







 本文全面介绍数据库系统知识。涵盖基本概念、发展阶段、数据模型等基础内容,阐述关系数据库的域、笛卡尔积、关系等概念及完整性约束,还介绍关系代数操作、数据库设计阶段、三级模式与二级映像,以及函数依赖、范式、关系分解、锁和权限等知识。
本文全面介绍数据库系统知识。涵盖基本概念、发展阶段、数据模型等基础内容,阐述关系数据库的域、笛卡尔积、关系等概念及完整性约束,还介绍关系代数操作、数据库设计阶段、三级模式与二级映像,以及函数依赖、范式、关系分解、锁和权限等知识。
数据库系统概论
绪论
四个基本概念
数据、数据库、数据库管理系统和数据库系统。层面逐渐变大。
数据库管理系统功能:
- 数据定义
- 数据组织、存储和管理
- 数据操纵
- 数据库的事务管理和运行管理
- 数据库建立和维护
数据库系统(DBS)特点
- 数据共享
- 数据独立(不会因为存储结构或数据逻辑结构变化而影响应用程序)
- 减少冗余
- 减少数据不一致
- 加强保护
三个阶段
人工管理、文件系统、数据库系统。
人工管理
- 数据不保存
- 应用程序管理数据
- 数据不共享
- 数据不具有独立性
文件系统
- 数据可以长期保存
- 由文件系统管理数据(共享性差和冗余度大,数据独立性差)
数据模型 (数据结构+数据操作+完整性约束)
1、概念模型 (实体-联系)
- 信息建模
2.1、逻辑模型
- 层次模型 数据结构(有向树)
优点:
结构清晰
查询效率高
完整性支持好
缺点:
现实中很多联系是非层次性的
若一个节点有多个双亲节点就会笨拙
查询子女节点必须通过双亲节点
结构严密,层次命令趋于程序化
- 网状模型 数据结构:有向图
典型代表是DBTG(CODASYL系统),不是实际的数据库系统,但是理念影响深远。
优点:
更直接的描述现实世界
具有更良好的性能,存取效率较高
缺点:
结构复杂
DDL、DML复杂,且要嵌入高级语言中
访问数据时必须选择适合的存取路径,加重编程负担
- 关系模型(重要)数据结构:二维表
- 面向对象数据模型
- 对象关系数据模型
- 半结构化数据模型
2.2、物理模型
- 对数据最底层的抽象
数据库系统
- 数据结构化
- 共享性高,冗余度低且易扩充
- 数据独立性高(物理独立性和逻辑独立性)
- 数据由数据库管理系统同一管理和控制(安全性、完整性、并发控制、数据库恢复)
从文件系统到数据库系统标志着数据管理技术的飞跃
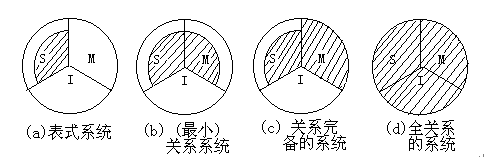
(S:数据结构、I:完整性、M:数据操纵)
表式系统
仅支持关系(即表)数据结构,不支持关系(即集合)操作。
(最小)关系系统
仅支持关系数据结构和三种关系搡作。许多微机关系数据库系统如FoxBASE、FoxPro等就属于这一类。
关系完备的系统
这类系统支持关系数据结构和所有的关系代数操作(功能上与关系代数等价)。
全关系系统
这类系统支持关系模型的所有特征。即不仅是关系上完备的而且支持数据结构中域的概念,支持实体完整性和参照完整性。目前,大多数关系系统已不同程度上接近或达到了这个目标。
数据库设计的六个阶段
我是一个链接
需求分析
数据字典、全系统中数据项、数据结构、数据流、数据储存的描述
概念结构设计
ER图
逻辑结构设计
关系模型、关系模式
物理结构设计
储存安排、储存方法选择、储存路径建立
数据库实施
创建数据库模式、装入数据、数据库试运行
数据库运行和维护
性能监测、转储/恢复、数据库重组和重构
三级模式
外模式:能看见的局部数据的逻辑结构和特征的描述。
模式:全体数据的逻辑结构和特征的描述,用户的公共数据视图。
内模式:储存模式,是数据物理结构和储存方式的描述,是数据在数据库内部的组织方式。
外模式/模式映像:模式改变时(增加新关系、新属性、改变属性数据类型等),因为程序是依靠数据的外模式写的,从而应用程序不用修改,保证了数据和程序逻辑独立性,简称数据的逻辑独立性。
模式/内模式映像:数据库存储结构改变时,由数据库管理员对模式/内模式映像作相应改变。从而应用程序也不用改变。保证了数据和程序的物理独立性,简称数据的物理独立性。
二级映像
- 外模式/模式映像
- 模式/内模式映像
数据库系统的组成
- 硬件平台及数据库
- 软件
- 人员
数据库管理员
系统分析员
数据库设计人员
应用程序员
用户
关系数据库
域
一组具有相同数据类型的值的集合。在表中体现为一列。
笛卡尔积(x)
集合运算,后面关系代数处有例子。
关系(关键)
假设有三个域(三列属性) D1D2D3,则 D1 x D2 x D3的子集叫做在D1D2D3上的关系,表示为R(D1,D2,D3)。
且这个关系的degree(目或者度)为3 。
对于一个属性组,可以分为以下几类:
- 候选码(candidate key):能唯一地标识一个元组,且其子集不能
- 主码(primary key):候选码中选择一个
- 主属性:在候选码中的属性
- 非主属性:不在候选码中的属性
关系的三种类型
- 基本关系(基本表):实际存储数据的逻辑表示
- 查询表:查询结果对应的表
- 视图表:由基本表和视图表导出的表,虚表,不对于实际储存的数据
完整性
正确、有效、相容。
实体完整性
- 主属性不能为空,主码唯一(主码索引,B+树)
参照完整性 - 外键(空值或者等于它表主码)
- 修改时是否破坏参照完整性(是否形成主码相同数据)
处理策略:
(1)拒绝(NO ACTION)执行
(2)级联(CASCADE)操作
(3)设置为空值
用户定义的完整性
- 用户自定义,取值范围等
CREATE TABLE Student
(
Sno numeric(6)
CONSTRAINT C1 CHECK(Sno BETWEEN 90000 AND 99999),
Sname char(20)
CONSTRAINT C2 NOT NULL,
Sage NUMERIC(3)
CONSTRAINT C3 CHECK(Sage<30),
Ssex char(2)
CONSTRAINT C4 CHECK(Ssex IN ('男','女')),
CONSTRAINT StudentKey PRIMARY KEY(Sno)
)
完整性约束命名子句
CONSTRAINT <完整性约束条件名><完整性约束条件>
完整性约束条件包括 NOT NULL,UNIQUE,PRIMARY KEY,FOREIGN KEY,CHECK等。
断言(ASSERTION)
CREATE ASSERTION <断言名><CHECK子句>
任何断言判断不为真值的操作都不被执行。
例限制数据库最多60名学生选修。
Create assertion ASSE_SC_DB_NUM
CHECK(
60>=(
select count(*) from Couse,SC
where SC.CNO=COURSE.CNO and COURSE.CNAME='数据库'
)
)
触发器
CREATE TRIGGER <触发器名>
{BEFORE|AFTER} <触发事件> ON <表名> /*触发事件和激活时间*/
REFERENCING NEW|OLD ROW AS <变量> /*引用变量*/
FOR EACH{ROW|STATEMENT} /*动作体执行频率*/
[WHEN <触发条件>] <触发动作体> /*触发条件为真才触发动作体*/
触发事件
- INSERT
- DELETE
- UPDATE
关系代数(Relational Aigebra):
Union
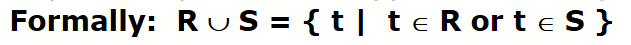
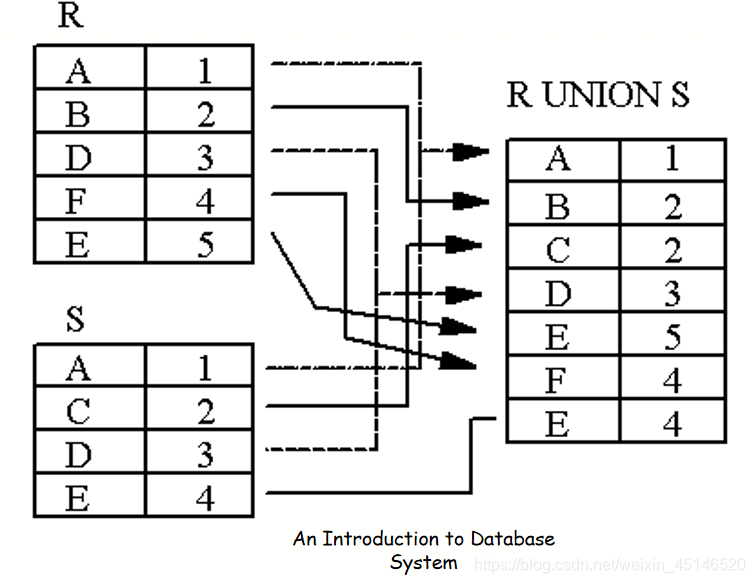
Duplicate tuples will not appear in the output as (D-3) both in R and S.
R and S must satisfy the following rules:
- Rule 1: have the same degree
- Rule 2:domain of the ith attribute both of R and S must be same
difference
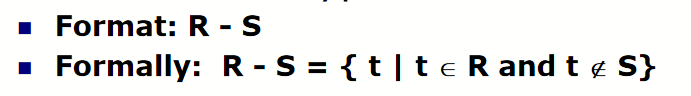
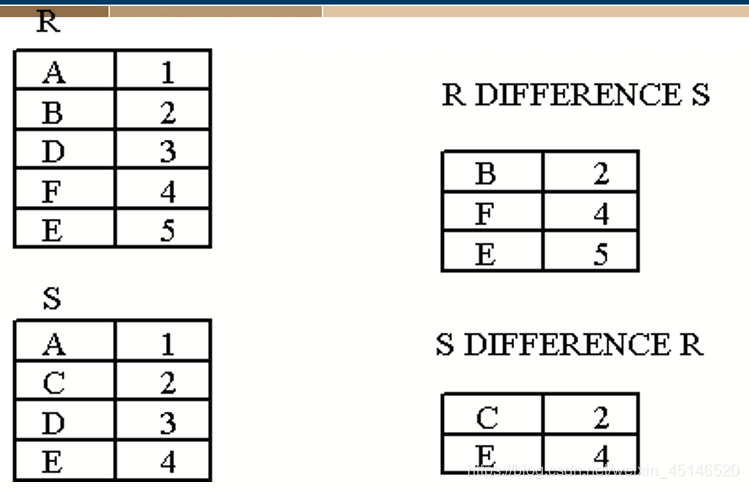
- semantics: R-S is the relation containing all tuples in R that do not appear in S.
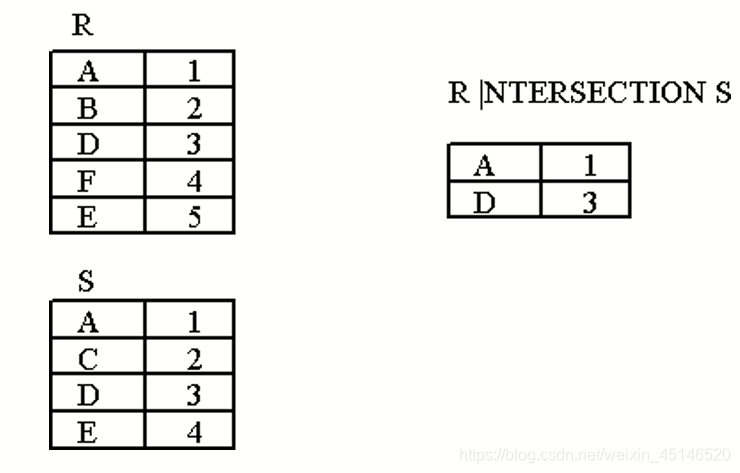
insersection
R intersection S returns all tuples that appears both in R and S
cartesian product (笛卡尔积)(cross product)
- Assuming R has n attributes and S has m attributes respectively,the cartesian product can be written as:
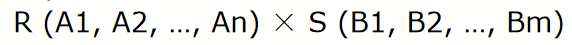
result of the above set operation is:
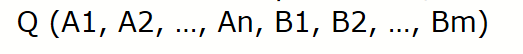
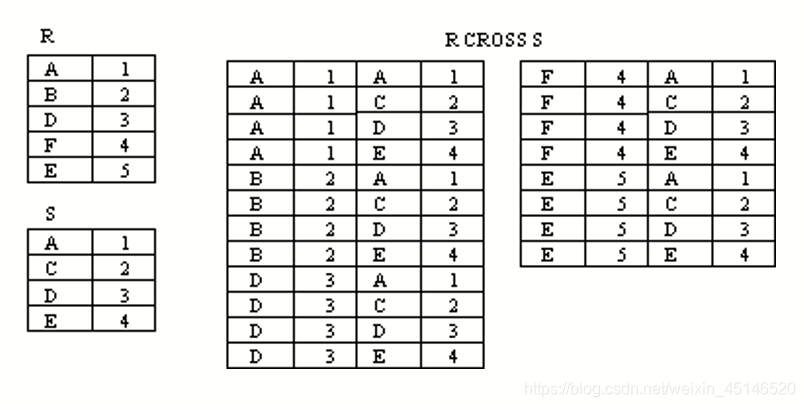
Duplicate tuples contain in ouput !!!
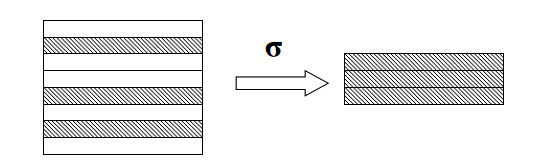
select operation
- This operation retrieves a subset of tuples in a relation that satisfy a select condition.
such as : - AGE=19 is a condition and student is a relation.
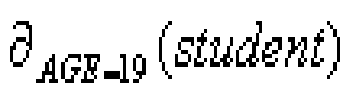
- And two and more condition :

- The selection operation is commutative. The below are equivalent.

projection operation
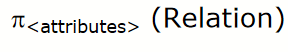
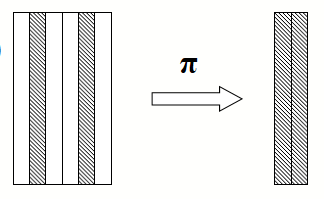
- Now we can combine projection and selection.
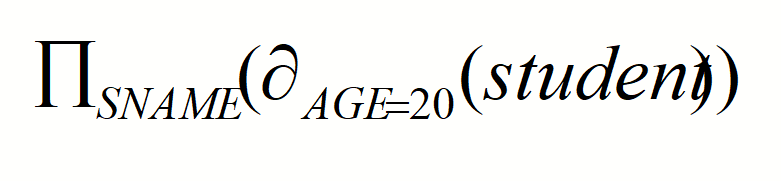
RA’s join
链接一
内连接:只保留有满足的值
外连接:包括悬挂元组
Join
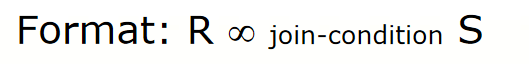
- Return all tuples in RxS that satisfy the join condition.
- Derivation
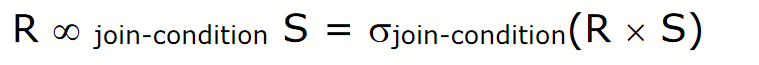
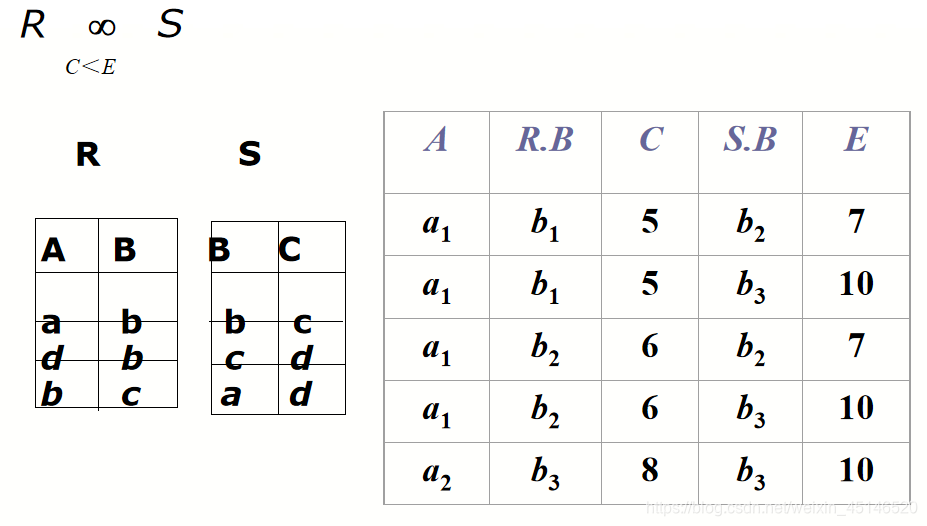
Theta Join(θ Join)
example:
equi join(=)
- A join is called an equijoin if only equality operator is used in all join conditions.
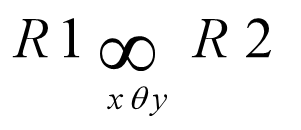
- < join condition> must always have = operation
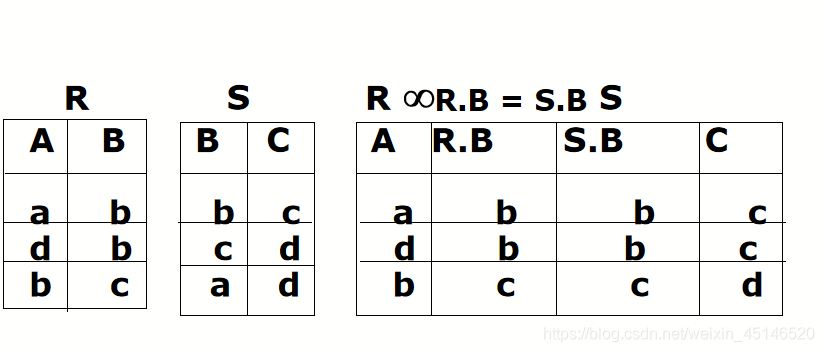
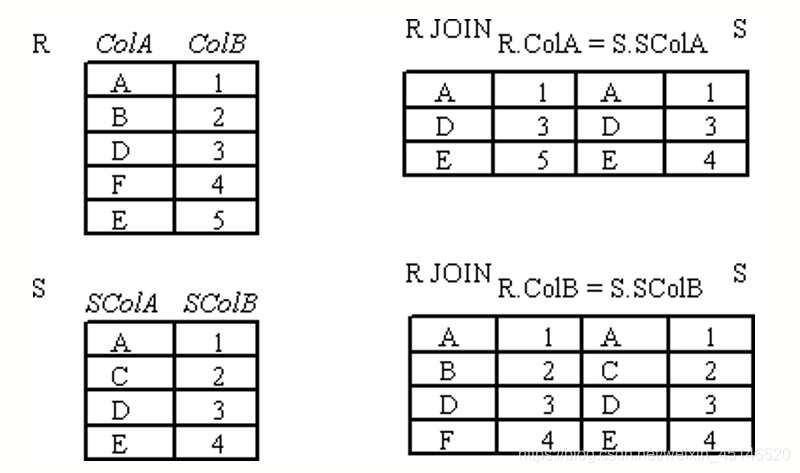
natural join(*)
- if an attribute is common both in two relation,we can remove one in the join
- natural join omit the condition
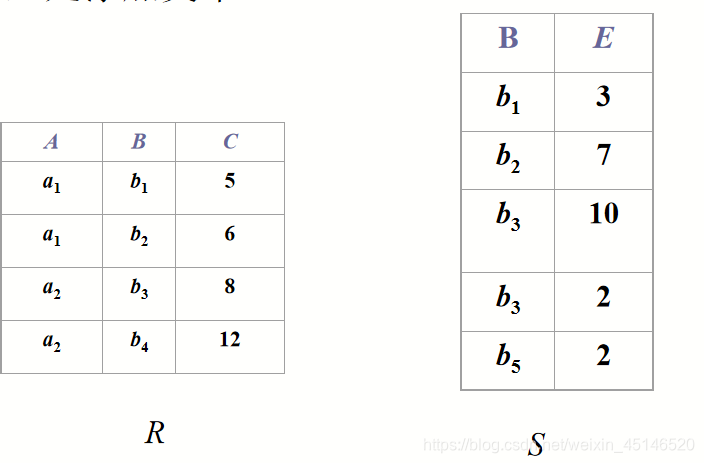
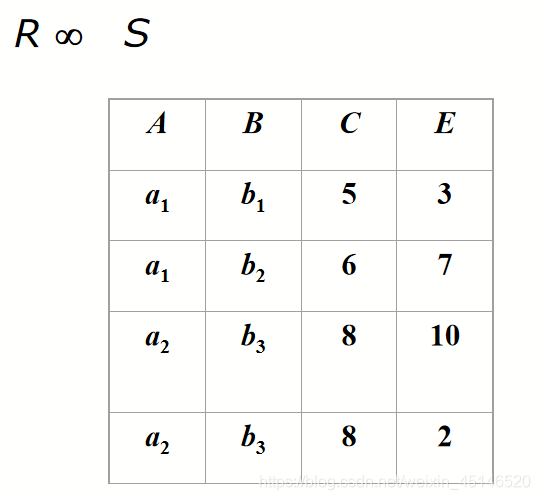
example (?)

Outer Joins (Special Case of EquiJoin)
How to keep dangling tuples in the result of a join?
left outer join
is similar to a natural join but keep all dangling tuples of R1.
right outer join
is similar to a natural join but keep all dangling tuples of R2.
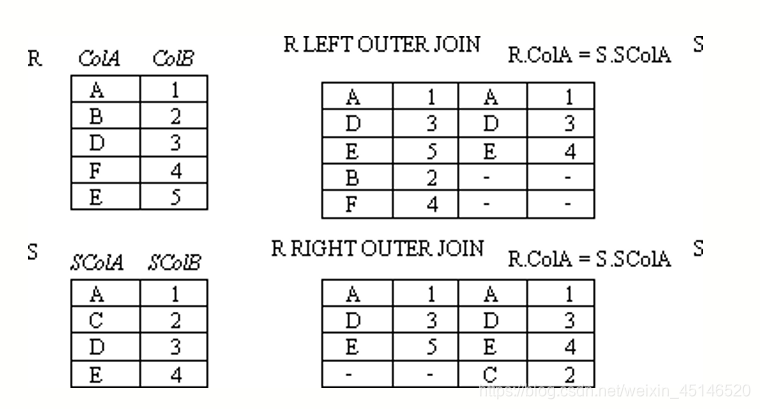
full outer join
is similar to a natural join but keep all dangling tuples of both R1 and R2.
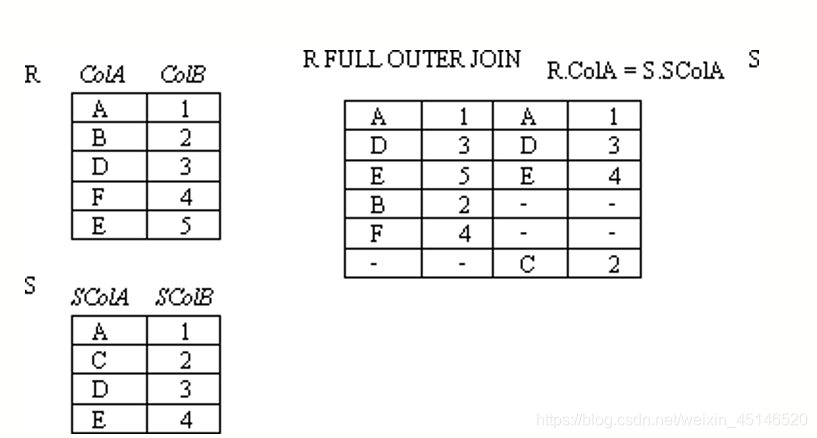
The advantages of outer join is to take the union of tuples from two relations that are not union compatible.
Division
Precondition: in A/B, the attributes in B must be included in the schema for A. Also, the result has attributes A-B
Another example is: Suppose we want to find all the students who have selected all courses (See Figure 3.19 Course Table ) provided by the school.
We can think of it as three steps:
1.We can obtain the NO. of all courses provided by the school by:
2.We can also find all SSN, cno pairs for which the student has selected courses by:
3.Now we need to find all students who selected all the courses. The divide operation provides exactly those students:

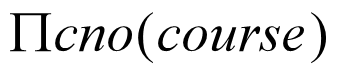
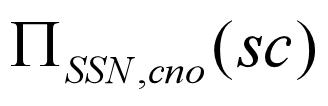
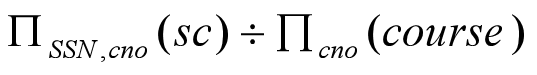
View
视图与基本表不同,是一个虚表。数据库只存放视图的定义,而不存放对应的数据,数据仍存放在基本表中。
Create VIEW 视图名 [列名,列名]
AS <子查询>
[WITH CHECK OPTION]
an interesting example
create table table1 (bm float )
insert into table1 values(5000)
create view TestViewCheckOption AS
select * from Table1 where Bm < 5003
with check option
update TestViewCheckOption set Bm = 5005
go
- update error because 5005 can not appear in view with check option.
And a view can be changed by alter statement.
ALTER VIEW view_name [(column_list)] [WITH ENCRYPTION]
AS select_statement
[WITH CHECK OPTION]
第一点:
使用视图,可以定制用户数据,聚焦特定的数据。
解释:
在实际过程中,公司有不同角色的工作人员,我们以销售公司为例的话,
采购人员,可以需要一些与其有关的数据,而与他无关的数据,对他没
有任何意义,我们可以根据这一实际情况,专门为采购人员创建一个视
图,以后他在查询数据时,只需select * from view_caigou 就可以啦。
第二点:使用视图,可以简化数据操作。
解释:我们在使用查询时,在很多时候我们要使用聚合函数,同时还要
显示其它字段的信息,可能还会需要关联到其它表,这时写的语句可能
会很长,如果这个动作频繁发生的话,我们可以创建视图,这以后,我
们只需要select * from view1就可以啦~,是不是很方便呀~
第三点:使用视图,基表中的数据就有了一定的安全性
因为视图是虚拟的,物理上是不存在的,只是存储了数据的集合,我们可以
将基表中重要的字段信息,可以不通过视图给用户,视图是动态的数据的集
合,数据是随着基表的更新而更新。同时,用户对视图,不可以随意的更改
和删除,可以保证数据的安全性。
第四点:可以合并分离的数据,创建分区视图
随着社会的发展,公司的业务量的不断的扩大,一个大公司,下属都设有很
多的分公司,为了管理方便,我们需要统一表的结构,定期查看各公司业务
情况,而分别看各个公司的数据很不方便,没有很好的可比性,如果将这些
数据合并为一个表格里,就方便多啦,这时我们就可以使用union关键字,
将各分公司的数据合并为一个视图。
Specifying constraints
not null constraint
For item must contain a not null value
unique constraint
can not have same value.
Note that you can have many UNIQUE constraints per table, but only one PRIMARY KEY constraint per table.
primary key constraint
- A primary key must contain unique values and cannot contain NULL values.
- must have and only one

Foreign key constraint
- two tables, one is referencing table, another is referenced table
- columns in referencing table must primary key or other candicate key in referenced table

check constraint
- limit the value range that can be placed in a column

default constraint
- insert a default value into column if no other value is specified

defalut can also use system function like getdate()

alter table add constraint
- Add constraints to an existing table by using the ALTER TABLE statement.

- drop it

index
- A database index enables the database application to find data quickly without having to scan the whole table.

Create [UNIQUE] [CLUSTER] INDEX 索引名
ON 表名(列名 ASC|DESC)
索引建立后就由系统维护,不需要用户干预。建立索引是为了减少查询操作的时间,但是如果增删改频繁,维护索引的耗费就多了,降低了效率。
数据库索引类型:
顺序文件上的索引(升降序)
B+树索引(B+树叶结点为属性值和相应的元组指针,动态平衡)
散列索引(将索引属性安装散列函数值映射到相应桶中,桶中存放属性值和相应的元组指针)
位图索引 (用位向量记录索引属性中可能出现的值,每个位向量对应一个可能值)
select statement

- The SELECT clause lists what columns to return.
- The FROM clause which indicates the table(s) from which data is to be retrieved.
- The WHERE clause specifies which rows to retrieve.
- The GROUP BY clause groups rows sharing a property so that an aggregate function can be applied to each group. The WHERE clause is applied before the GROUP BY clause.
- The HAVING clause selects among the groups defined by the GROUP BY clause. Because it acts on the results of the GROUP BY clause, aggregation functions can be used in the HAVING clause predicate.
- The ORDER BY clause specifies an order in which to return the rows. Without an ORDER BY clause, the order of rows returned by an SQL query is undefined.
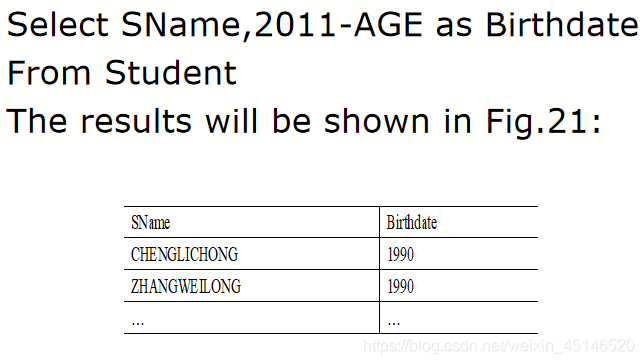
alias
- shown with new name or new column
distinct
- show only distinct rows in column


between or not between (range search
- get res of column in a range

in or not in (set membership search)
- specify multiple values in where clause

like or not like (pattern match search)
use for inexact condition search
- The % wildcard matches zero or more characters of any type.
- The _ wildcard matches exactly one character of any type.


To match strings that there are at least one character between ‘a’ and ‘c’ .
SELECT SNAME
FROM STUDENT
WHERE SNAME LIKE ‘a_%c’;
escape character
If the search strings can include the wildcards(%,_) itself, we can use an escape character to represent the wildcards.
For example, to match the string ‘20%’, we can use :
Like ‘20#%’ ESCAPE ‘#’
is NULL or is not NULL

ordered by
- sort

默认升序 ASC
降序 DESC
aggregate function (聚合函数)
- COUNT
(1) count number of rows of tables
(2) count distinct values for a given column


distinct is not an argument in the function,it use before function is
applied.
- AVG

- MAX
- MIN
- SUM
group by clouse
- group the result-set by one or more columns with function

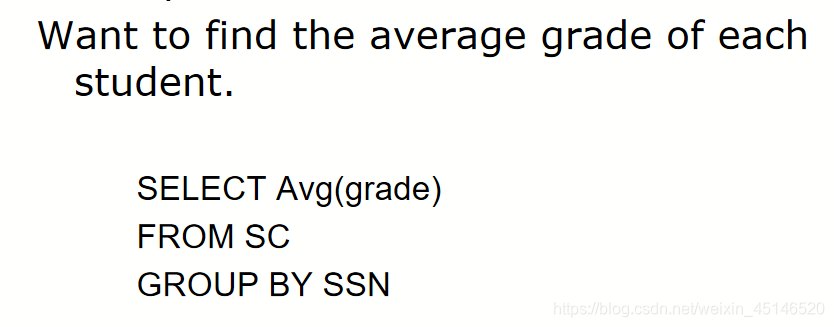
需要注意的是,group by 语句不能出现在子查询select中。
having clouse
- The HAVING clause was added to SQL because the WHERE keyword could not be used with aggregate functions.



Multiple table (sql多表)
SQL allows us to query multiple tables in one SELECT-FROM-WHERE statement.
- The SELECT and WHERE can refer to the attributes of any of the tables once we list each table in the FROM clause.
- ANSI standard SQL specifies four types of JOINs: INNER, OUTER, LEFT, and RIGHT.
- a table (base table, view, or joined table) can JOIN to itself in a self-join.
table student
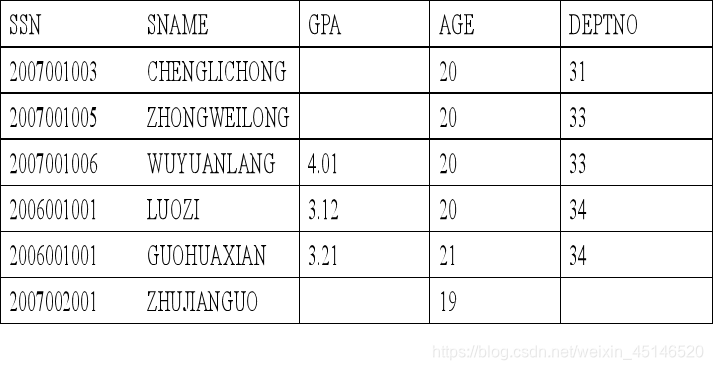
table department
inner join

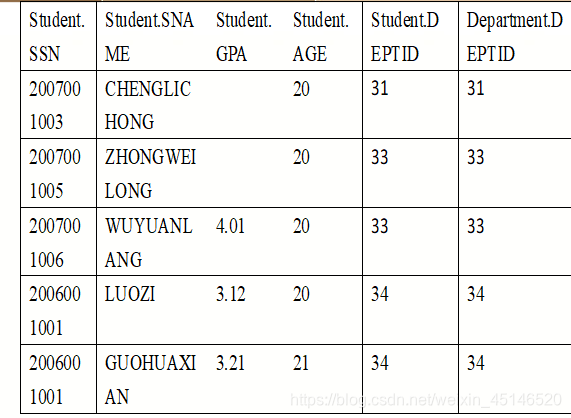
outer join
- Rows are returned even when there are no matches through the JOIN critieria.
Left outer join

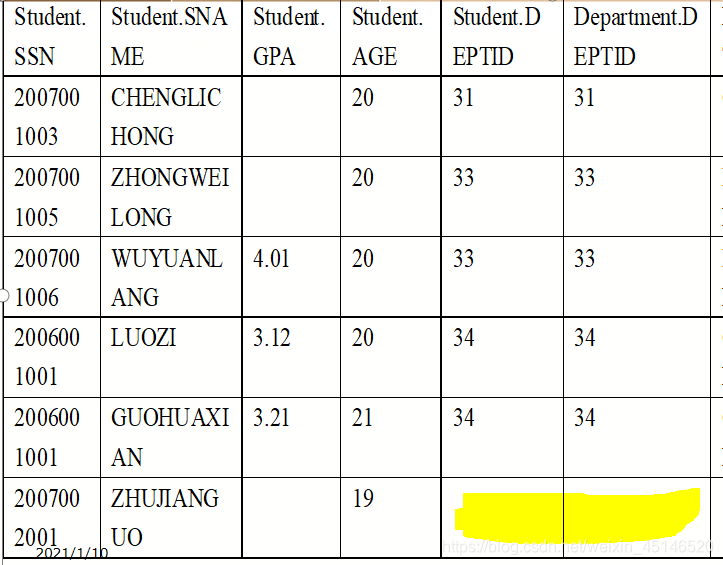
Right outer join
- The RIGHT OUTER JOIN returns all rows from the second table.

Although 35 have no students we should list it too.
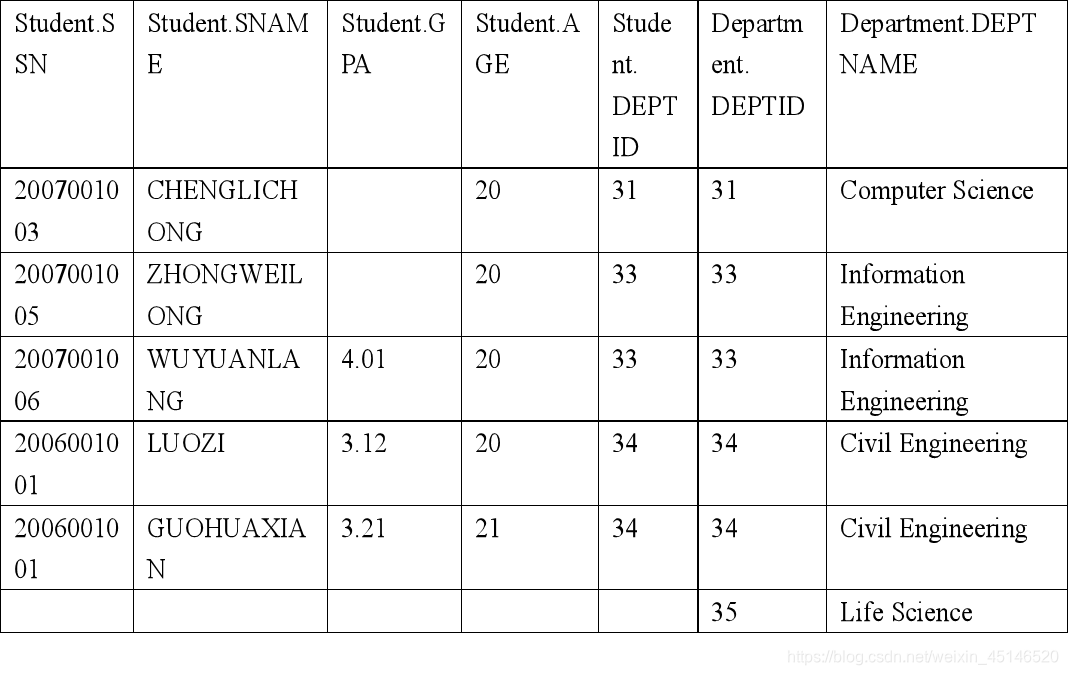
Full outer join
- A full outer join combines the effect of applying both left and right outer joins.

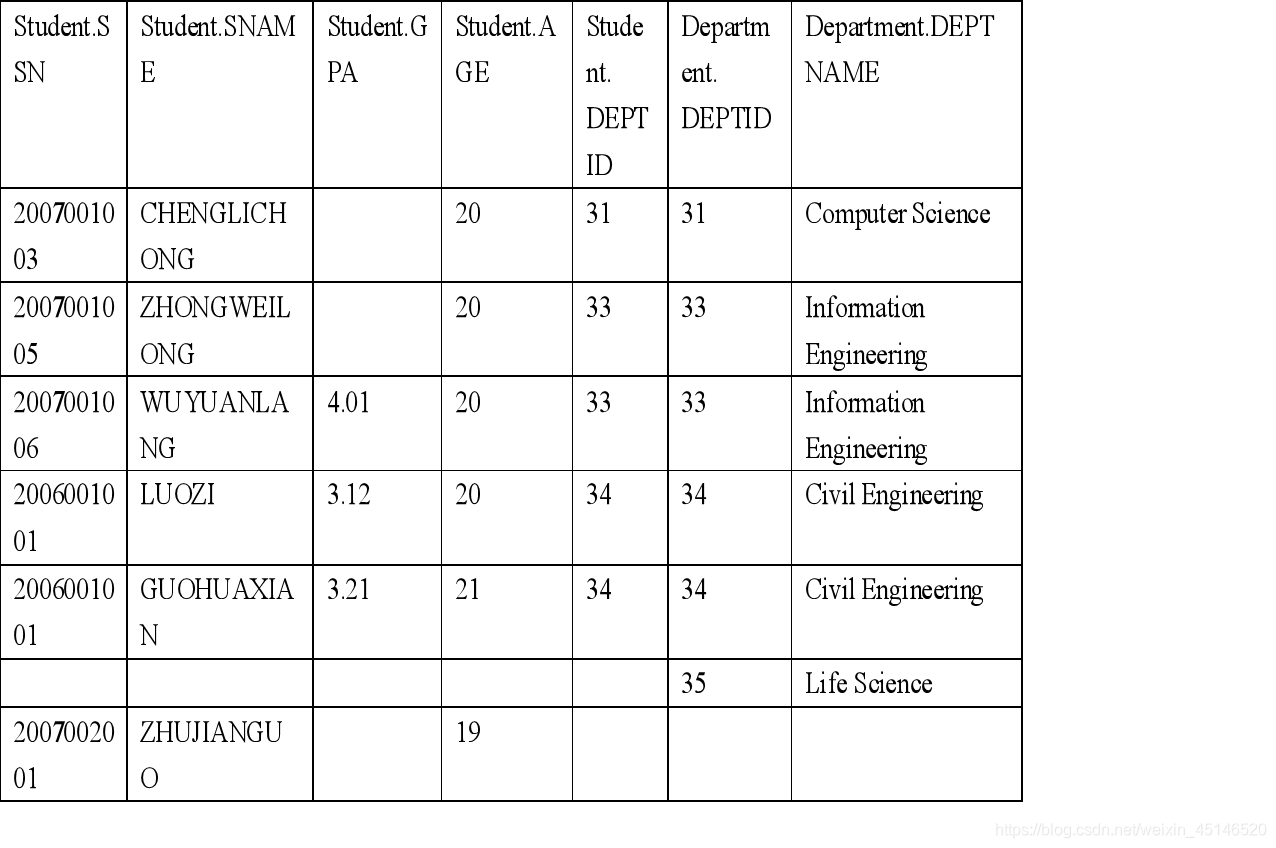
Alias
- Table names can be abbreviated in order to simplify what is typed in with the query.

date format
date ------- to_char
select the name,job and date of hire of the employees in department 20(format the hiredate column using a picture MM/DD/YY).
Select ename “employee”,job, to_char(hiredate,’MM/DD/YY’) “HireDate”
From emp
Where deptno=20
Use a picture to format hiredate as DAY(day of the week),MONTH(name of the month),DD(day of the month) and YYYY(year).
Select to_char(hiredate,’DAY,MONTH,DD,YYYY’ ) “HireDate”
From EMP
Which employees were hired in March?
Select ename “Employee”,hiredate
From emp
Where to_char(hiredate,’MON’)=‘3月’
Show the weekday of the first day of the month in which each employee was hired.
Select ename “employee”,hiredate,to_char(trunc(hiredate,’month’),’day’)
From emp
trunc
1 trunc用于对值的截断。用法有两种:sysdate=2010-10-20
- trunc(NUMBER)截断数字:trunc(n1,n2),n2表示要截断到哪一位。也可为负数,如:
trunc(19.85)——>19; trunc(19.85,1)——>19.8; - trunc(DATE)截断日期
截取今天:trunc(sysdate,‘dd’)或trunc(sysdate)——》2012-03-24
截取本周第一天:trunc(sysdate,‘d’)——》2012-3-18
截取本月第一天:trunc(sysdate,‘mm’)——》2012-3-1
截取本年第一天:trunc(sysdate,‘y’)——》2012-1-1
last_day and next_day
last_day求一个日期所在月的最后一天
next_day(日期,‘sun|mon|…|fri|sat’)从日期后的下一天开始找,如果与相应的星期满足,则返回满足条件的日期。
求一个月的最后一天
SQL> select last_day(sysdate) from dual;
下一个星期一的日期
SQL> select next_day(sysdate,‘mon’) from dual;
下个月的第一个星期五
SQL> select next_day(last_day(sysdate),‘fri’) from dual
set operation
union

- union removes duplicate rows.
- union all keeps duplicate rows.
intersect

Minus

sub queries

子查询分为相关子查询和不相关子查询,根据子查询是否依赖父查询可得知。
- 子查询返回单值时可以使用比较运算符
- 返回多值时要用ANY(SOME)、ALL谓词的子查询
comparison-operator
ALL – the comparison must be true for all returned values.
ANY – The comparison need only be true for one returned value.
IN may be used in place of = ANY.
NOT IN may be used in place of != ALL.



exists and not exists


insert

update


delete

scalar function(标量函数)
Trivial FD (平凡函数依赖):
such as {stu,num,id}
{stu,num} -> { stu } is a Trivial FD
{stu,num} -> { id } is not a Trivial FD
数据库函数依赖和范式:
函数依赖及范式
1NF、2NF、3NF、BCNF
范式
范式练习题
一个关系模式应该是一个五元组 R(U,D,DOM,F) 。
- R 是符号化的元组语义。也就是关系。
- U为一组属性。
- D为U中属性来自的域,也就是列的集合。
- DOM为属性到域的映射,也就是属性对应的列。
- F为属性组U上的一组数据依赖。
由于D,DOM和设计模式关系不大,因为在这里不需要知道确切属性名,只需要字母代替属性名就行了。
所以可以将其看成一个三元组: R=<U,F>
第一范式 :属性不可分,也就是不能一个名字列下面还搞姓和名分开。
第二范式:元组中不能有不完全函数依赖于主属性的非主属性。
第三范式:不能有函数传递依赖的非主属性。
BCNF:不能有函数传递依赖的主属性。
4NF:限制关系模式的属性之间不能有非平凡且非函数依赖的多值依赖。
每一个高级范式都有低级范式的规矩。
关系满足的范式越高,查询的消耗越高。
模式问题:
数据冗余
重复出现
更新异常
由于数据冗余,更新需要的代价大
插入异常
应该插入的数据无法插入
删除异常
不该删除的数据被删除
attribute clouse (computing F+)

super key and primary key
- AB is a superkey of R since (AB)+ = ABCDE.
- Since (A)+ = A, (B)+ = BD, neither A nor B is a superkey.
- Hence ,AB is a candidate key.
one
for each pair AiAj, i != j
if Ai or Aj is a candidate key
then AiAj is not a candidate key;
else compute (Ai Aj)+;
if (AiAj)+ = A1 A2 ... An
then (Ai Aj) is a candidate key;
two
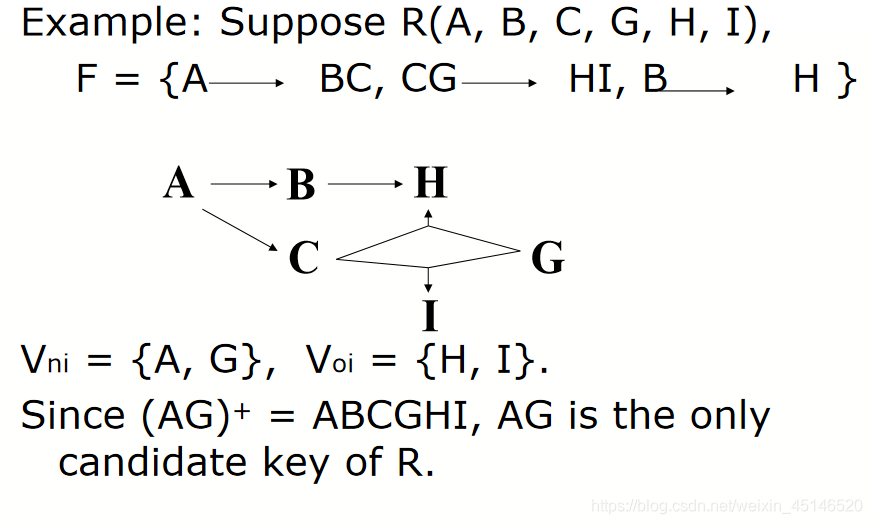
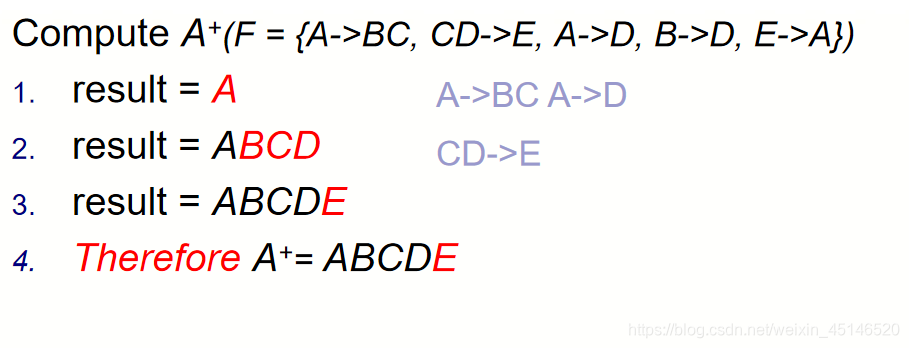
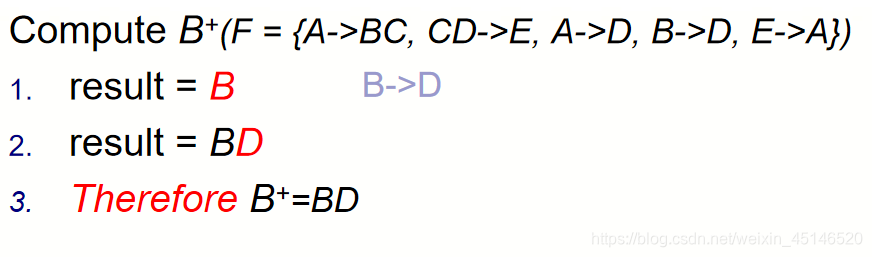
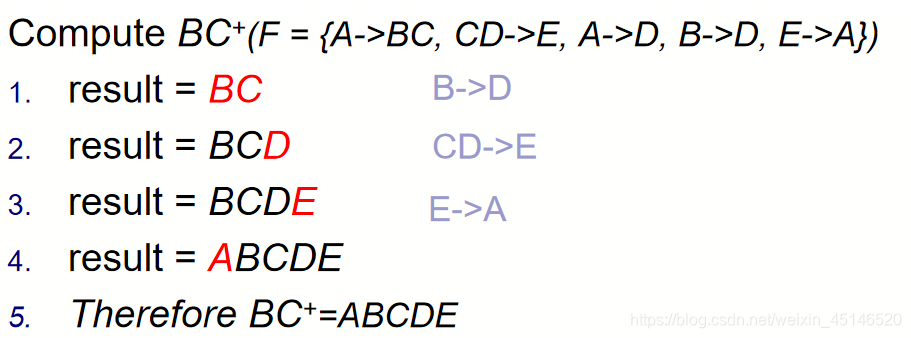
Relation schema: R = (A, B, C, D, E)
F = {A->BC, CD->E, A->D, B->D, E->A}
(1)Find A+, B+, BC+
(2)Find Candidate keys of R
hence candicate keys are ?
A?B?D?E? BC? CD?
Candidate keys : A 、E、 BC、 CD

Relation Decomposition(关系分解)
if R is a Relation,and a set {R1,R2,R3,…} have R=(R1 union R2 union R3…),that {R1,R2,R3…} is decomposition of R。
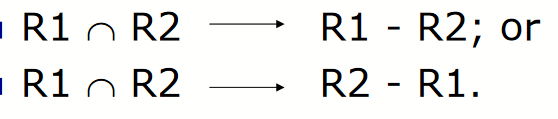
lossless join decomposition(无损分解)
Theorem: Let R be a relation schema and F be a set of FDs in R. Then a decomposition of R, {R1, R2}, is a lossless-join decomposition if and only if
chase判断无损连接性算法
已知R<U,F>,U={A,B,C,D,E},
F={A→C,B→C,C→D,DE→C,CE→A},R的一个分解为R1(AD),R2(AB),R3(BE),R4(CDE),R5(AE),判断这个分解是否具有无损连接性。
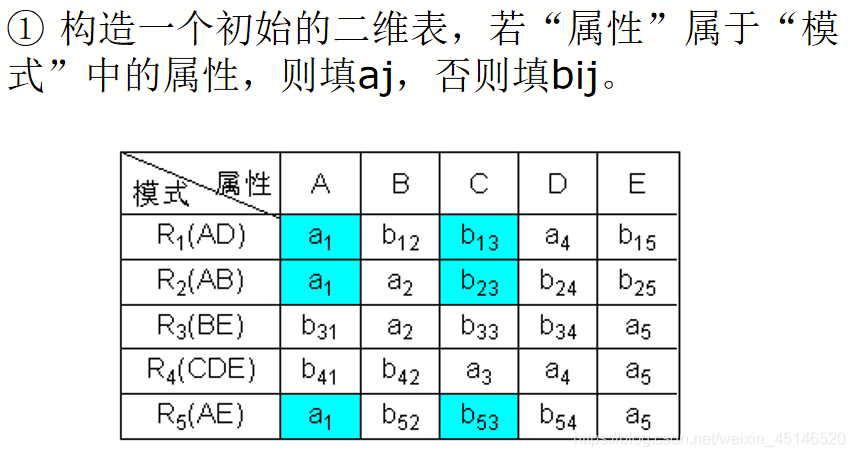
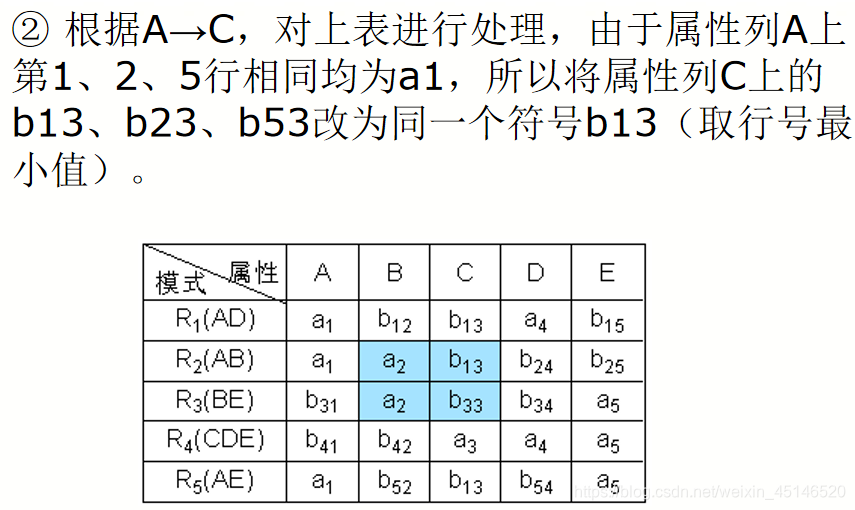
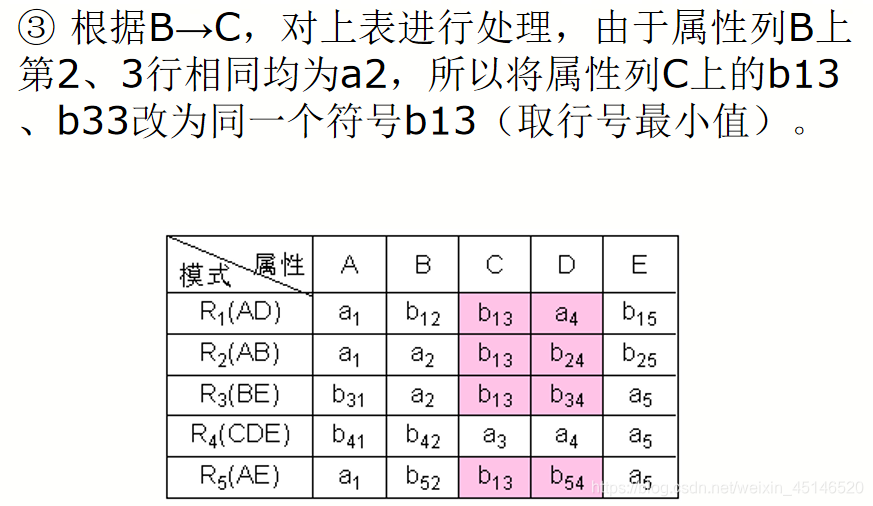
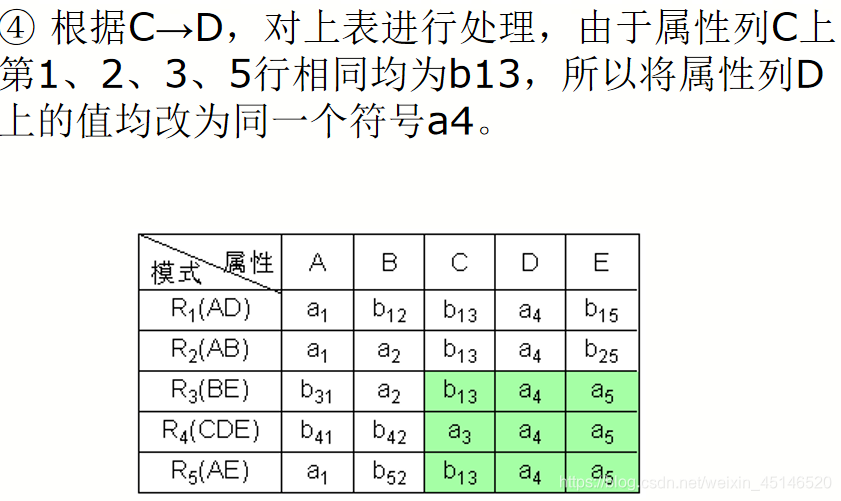
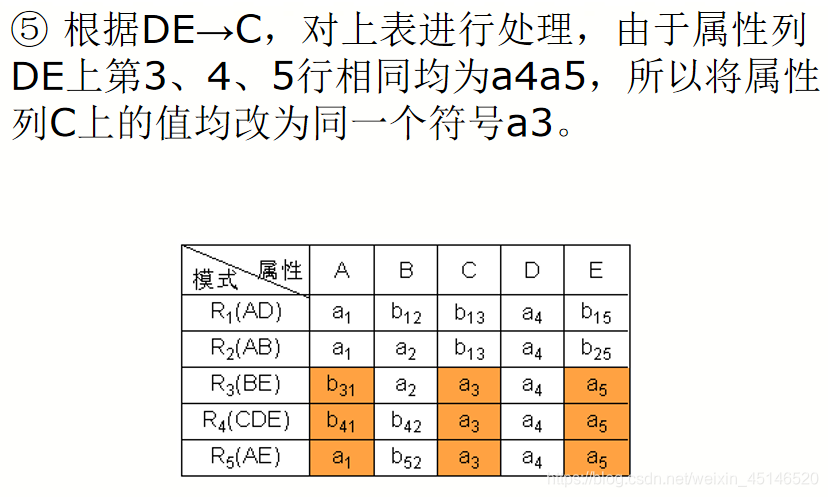
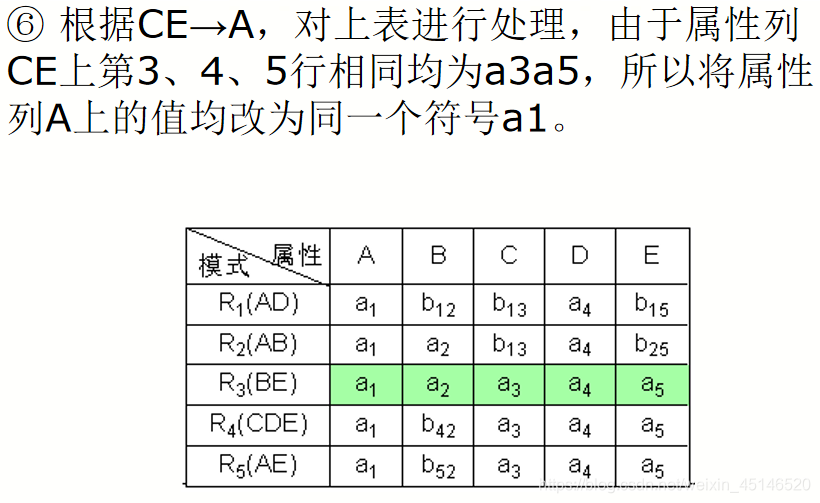
Depentdency-Preserving Decomposition(依赖保存分解)
超键,候选键,主键,外键:链接地址
一对一、一对多、多对多等关系: 链接地址
Model
ER图合并时会有冲突:
(1)属性冲突
- 属性域冲突(属性类型)
- 属性取指单位冲突(单位)
(2)命名冲突
- 同名异义
- 异名同义
(3)结构冲突
- 同一实体不同应用中有不同抽象(例一个ER图中是实体另一个ER图中是属性)
- 同一实体在不同子系统的E-R图中包含的属性个数和属性排列次序不完全相同
- 实体间的联系在不同的ER图中是不同的类型
Two common techniques of logical design
- The Entity-Relationship approach
- The Normalization approach
phases of Database Design
- requirement collection and analysis
- conceptual design
- logical design
- physical design
condinality constraint
- one in E may envolve between min_card and max_card relationships in R.

total (mandatory) participation: min_card >=1
partial(optional) participation:min_card=0
锁
锁一
锁二
(1)无损分解、依赖保留分解
(2)ER图
(3)锁
排他锁:写锁(别人不可读不可改)
共享锁:读锁(别人可读不可改)
相容矩阵(important)
封锁协议
一级封锁协议:X锁 (防止丢失修改,会有可重复读和脏数据)
二级封锁协议:S锁 (防止读脏数据,但是由于每次一读完就会释放锁,所以不能保证可重复读)
三级封锁协议:一级封锁协议加上事务在读取数据时必须先加上s锁,直到事务结束才释放。(可重复读)
死锁(资源阻塞问题)
(1)事务T1请求A的写锁
(2)事务T2请求B的写锁
(3)事务T1又请求B的写锁
(4)事务T2又请求A的写锁
活锁(调度问题)
事务T1封锁了数据R
事务T2又请求封锁R,于是T2等待。
T3也请求封锁R,当T1释放了R上的封锁之后系统首先批准了T3的请求,T2仍然等待。
T4又请求封锁R,当T3释放了R上的封锁之后系统又批准了T4的请求
T2有可能永远等待,这就是活锁的情形
不高效的解决方法
(1)一次封锁法
(2)顺序封锁法
操作系统中常用的策略并不适用于数据库系统。
诊断
(1)超时
判断等待事件,容易误判或等待事件过长。
(2)诊断图
画等待情况。若T1等待T2,则T1,T2之间划一条有向边,从T1指向T2。若有环则死锁。
释放花费最小的事务所有的锁
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oPn9tRpU-1610770328926)(/assets/bg.jpg)]
并发调度的可串行性
(1)串行调度都是正确的
(2)结果跟串行调度一样的调度也是正确的

上面是可串行的调度。
冲突可串行调度。也就是调度后能变成可串行的。
封锁粒度(逻辑单元、物理单元)
- 粒度大,并行少,消耗小
- 粒度小,并行大,消耗大
需要处理多个关系的大量元组的用户事务:以数据库为封锁单位
需要处理大量元组的用户事务:以关系为封锁单元
只处理少量元组的用户事务:以元组为封锁单位
概念:
(1)多粒度树

(2)显式封锁和隐式封锁
- 显式封锁:直接加到数据对象上的锁
- 隐式封锁:该对象没有独立加锁,而是其上级节点加锁了导致它也加锁了。
所以系统检查封锁冲突时,除了检查显式封锁,还要检查隐式封锁。
对某个对象加锁时要检查:
该数据对象
- 有无显式封锁与之冲突
所有上级结点
- 检查本事务的显式封锁是否与该数据对象上的隐式封锁冲突:(由上级结点已加的封锁造成的)
所有下级结点
- 看上面的显式封锁是否与本事务的隐式封锁(将加到下级结点的封锁)冲突.
意向锁
目的:提高检查效率。如果当前节点有意向锁,说明下层节点正在被加锁。
所以对任意节点加锁前,要对它所在的数据库和关系加意向锁。
有三类:
-
意向共享锁(IS)
事务T1要对R1中某个元组加S锁,则要首先对关系R1和数据库加IS锁 -
意向排它锁(IX)
事务T1要对R1中某个元组加X锁,则要首先对关系R1和数据库加IX锁 -
共享意向排它锁(SIX)
对某个表加SIX锁,则表示该事务要读整个表(所以要对该表加S锁),同时会更新个别元组(所以要对该表加IX锁)
相容矩阵

两段锁:获取时不释放,释放时不获取。
权限
Grant 和 Revoke
向用户授予和收回对数据的操作权限。
Grant <权限>[,<权限>]…
ON <对象类型><对象名>[,<对象类型><对象名>]…
TO <用户>[,<用户>]…
[WITH GRANT OPTION];
Revoke <权限>[,<权限>]…
ON <对象类型><对象名>[,<对象类型><对象名>]…
FROM TO <用户>[,<用户>]… [CASCADE|RESTRICT];
可以结合VIEW和GRANT对不同用户划分不同视图。
杂记
- 事务的特性包括:一致性、原子性、隔离性和持久性。
原子性:诸操作要么都做,要么都不做。- 一般导致数据库中数据不一致的根本原因有三种情况。第一种是数据冗余造成的,第二种是并发控制不当造成的,第三种是由于某种原因(比如软硬件故障或者操作错误)导致数据丢失或数据损坏。 第一种情况:数据冗余 假如数据库中两个表都放了用户的地址,在用户的地址发生改变时,如果只更新了一个表的数据,那么两个表就有了不一致的数据。 第二种情况:并发控制不当 假如在飞机票订票系统中,如果两个购票点同时查询某张机票的订购情况,而且分别为订购了这张机票,如果并发控制不当,就会造成同一张机票卖给两个用户的情况。由于系统没有进行并发控制或者并发控制不当,造成数据不一致。 第三中情况:故障和错误 如果软硬件出现故障或者操作错误导致数据丢失或数据损坏,引起数据不一致。因此我们需要提供数据库维护和数据库数据恢复的一些措施。 要根据各种 数据库维护 手段(如转存、日志等)和 数据恢复 措施将 数据库恢复 到某个正确的、完整的、一致性的状态下。
- 应用数据库的主要目的是:共享数据问题。
- 数据库镜像技术解决介质故障。
- 数据库恢复的基础是利用转储的冗余数据,这些冗余数据是指日志文件、数据库后备副本。
- 事务是DBMS的基本单位,是用户定义的一个数据库操作序列。

















 230
230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









