






 本文介绍了将多尺度分析融入Transformer架构,提出Multi-resolutionTime-SeriesTransformer(MTST),通过分支特定tokenization和相对位置编码改进了时间序列预测。MTST通过多个不同大小的补丁处理,灵活应对不同频率的时间模式,而非依赖于上/下采样。尽管存在一些现有工作的借鉴,但MTST的独特融合策略展示了其在时间序列预测领域的潜在价值。
本文介绍了将多尺度分析融入Transformer架构,提出Multi-resolutionTime-SeriesTransformer(MTST),通过分支特定tokenization和相对位置编码改进了时间序列预测。MTST通过多个不同大小的补丁处理,灵活应对不同频率的时间模式,而非依赖于上/下采样。尽管存在一些现有工作的借鉴,但MTST的独特融合策略展示了其在时间序列预测领域的潜在价值。
【论文笔记】
时间序列预测Multi-resolution Time-Series Transformer for Long-term Forecasting
文章是阅读论文后的个人总结,可能存在理解上的偏差,欢迎大家一起交流学习,给我指出问题。
1.问题回顾
最近的架构通过将时间序列分割成补丁,并使用这些补丁作为标记来学习复杂的时间模式。补丁的大小控制了变压器学习不同频率时间模式的能力:较短的补丁对学习局部、高频模式有效,而挖掘长期季节性和趋势需要较长的补丁。受到启发作者提出了多分辨率融合的Transformer(MTST)。
2.方法
2.1Branch specific tokenization
这里分patch的方法是借鉴PatchTST这篇文章的工作,本文作者只是在每层总增加了一共B(n)这样的分支。
这个式子是计算一个分支中的patch数量
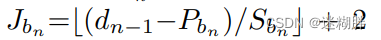
这个式子表达的是一个分支的最终结果,输入到transformer结构中的input
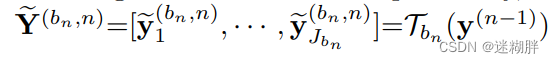
这个式子计算的分支中第j列的结果
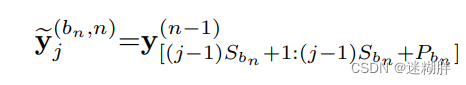
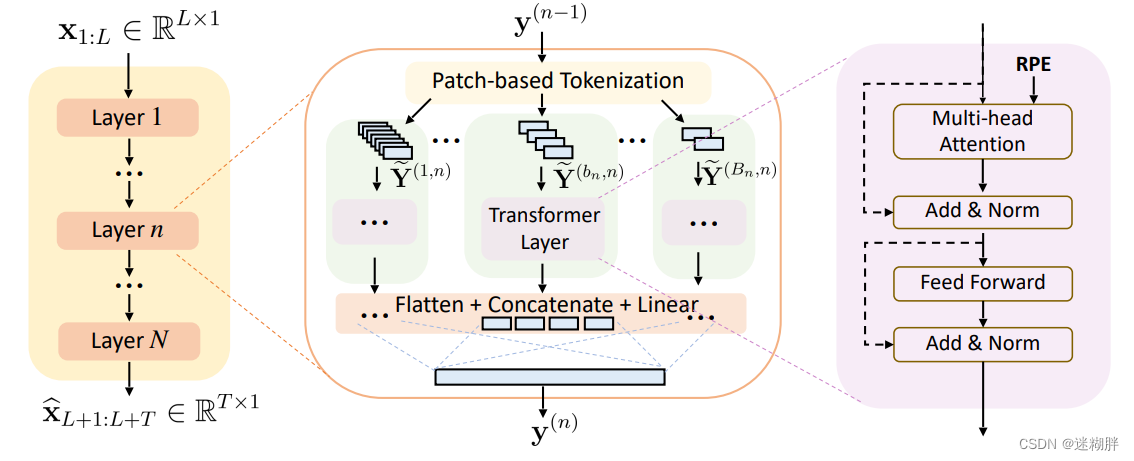
2.2 Self-attention
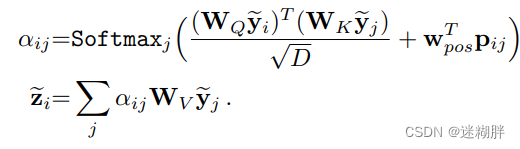
2.3 Relative positional encoding
本文提出的是相对位置编码,相比传统Transformer的绝对位置编码,说的是这个工作能更好提高准确性。下面式子中的t是变化的,实现了相对位置的编码。原本Transformer是dmodel是token的维度
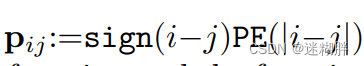
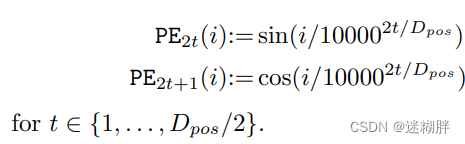
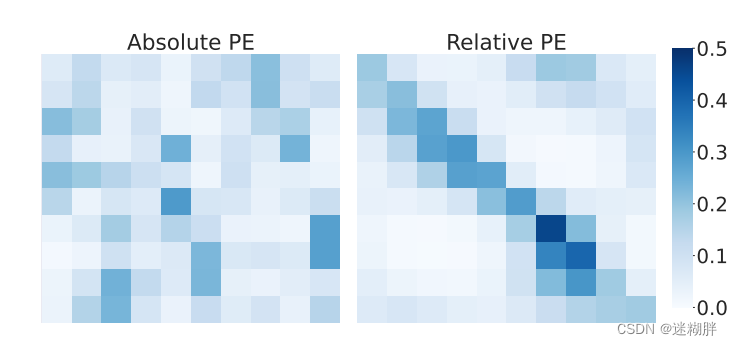
2.4 Fusing representations from all branches
在每一层, 来自所有分支的令牌表示被融合成一个单一的嵌入。这样可以跨尺度共享信息,有助于学习时间序列的表现性表示。 融合通过依次应用展开、连接和线性变换来实现。
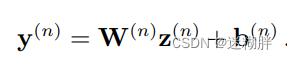
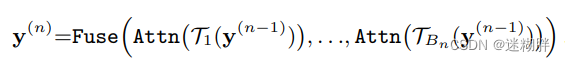
总结:将多尺度分析整合到基于补丁的时间序列Transformer中,并相应地提出了一种新的框架,称为多分辨率时间序列Transformer(MTST),用于预测。与先前工作中使用的上/下采样技术相反,我们在每个MTST层中使用具有不同补丁大小的多个基于补丁的标记化,结合多分支Transformer架构,这使得能够灵活地建模不同尺度的时间模式。此外,我们提出将相对位置编码纳入到我们的设计中。
个人总结:这篇文章创新点不够,分patch的操作是用的PatchTST这篇文章的,对Transformer模型的改进也很少,就是将绝对位置编码改为相对位置编码,然后在注意力机制模型中的计算也就是计算不同分支下patch之间的注意力分数。综合来看感觉本文就是将几篇文章的观点融合了,而且这个多尺度patch融合的操作也出现了不少出色的工作。

















 1273
1273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









