







Hadoop1.x
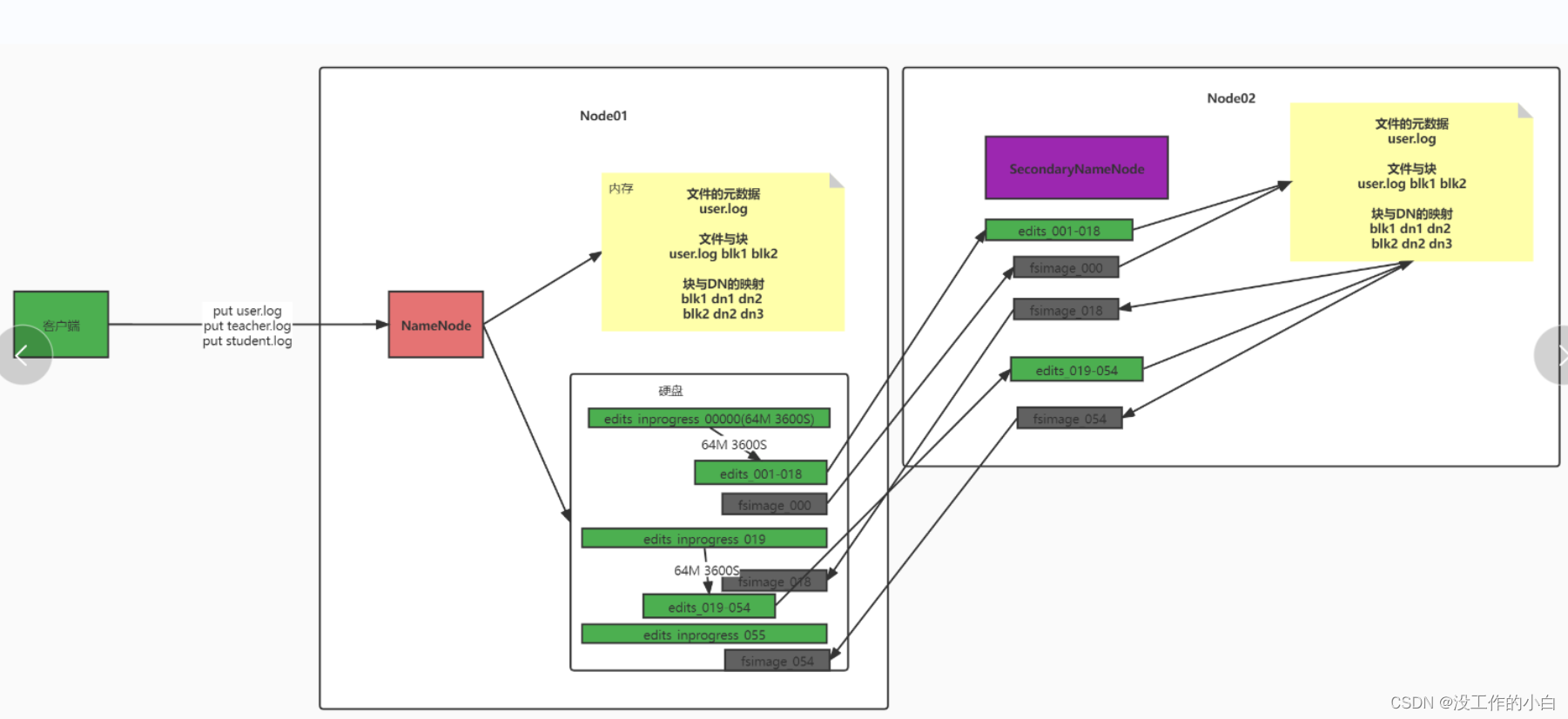
HDFS工作流程
1:在客户端请求HDFS的时候,会先访问NN服务器
2:NN服务器就告诉客户端,应该去访问那些对应的DN服务器
3:在操作完毕之后,NN服务器会记录本次操作日志到edits日志文件中
4:如果等到阈值【360秒或者当前edits日志文件到了64M】,SecondaryNameNode服务器就会合并Edits和fsimage信息
5:SecondaryNameNode服务器会将最新的Edits文件信息合并到fsimage文件中,然后原来的Edits文件打上标记,成为历史日志文件
【合并后的fsimage文件是最新的NN服务器内存中信息,Edits历史日志全部保留,fsimage只保留两个版本】
hadoop安全模式
安全模式作用
安全模式是HDFS的一种工作状态,在安全模式下,只向客户端提供文件的只读视图,不接受对命名空间的修改,NN服务器也不会进行数据快的复制或者删除
安全模式相关命令
hadoop dfsadmin -safemode leave 强制NameNode退出安全模式
hadoop dfsadmin -safemode enter 进入安全模式
hadoop dfsadmin -safemode get 查看安全模式状态
hadoop dfsadmin -safemode wait 等待一直到安全模式结束
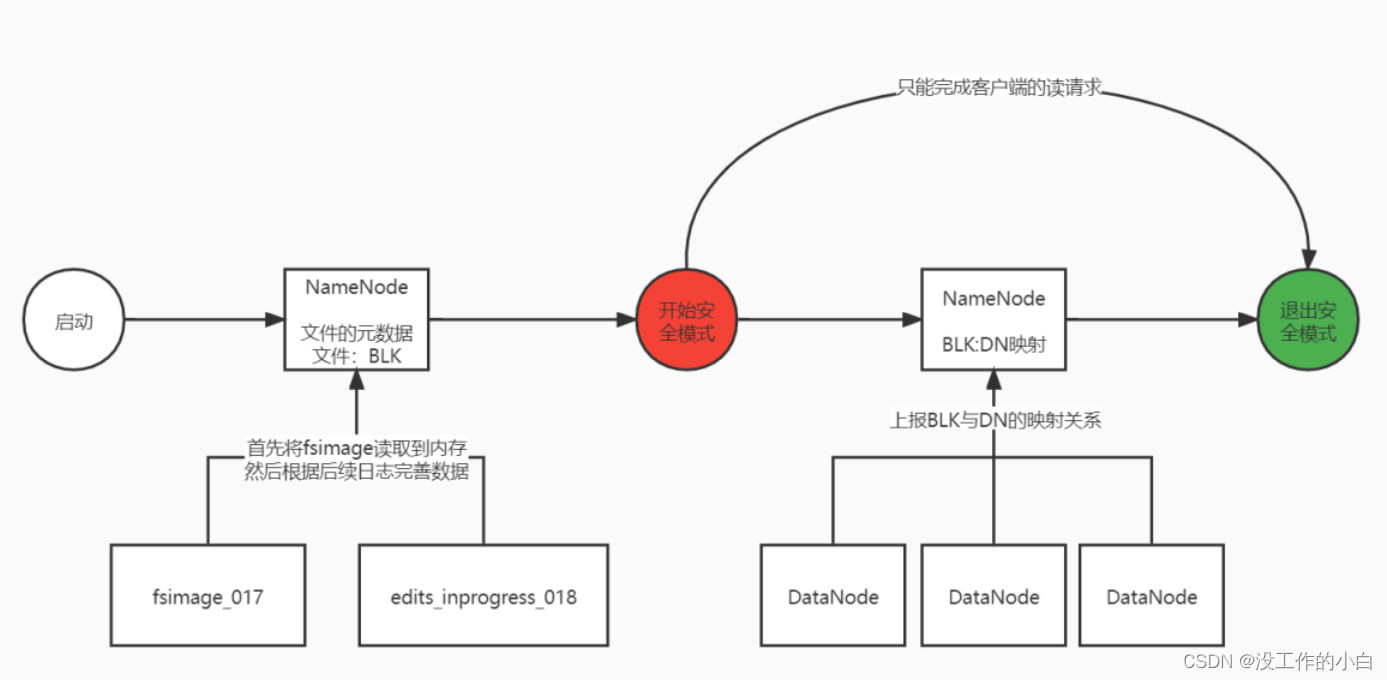
HDFS启动的工作流程中的安全模式工作内容
1:在HDFS启动后,NN服务器将fsimage文件信息和最后一个版本的edits信息读取到NN服务器内存中
2:启动了安全模式,在安全模式时间,客户端提供文件只读,不能进行其他操作
3:安全模式中,每个DN服务器会上报各自的数据块列表信息给NN服务器
4:正常情况下,会在启动后30退出安全模式,如果发现数据节点过少,就会复制数据到其他节点
【数据块不够最少副本数,在拷贝期间也属于安全模式】
HDFS权限介绍
对于HDFS中是有权限控制的,但是对于HDFS而言,这里的权限根据用户来判断是否有权限操作文件,但是并不是很严格
在HDFS中,你告诉他你是那个用户,你就拥有那个用户的权限
所以:HDFS权限只是为了防止用户误操作,但防止不了其他人恶意操作文件
HDFS上传文件的机架感知策略
什么是机架感知策略
机架感知策略:是指在上传文件时,因为BLK需要在多个DN服务上传文件信息,而BLK怎么选择DN服务器,就是机架感知策略的事情【这样是为了副本在集群中的安全性】
在放置副本的时候,也会考虑副本的 可靠性,可用性,带宽消耗【尽量在本地机房中保存后,也在其他机房或者其他地区的机房保存】
机架感知策略如何帮助BLK选择DN服务器
- BLK的第一个节点
- 集群内部【优先选择和客户端相同的节点作为第一个节点】
- 集群外部【选择资源丰富但是不繁忙的节点作为第一个节点】
- BLK的第二个节点
- 选择和一个节点不同机架的节点
- BLK的第三个节点
- 与第二个节点相同机架的其他节点
- BLK的第N个节点
- 与前面节点不同的其他节点
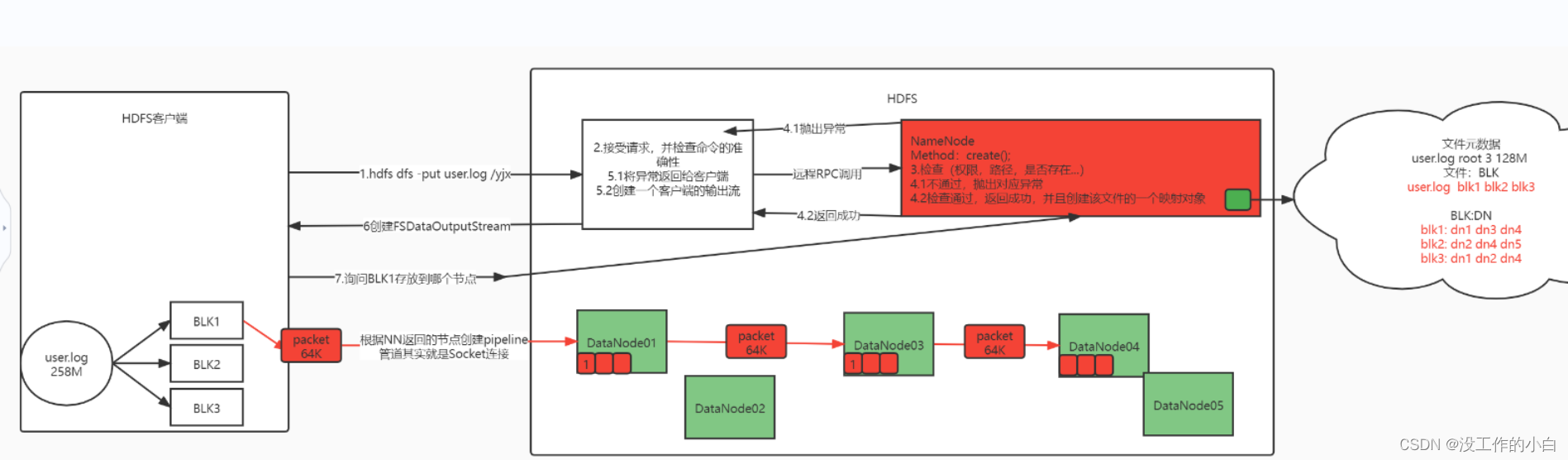
HDFS写入数据的宏观流程
- 客户端给上传文件,给NN服务器发送信息
- NN服务器检查客户端请求的命令是否正确
- 如果不正确,就会抛出异常返给客户端
- 如果正常的话,会创建一个FSDataOutputStream流
- 在创建一个FSDataOputStream流给客户端后,客户端会询问NN服务器,对应切分的文件存放在那个DN节点
- NN服务器会返回值客户端通过,建立客户端和DN服务器的通道【DN服务器之间也会建立通道】
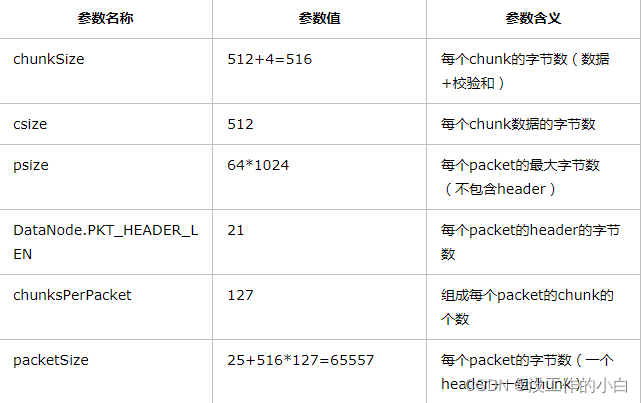
- BLK文件会在切分为Packet包【64K】这样在传输过程中,【1,加快多个节点的传输速度,2:方便传输过程中数据丢失的恢复】
- 客户端会依次传输Packet到建立通道的DN节点A服务器中【占用A节点输入流】,一个packet传递完后,A节点会将这个Packet传递给B节点服务器【副本节点,占用A节点输出流 , B节点的输入流】,B传递给C节点【占用B输出,C输入】依次传递
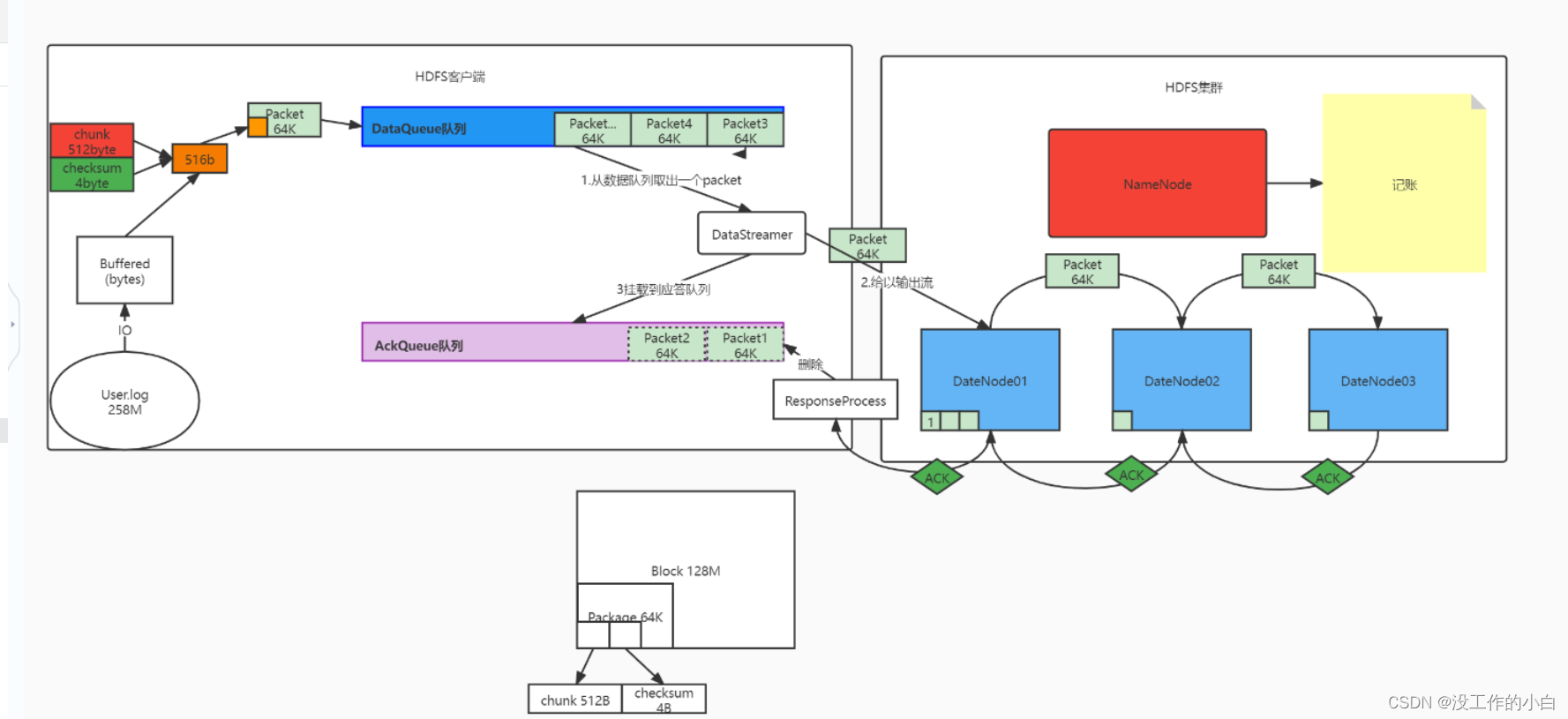
HDFS写入数据的微观流程
- 客户端给上传文件,给NN服务器发送信息
- NN服务器检查客户端请求的命令是否正确
2.1. 如果不正确,就会抛出异常返给客户端
2.2 如果正常的话,会创建一个FSDataOutputStream流- 在创建一个FSDataOputStream流给客户端后,客户端会询问NN服务器,对应切分的文件存放在那个DN节点
- NN服务器会返回值客户端通过,建立客户端和DN服务器的通道【DN服务器之间也会建立通道】
- 客户端从自己的硬盘以流的方式读取数据文件到自己的缓存中
- 将缓存中的数据以chunk(512B)和checksum(4B)的方式放入到packet(64K)
6.1 chunk:checksum=128:1
6.2 checksum:在数据处理和数据通信领域中,用于校验目的的一组数据项的和
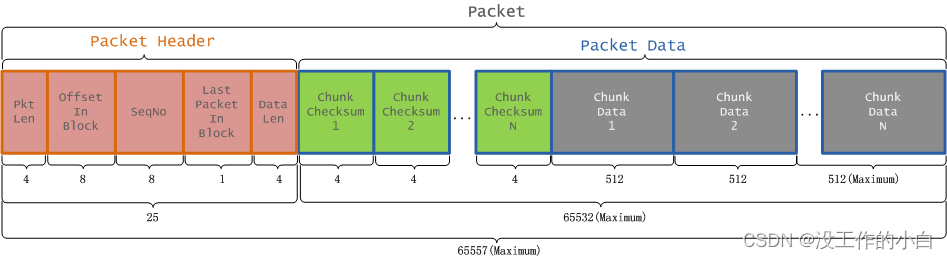
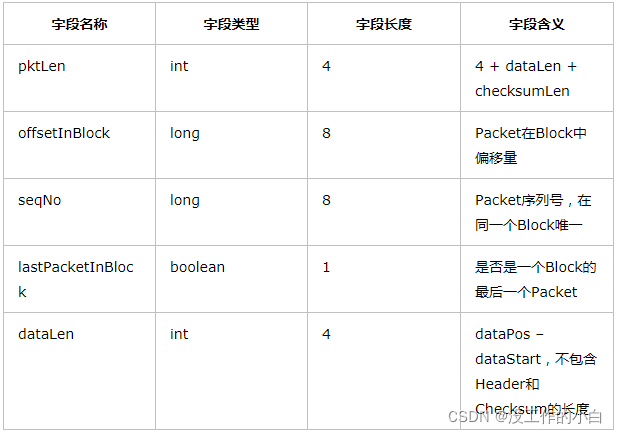
6.3 Packet中的数据分为两类,一类是实际数据包,另一类是header包
6.4 一个Packet数据包的组成结构- 切分为packet包后,会放在DataQueue队列中,等待传输
- 等待服务器读取对应的packet的时候,会取出对应的packet取出来给DN节点响应,这个packet也挂在AckQueue队列中,等待DN服务器应答确认
- 客户端会依次传输Packet到建立通道的DN节点A服务器中【占用A节点输入流】,一个packet传递完后,A节点会将这个Packet传递给B节点服务器【副本节点,占用A节点输出流 , B节点的输入流】,B传递给C节点【占用B输出,C输入】依次传递,传递packet后,DN服务器也会返回给对应的输入流一个ACK应答,确认这个packet包传递没有问题,然后AckQueue等待应答队列会将这个packet删除
- 如果ACK应答的时候,发现某一个packet包传递出现问题,会把挂在AckQueue中对应的packet已经之后没有传递的packet返回给DataQueue队列,重新给DN服务器传递
- 最总在Blk的Packet传递完成后,DFS就保存所有Packet中的ChunkData和ChunkChecksum真实文件内容和文件校验信息
HDFS读取数据流程
- k客户端发送请求,申请读取文件
- DFS通过NN服务器判断客户端用户是否有权限,读取文件是否存在
2.1 如果文件不存在,返回错误信息
2.2 如果文件存在,返回成功信息- DFS建立FSDataInputStream对象,客户端通过这个对象读取数据
- 客户端通过就近原则 ,选择当前文件离客户端近的DN节点,读取完所有的BLK信息后
- 将BLK合并为一个文件,成功后,关闭FSDataInputStream
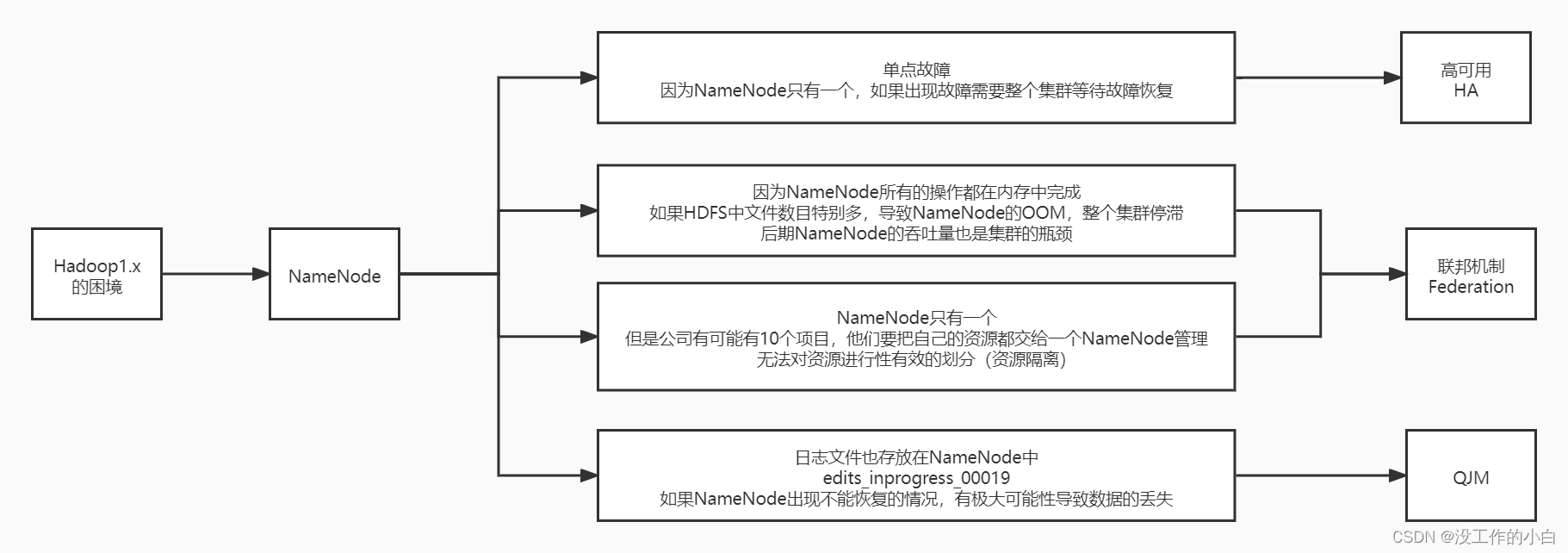
Hadoop1.X的缺点
- 单点故障
1.1 每个群集只有一个NameNode,NameNode存在单点故障(SPOF), 如果该计算机或进程不可用,则整个群集在整个NameNode重新启动或在另一台计算机上启动之前将不可用
1.2 如果发生意外事件(例如机器崩溃),则在操作员重新启动NameNode之前,群集将不可用。
1.3 计划内的维护事件,例如NameNode计算机上的软件或硬件升级,将导致群集停机时间的延长。- 水平扩展
2.1 将来服务器启动的时候,启动速度慢- namenode随着业务的增多,内存占用也会越来越多
3.1 如果namenode内存占满,将无法继续提供服务- 业务隔离性差
- 存储:有可能我们需要存储不同部门的数据
5.1 计算:有可能存在不同业务的计算流程- 项目后期namenode的吞吐量将会是集群的瓶颈
- 客户端所有的请求都会先访问NameNode


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









