






状态后端
状态后端的概念

状态后端的类型
1、MemoryStateBackend
内存级的状态后端, 会将键控状态作为内存中的对象进行管理, 将它们存储在 TaskManager 的 JVM 堆上;而将 checkpoint 存储在 JobManager 的内存中。
应用: 因为不太稳定,用在测试,调试,开发环境中。
2、FsStateBackend
将 checkpoint 存到远程的持久化文件系统( FileSystem)上。而对于本地状态, 跟 MemoryStateBackend 一样, 也会存在 TaskManager 的 JVM 堆上。
集群启动的时候,默认配置文件里面配置的是FsStateBackend。内存比较小,状态比较多。那么就得RocksDBStateBackend。访问速度比磁盘化的性能好,要求访问快的话,内存小的话就得加机器。
3、RocksDBStateBackend
将所有状态序列化后,存入本地的 RocksDB 中存储。类似于一个数据库。性能略低,读取数据需要序列化和反序列化。
注意: RocksDB 的支持并不直接包含在 flink 中, 需要引入依赖:
// 2.12是scala版本,1.10.1是flink版本。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.12</artifactId>
<version>1.10.1</version>
</dependency>

状态后端的配置
env.setStateBackend(new FsStateBackend(" xxxxxx “)) //里面可以写一个hdfs的路径
env.setStateBackend(new RocksDBStateBackend(” xxxx "))
//可以写一个路径,比如,c盘,d盘下的一个文件路径。也可以是hdfs上的路径。
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.设置状态后端
env.setStateBackend(new MemoryStateBackend());
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flink/flinkCk"));
env.setStateBackend(new RocksDBStateBackend("hdfs://hadoop102:8020/flink/flinkCk"));
容错机制
状态不丢,重新读取状态,再去处理。容错机制,就是所说的,把状态保存下来,做存盘。
一致性检查点(checkpoint)
对所有的任务进行一个存盘。
在某个时间点拷贝一份数据,这个时间点就是所有任务处理完相同的输入数据的时候。
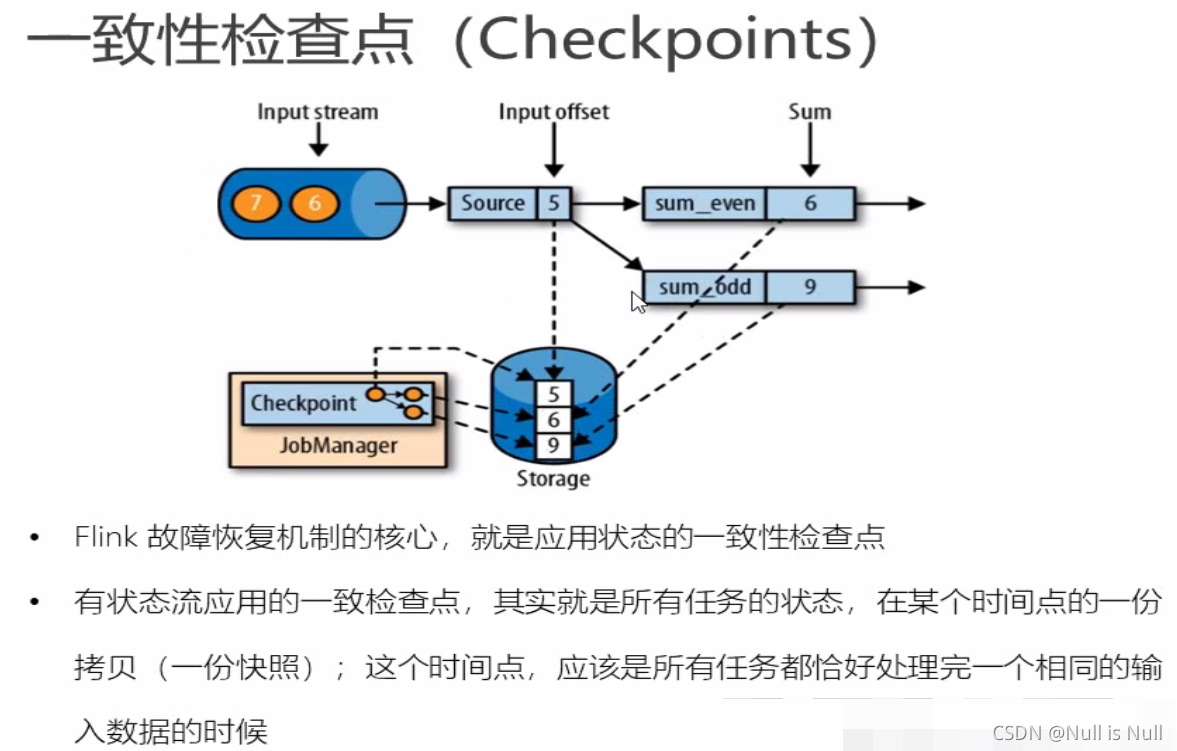
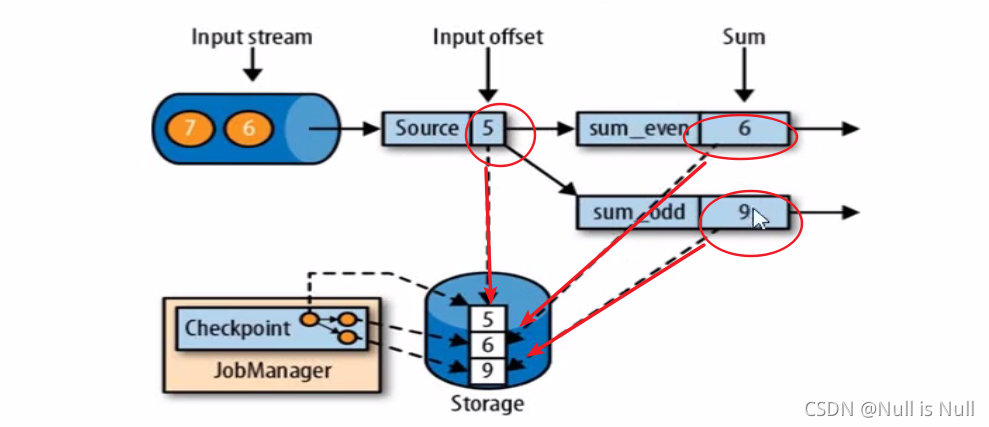
如图所示,保存5处理完的时候的状态,上面加的是偶数 2+4,下面加的是奇数 1
3+5,虽然5只走下面,但是也相当于两个方向处理完了,上面那个对奇数选择不要,也是一种处理方式。
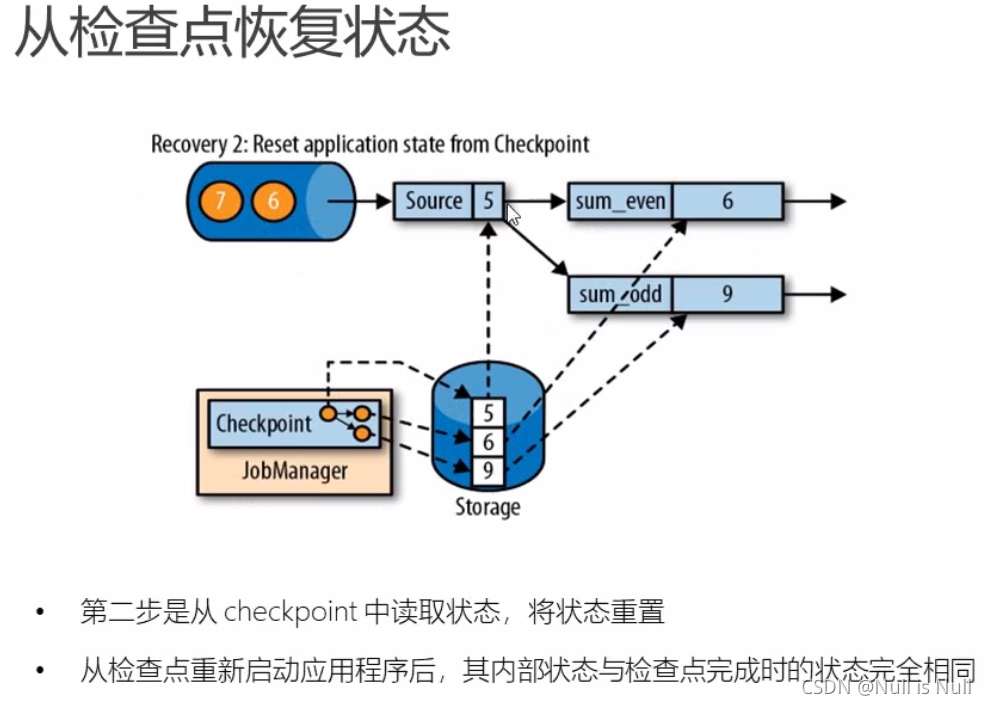
两个地方都处理完,也就是所有任务都处理完,才会对本次状态进行保存。 恢复的时候,5以前的数据都处理完了,那么就开始处理5之后的数据。
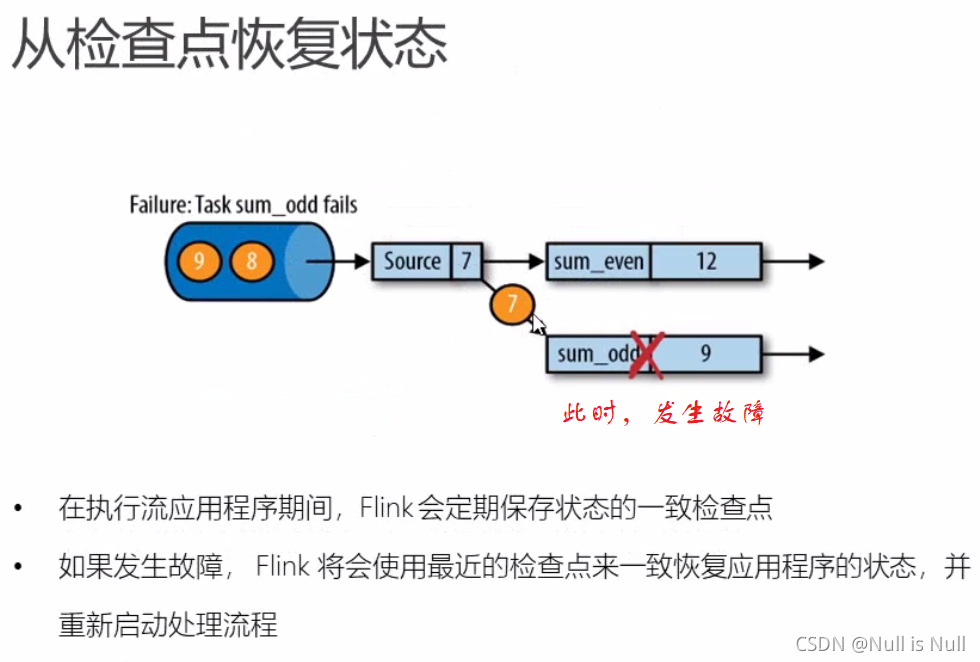
恢复
处理奇数7的时候,突然发生故障。
重启应用
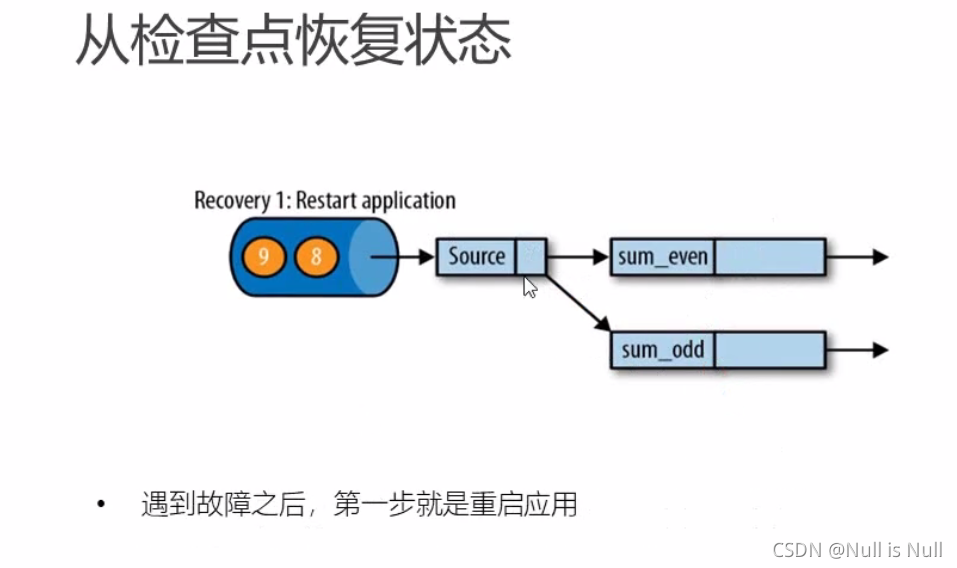
加载最近保存成功的检查点。把状态读进来。
从6开始继续消费。
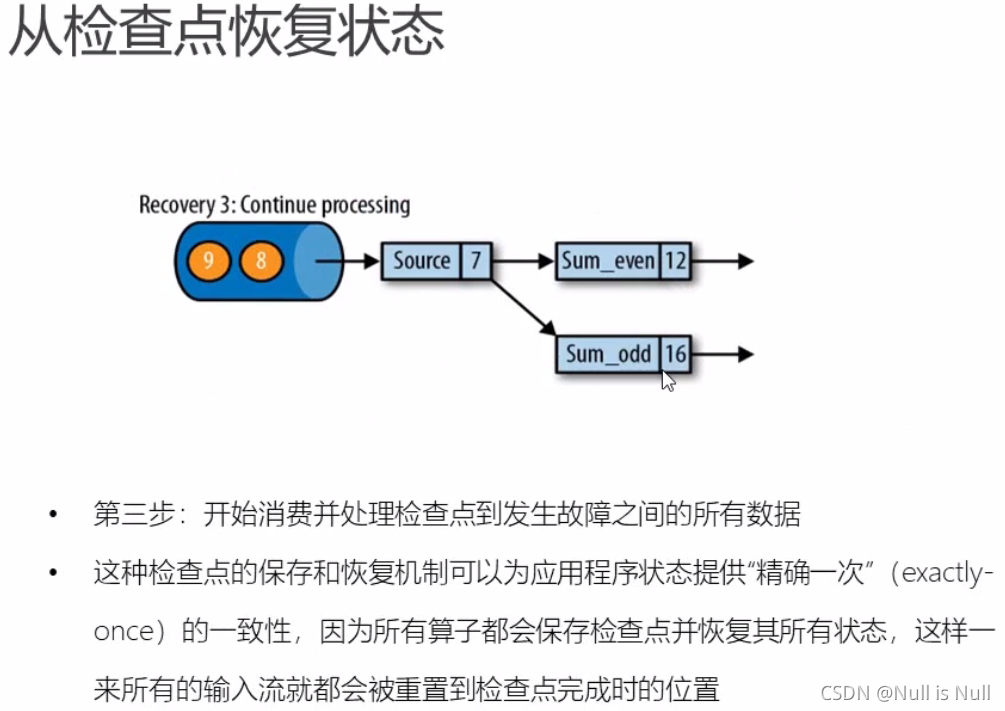
检查点算法

检查点checkpoint的配置
开发环境这些都不重要,生产环境最重要的是前三项,要根据任务的特点去配置。
//3.CK配置
//3.1 设置两次CK开启的间隔时间
env.getCheckpointConfig().setCheckpointInterval(5000L);
//3.2 设置CK模式
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//3.3 设置CK超时时间
env.getCheckpointConfig().setCheckpointTimeout(1000L);
//3.5 设置同时最多有多少个CK任务
env.getCheckpointConfig().setMaxConcurrentCheckpoints(3);
//3.6 CK失败之后的重试次数
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2);
//3.7 两次CK之间的最小间隔时间(头尾)
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000L);
//3.8 如果存在更近的SavePoint,是否采用SavePoint恢复
env.getCheckpointConfig().setPreferCheckpointForRecovery(false);
//4与7之间是存在矛盾的,因为有间隔时间(上一个ck的和下一个ck的头至少间隔1s钟的时间),所以无法同时执行多个ck任务。
//所谓的同时,就是上一个ck的尾部和下一个ck的头部之间是有重叠的,也就是上一个ck的尾部与下一个ck的头部没有间隔时间。
//4.重启策略
//4.1 固定延迟重启策略,默认值是Long的最大值,所以必须配置重启策略。
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.seconds(5)));
//4.2 失败率重启策略
//每隔50s会尝试重启3次,这三次的时间间隔是5s。就是每个50s内会重启3次,其中这三次的间隔时间是5s。
env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.seconds(50),Time.seconds(5)));
注意里面的Time的包的引用。

保存点 savepoint
有计划的手动备份,在哪些特殊的时间点,去存一份当前的备份,比checkpoint自动存盘的意义就更加明确一点。知道什么样时间点、什么样的功能完成之后,进行的状态。
把当前的应用直接停掉,发现应用有bug或者说有特殊的需求,先停掉,然后修bug,代码更新之后,再进行重新启动。怎么停的呢?停的时候保存一份savepoint,从当前的savepoint重新启动就可以了。前提是状态的定义和整体任务的结构不能更改。
状态,名称,类型不能变。
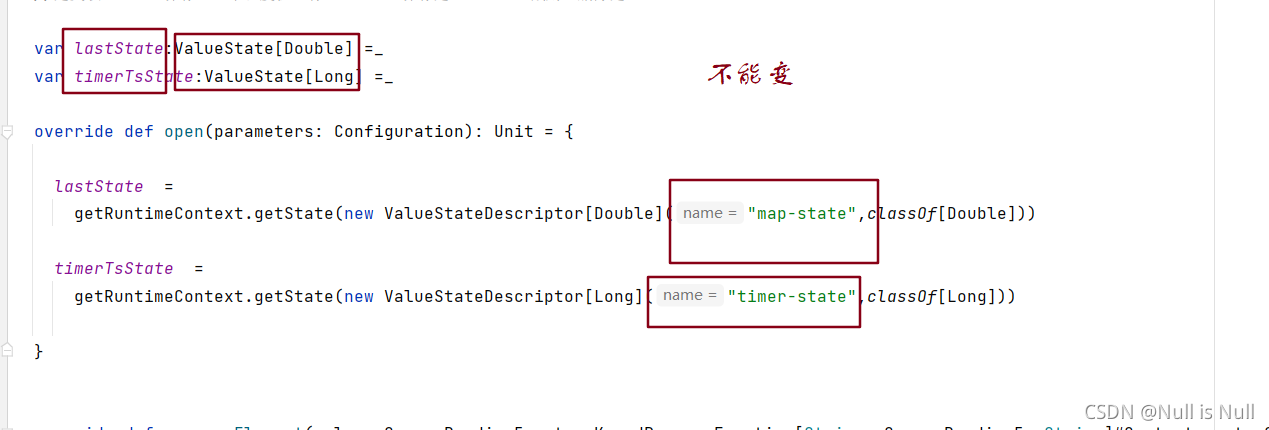
算子不能变的主要含义是:算子的id不能变。推荐是把uid指定出来。指定uid的话,再做控制的话,就不会根据dag的位置不同,而导致任务的id不同。
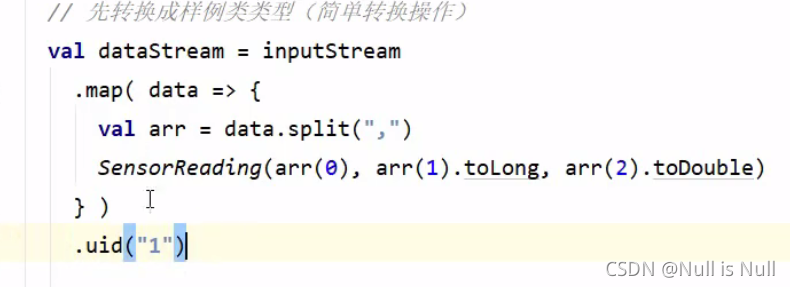
如果不做指定的话,后面的uid都会发生变化。如果指定了的话,在uid前面再做一个map,后面就不会发生变化。
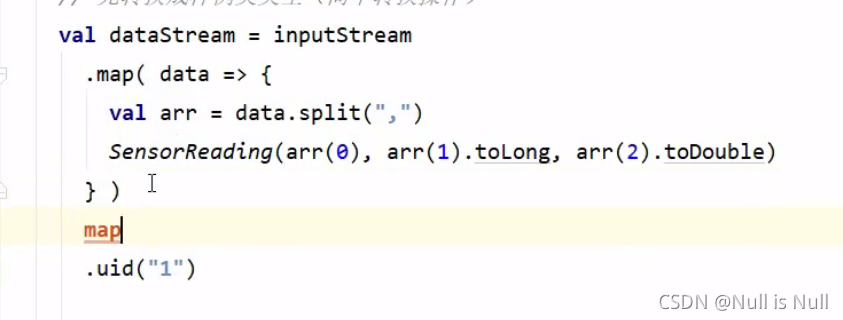
应用程序可以更改,集群环境也可以更改,可以做版本迁移。比如说,flink1.9升级到1.10的话,直接停掉,把当前的任务保存一个savepoint,然后集群直接迁移到1.10之后,然后再从savepoint中启动起来。
资源的动态调配,暂停再重启。集群资源比较紧缺,机器同时跑很多个应用和job,
这些job可能是很重要的不能停的,特别重要的。那些不太重要的应用,就可以先暂停掉,等比较重要的耗费资源的job运行完之后,再从savepoint中恢复。


















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









