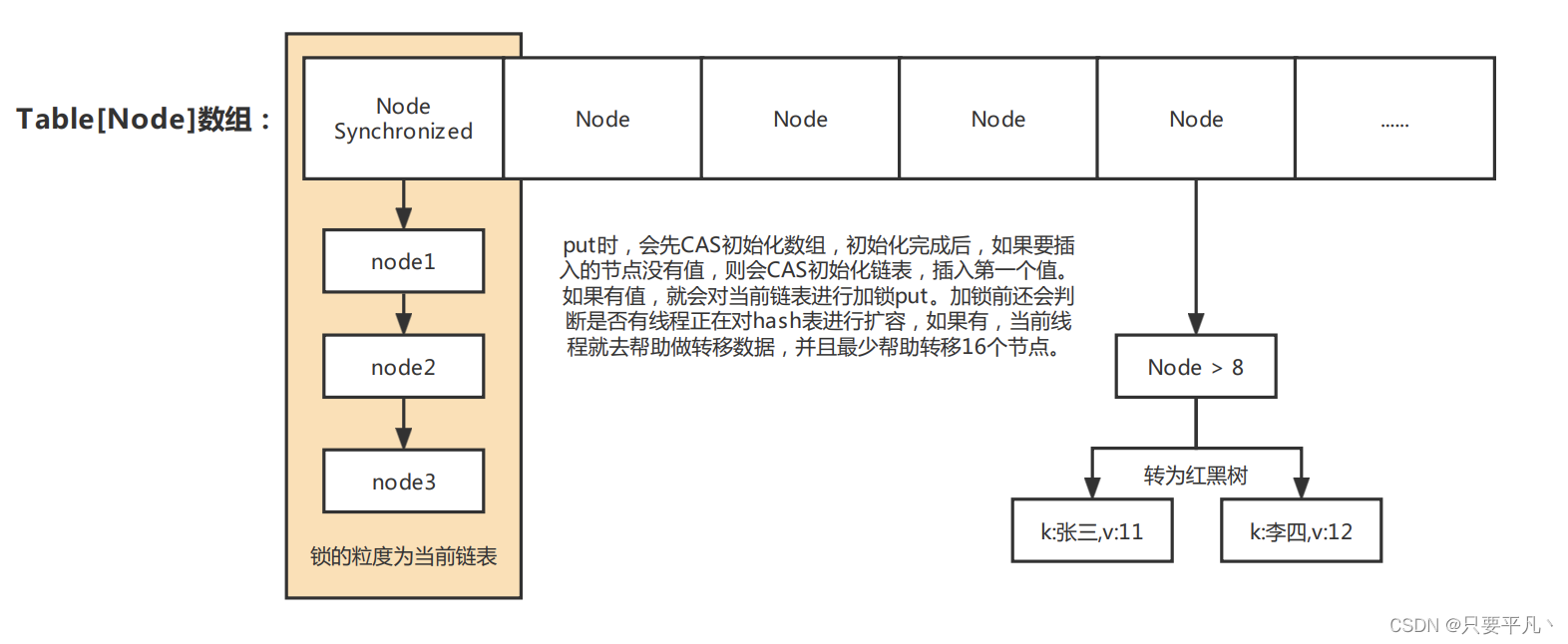
JDK1.8中 ConcurrentHashMap基于分段锁+CAS保证线程安全,分段锁基于synchronized关键字实现:
重要成员变量:
MIN_TRANSFER_STRIDE: 默认16, table扩容时, 每个线程最少迁移table的槽位个数。
MOVED: 值为-1, 当Node.hash为MOVED时, 代表着table正在扩容
TREEBIN, 置为-2, 代表此元素后接红黑树。
nextTable: table迁移过程临时变量, 在迁移过程中将元素全部迁移到nextTable上。
sizeCtl: 用来标志table初始化和扩容的,不同的取值代表着不同的含义:
0: table还没有被初始化
-1: table正在初始化
小于-1: 实际值为resizeStamp(n)<<RESIZE_STAMP_SHIFT+2, 表明table正在扩容
大于0: 初始化完成后, 代表table最大存放元素的个数, 默认为0.75*n
put源码
final V putVal(K key, V value, boolean onlyIfAbsent) {
//如果K、V为空,抛异常
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果tab为空,就进行初始化
if (tab == null || (n = tab.length) == 0)
//初始化数组,通过CAS修改状态,修改成功的线程去执行初始化
tab = initTable();
//没有修改状态失败的线程,通过K的Hash值&数组大小-1,计算出一个索引位置
//如果这个索引位置为空,说明还没有数据插入
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//开始CAS无锁状态插入数据,new一个节点存放kv
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
//插入失败的继续循环
break;
}
//如果有线程正在对hash表进行扩容,就去帮助转移数据
else if ((fh = f.hash) == MOVED)
//帮助转移方法
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//表示桶中已经有节点存在,对当前桶进行加锁
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
//记录该链表的长度
binCount = 1;
//构建链表逻辑
for (Node<K,V> e = f;; ++binCount) {
K ek;
//判断key是否存在
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
//如果存在,覆盖当前值
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
//如果key不存在,用尾插法进行插入
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//判断是否需要转成红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
//初始化数组
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield();
//SIZECTL默认为0,表示table还没有被初始化
//通过CAS去修改状态(抢锁)
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
判断是否需要帮助扩容:
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) { //table扩容
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
// 根据length得到一个标识符号,用来分配需要帮助的节点
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {//说明还在扩容
//判断是否标志发生了变化 ||扩容结束
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
//达到最大的帮助线程 || 判断扩容转移下标是否在调整(扩容结束)
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
//如果线程帮助扩容了,CAS将sizeCtl+1 (表示增加了一个线程帮助其扩容)
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
//真正帮助扩容方法
//每个线程最少会帮助迁移16个槽位的数据
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
CopyOnWrite机制
在对同一个ArrayList读写同时操作的的场景下,基于failfast失败快速重试机制会抛异常,代码如下:
public class CopyOnWriteArrayListRunner {
//读线程
private static class ReadTask implements Runnable {
List<String> list;
public ReadTask(List<String> list) {
this.list = list;
}
public void run() {
for (String str : list) {
System.out.println(str);
}
}
}
//写线程
private static class WriteTask implements Runnable {
List<String> list;
int index;
public WriteTask(List<String> list, int index) {
this.list = list;
this.index = index;
}
public void run() {
list.remove(index);
list.add(index, "write_" + index);
}
}
public void run() {
final int NUM = 10;
List<String> list = new ArrayList<String>();
for (int i = 0; i < NUM; i++) {
list.add("main_" + i);
}
ExecutorService executorService = Executors.newFixedThreadPool(NUM);
for (int i = 0; i < NUM; i++) {
executorService.execute(new ReadTask(list));
executorService.execute(new WriteTask(list, i));
}
executorService.shutdown();
}
public static void main(String[] args) {
new CopyOnWriteArrayListRunner().run();
}
}
CopyOnWriteArrayList通过CopyOnWrite机制解决了这个问题
CopyOnWrite核心思想:读写分离,空间换时间,避免并发导致的激烈的锁竞争。
1、CopyOnWrite适用于读多写少的场景,最大程度的提高读的效率,但写多读少的场景会频繁触发fullGc;
2、CopyOnWrite是最终一致性,写的过程中,写前的读数据不会更新,只有写后的读才能读到最新数据;
3、使用volatile变量可以使其他线程能及时读到新的数据;
4、写的时候不能并发写,需要对写操作进行加锁;
以下是源码:
//写AIP
public boolean add(E e) {
final ReentrantLock lock = this.lock;
//加锁
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//复制一个Array副本
Object[] newElements = Arrays.copyOf(elements, len + 1);
//往副本里写数据
newElements[len] = e;
//把副本替换原本,成为新的原本
setArray(newElements);
return true;
} finally {
//解锁
lock.unlock();
}
}
//读API
public E get(int index) {
return get(getArray(), index); //无锁
}
CopyOnWriteArraySet底层也是调用了CopyOnWriteArrayList解决读写并发的问题。

















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









