







文章目录
-
-
- 一、hive组件
- 二、hive优化
- 三、遇到的SQL
-
- 1、case ... when....
- 2、非重复的计数
- 3、某个字段的值属于某些值,给个标记。
- 4、没有关联条件创造关联
- 5、分组查询
- 6、union all 的使用
- 7、判断表中某个字段是否唯一
- 8、group by 与order by同时出现
- 9、多张表关联的标准写法,用with 临时表 as。
- 10、让自己很是头疼的union all
- 11、有时候不注意的地方
- 12、客户号、权益(理解为搞活动,活动可以无限次使用)、使用时间。
- 13、出现次数 与 出现的种类次数
- 14、简单统计
- 11、如果要判断指定字符串出现的次数则:
- 15、事实表对应多维度表
- 16、临时表可以调用临时表。
- 17、同一张表进行分组最后成同一个字段
- 18、临时表的问题
- 四、SQL的练习
-
一、hive组件
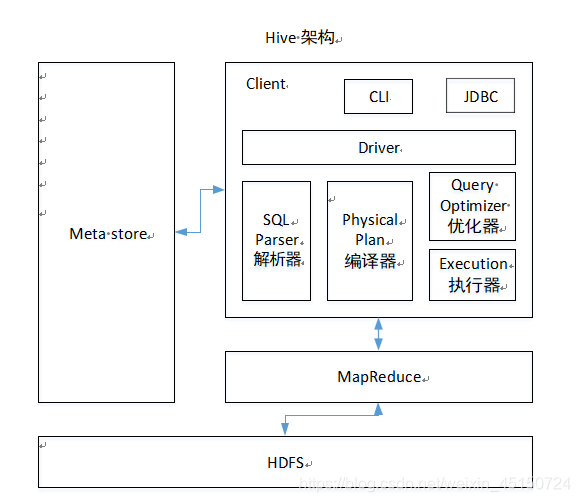
1、hive数据储存在hdfs上。
2、MapReduce,将SQL翻译为MapReduce任务。
3、metastore,元数据的储存。(默认存储在自带的derby 数据库中,推荐使用MySQL 存储Metastore)
表中有哪些字段,每个字段是哪些类型,表中有多少的数据量,在hdfs上有多少个文件,有多少行,有多大。这些都是元数据信息。
hive是将MySQL中的信息和hdfs中的信息做了一个双映射关系。当我们查询一张表的时候,先从MySQL中读取到这张表的元数据信息,然后根据元数据的指引,从hdfs上把数据找回。在这个过程中,如果使用到sum,count这种计算的函数,那么将会启用MapReduce任务。
上面3个,就是hive依赖的第三方组件。

1、client: 是客户端,提交一个SQL必然有客户端。连接客户端有两种方式。一种方式是Cli,普通的打开bin/hive,这样的方式;一种方式是JDBC,通过hiveserver2的方式,JDBC的方式连接,hive中提供一个beeline客户端,就是通过JDBC。
2、driver:连接客户端与服务端的桥梁。
3、真正的组件
1)解析器
将SQL解析成语法,判断语法是否正确,校验SQL,并不能真正的运行。
2)编译器
将抽象得到的语法 ,编译成执行任务,也就是operater tree操作树这样的内容。
3)优化器
对SQL进行优化,每一个优化的参数,都对应一个优化器。翻译成mr任务的时候会遍历所有的优化器(前提是开了这个属性)。
4)执行器
经过优化之后,任务被翻译成task tree。拿到任务树去执行。执行器会把任务树封装成一个mr任务当中,去做提交。
1(解析器).进入程序,利用Antlr框架定义HQL的语法规则,对HQL完成词法语法解析,将HQL转换为为AST(抽象语法树);遍历AST,对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。抽象出查询的基本组成单元QueryBlock(查询块),可以理解为最小的查询执行单元;
2(编译器).遍历QueryBlock,将其转换为OperatorTree(操作树,也就是逻辑执行计划),可以理解为不可拆分的一个逻辑执行单元;
3(优化器).使用逻辑优化器对OperatorTree(操作树)进行逻辑优化。例如合并不必要的ReduceSinkOperator,减少Shuffle数据量;
4(执行器).遍历OperatorTree,转换为TaskTree。也就是翻译为MR任务的流程,将逻辑执行计划转换为物理执行计划;使用物理优化器对TaskTree进行物理优化(mapjoin等优化);
6.生成最终的执行计划,提交任务到Hadoop集群运行。
SQL执行顺序
1、FROM:这个只需要说一点的是JOIN这一步包含在FROM里面,总之就是先确定表,加载所有表的所有行。(from相当于是加载了这张表,执行顺序在select之前的,都可以选择任意一个字段,因为是整张表的加载。)
2、WHERE:过滤掉不需要的行
3、GROUP BY:根据表达式或者列名来聚合(分组),分组完成后,所有的列只剩下了作为组名的列,组内部只对聚合函数可见。
4、聚合函数:聚合函数相当于可以进入分组的内部,然后计算出一个只有一个值的结果,例如组内的最大最小平均总和。(聚合函数是对一列的聚合)
5、HAVING:过滤掉—聚合后—的不需要的行
6、窗口函数:在此时的所有行开窗口,并在窗口内执行窗口函数
7、SELECT:选择需要的列,也叫project,投射
8、DISTINCT:在选择的列里面进行(xing)行(hang)去重
9、UNION,INTERSECT,EXCEPT:对得到的结果进行集合操作
10、ORDEY BY:对进行完集合操作后得到的结果集排序
11、OFFECT:没见过,不知道是干嘛的,别人说“Don’t use offset”
12、LIMIT,FETCH,TOP:最后选择前几行作为最终的结果
二、hive优化
1、谓词下推(默认开启)
谓词,是指用来描述或判断客体性质、特征或客体之间关系的词项。在SQL中即返回值为布尔值的函数。
谓词下推,在Hive中叫Predicate Pushdown,含义是指在不影响结果的前提下,尽量将过滤条件提前执行,使得最后参与join的表的数据量更小。谓词下推后,过滤条件将在map端提前执行,减少map端输出,降低了数据传输IO,节约资源,提升性能。
在Hive中通过配置hive.optimize.ppd参数为true,开启谓词下推,默认就是true开启状态。
1)表的分类
1. Preserved Row table:保留表
a left (outer) join b 中的 a 表;
a right (outer) join b 中的 b 表;
a full outer join b a 和 b 表都是 保留表。
2. Null Supplying table:提供null值的表,也就是 非保留表,在join中如果不能匹配上的使用null填充的表。
a left (outer) join b 中的 b 表;
a right (outer) join b 中的 a 表,
a full outer join b a 和 b 表都是 null值保留表
3. During Join predicate:join中谓词,就是on后面的条件。
R1 join R2 on R1.x = 5 --> R1.x = 5就是join中谓词
4. After Join predicate:join后谓词,就是where后面的条件。
a left join b where a.t=1 --> a.t=1 就是join后谓词
2)Left outer Join & Right outer Join
!!!测试时,关闭 cbo 优化:set hive.cbo.enable=false
案例一:过滤条件写在 where, 且是 保留表的字段
explain
select o.id from bigtable b
left join bigtable o
where b.id <= 10;
--> 可以谓词下推(能在 map 阶段提前过滤)
案例二:过滤条件写在 where, 且是 非保留表的字段
explain
select b.id,o.id from bigtable b
left join bigtable o
where o.id <= 10;
--> 不可以谓词下推(能在 map 阶段提前过滤)
案例三:过滤条件写在 on, 且是 保留表的字段
explain
select o.id from bigtable b
left join bigtable o
on b.id <= 10;
--> 不可以谓词下推(不能在 map 阶段提前过滤)
案例四:过滤条件写在 on, 且是 非保留表的字段
explain
select o.id from bigtable b
left join bigtable o
on o.id <= 10;
--> 可以谓词下推(能在 map 阶段提前过滤)
=总结=
在关闭cbo的情况下:

默认的情况下,是开启的,也就是true,只有 保留字段(left的左表) - on 这个是不可以的。因为作为主表,在关联的时候要保证数据的完整性。
!!!注意:
1、对于 Left outer Join ,右侧的表写在 on后面、左侧的表写在 where后面,性能上有提高;
2、对于 Right outer Join,左侧的表写在 on后面、右侧的表写在 where后面,性能上有提高;
3)Full outer Join
案例一:过滤条件写在 where, 且是 保留表的字段
explain
select o.id from bigtable b
full join bigtable o
where b.id <= 10;
--> 可以谓词下推(能在 map 阶段提前过滤)
案例二:过滤条件写在 where, 且是 非保留表的字段
explain
select b.id,o.id from bigtable b
full join bigtable o
where o.id <= 10;
--> 可以谓词下推(能在 map 阶段提前过滤)
案例三:过滤条件写在 on, 且是 保留表的字段
explain
select o.id from bigtable b
full join bigtable o
on b.id <= 10;
--> 不可以谓词下推(不能在 map 阶段提前过滤)
案例四:过滤条件写在 on, 且是 非保留表的字段
explain
select o.id from bigtable b
full join bigtable o
on o.id <= 10;
--> 不可以谓词下推(不能在 map 阶段提前过滤)
=总结=
1. 如果不开启 cbo,写在 on后面,还是 where后面,都不会谓词下推
2. 默认的话,是开启了 cbo,写在 where 可以 谓词下推, 写在 on 不可以 谓词下推。因为要保证关联的时候数据的完整性,on后面不能谓词下推。
-- 也就是说,full join的时候,只有开启cbo的时候,where后面可以谓词下推。
4)inner Join
Inner Join 不管有没有开启cbo,不管写在 on后面 还是 where后面,都会进行谓词下推。
2、MapJoin(默认开启)
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理
开启MapJoin参数设置
设置自动选择Mapjoin( 默认为true):set hive.auto.convert.join = true;
大表小表的阈值设置(默认25M一下认为是小表):set hive.mapjoin.smalltable.filesize=25000000;
3、行列过滤
1) 列处理
select 后面选择需要的列,少用select *
2) 行处理
表之间关联的时候,将副表的过滤之后再进行join,这样的话,直接关联的数据就会少很多。如果在关联之后进行where过滤的话,这样的话费时间了。
也就是
table1 a
left join
(select *
from table2 b1
where b1.xxx = xxx
)b
也就是过滤完再关联,比关联之后再过滤效率高。
也就是类似与谓词下推,where的那种情况。
4、采用列式储存
5、创建分区表
查询指定分区,减少查询的数据量,加快查询的速度。
6、优化小文件
1) 小文件是如何产生的
1、动态分区插入数据,产生大量的小文件,从而导致map的数量剧增。
2、reduce数量越多,小文件也就越多(reduce的个数和输出文件是对应的)
3、数据源本身就有大量的小文件。
2) 解决方案
1、执行map之前合并小文件,combinehiveinputformat具有对小文件进行合并的功能。
set hive.input.format=org.apache.hadoop.hive.al.io.CombineHiveInputFormat
也就是设置hive的输入格式,CombineHiveInputFormat(合并hive输入格式化,中文记忆法)
2、merge合并
1)只有map任务,也就是map-only,任务结束的时候合并小文件。
set hive.merge.mapfiles = true ,这个默认就是true。
2)有map任务,也有reduce任务。是在mapreduce任务结束之后,进行合并小文件。
set hive.merge.mapreducefiles = true ,这个默认是false,需要手动设置为true。
3)小文件合并的时候,默认的话是最后合并成一个256M的文件。
set hive.merge.size.per.task = 268435456
4)我们设置一个阀值为16m,当输出的文件的平均大小小于这个阀值得时候,启动一个独立的map-reduce任务进行merge。
set hive.merge.smallfiles.avgsize = 16777216
3、开启JVM重用
7、处理数据倾斜
1) 定义
大量的相同key被partition分配到一个分区,处理的数据量太大。
2) 现象
当我们看任务进度长时间维持在99%(或100%),查看 任务监控 页面 就会发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大,这就是数据倾斜的直接表现。
3) 原因以及解决
1、key分布不均匀,会导致大量的数据到了一个分区中,也就是进入一个reducer中,导致计算量过大,发生数据倾斜。(适用于聚合类操作,求sum,count这种)
解决:开启数据倾斜时候的负载均衡,进行两次MapReduce计算。
set hive.groupby.skewindata = true
--第一次MapReduce的时候, 会给key打上随机数,随机分配到某个reducer中进行计算。
--第二次MapReduce的时候,key中的随机数去掉了,然后key分配到对应的reducer中,进行计算。
2、两张表关联的时候,关联的字段类型不一致。
解决:其中一个类型进行强转成和另一个一致的。
3、采用sum() group by的方式来替换count(distinct)完成计算。
4、表中的null值,会进入同一个reduce中,需要打散 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









