




基于Java语言的HDFS文件数据载入(判断文件是否存在、写入文本文件、上传本次文件到HDFS、读取HDFS文件内容)
这里的操作是在Ubuntu16+Hadoop 2.7.x版本下进行
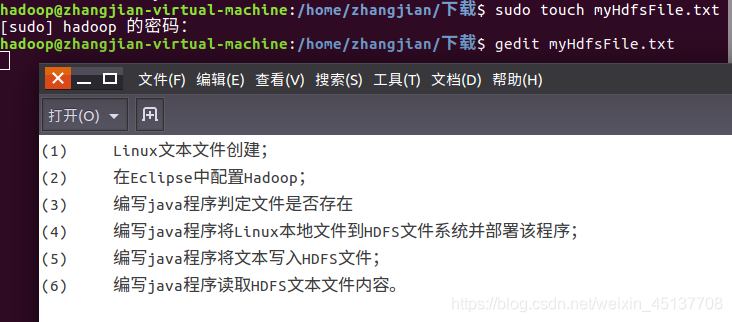
一、Linux文本文件创建
二、在Eclipse中配置Hadoop
参考http://dblab.xmu.edu.cn/blog/290-2/
三、编写java程序判定文件是否存在
进入Hadoop环境
cd /usr/local/hadoop
启动Hadoop
./sbin/start-dfs.sh
查看是否启动成功
jps
编写java程序判断文件是否存在
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSFileIfExist {
public static void main(String[] args){
try{
String fileName = "test";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(fileName))){
System.out.println("文件存在");
}else{
System.out.println("文件不存在");
}
}catch (Exception e){
e.printStackTrace();
}
}
}
注意这里要判断的文件名是test,因为在文件夹中还没有这个文件,所以程序运行的结果肯定是判断文件不存在的,如下图:

将String filename=”test”修改为String fileName = "/user/hadoop/input/first,first.txt是之前创建好的文件,是肯定存在的,如下图:

四、编写java程序将Linux本地文件到HDFS文件系统并部署该程序
这里要用到一开始我们创建的myHdfsFile.txt文件,下面编写程序:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class TextFileToHdfs {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
String localDir = "/home/zhangjian/下载/myHdfsFile.txt";//本地路径
String hdfsDir = "/user/hadoop/input/";//HDFS文件路径
try{
Path localPath = new Path(localDir);
Path hdfsPath = new Path(hdfsDir);
FileSystem hdfs = FileSystem.get(conf);
hdfs.copyFromLocalFile(localPath,hdfsPath);
System.out.println("上传成功");
}catch(Exception e){
e.printStackTrace();
}
}
}
运行结果

查看本地文件是否上传成功
./bin/hdfs dfs -ls /user/hadoop/input

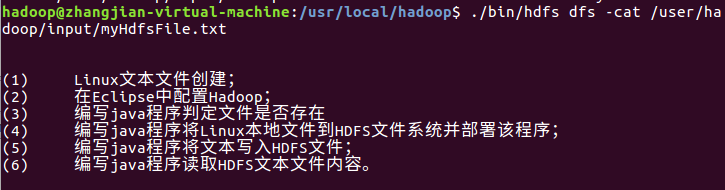
查看文件内容
./bin/hdfs dfs -cat /user/hadoop/input/myHdfsFile.txt
五、编写java程序将文本写入HDFS文件
编写代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
public class InputFileToHdfs {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
byte[] buff = "my name is zhangjian".getBytes(); // 要写入的内容
String filename = "/user/hadoop/input/first.txt"; //要写入的文件名
FSDataOutputStream os = fs.create(new Path(filename));
os.write(buff,0,buff.length);
System.out.println("Create:"+ filename);
os.close();
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:

查看的first.txt文件
./bin/hdfs dfs -cat /user/hadoop/input/first.txt

六、编写java程序读取HDFS文本文件内容
编写代码:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
public class ReadTextFromHdfs {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
Path file = new Path("/user/hadoop/input/first.txt");
FSDataInputStream getIt = fs.open(file);
BufferedReader d = new BufferedReader(new InputStreamReader(getIt));
String content = d.readLine(); //读取文件一行
System.out.println(content);
d.close(); //关闭文件
fs.close(); //关闭hdfs
} catch (Exception e) {
e.printStackTrace();
}
}
}
这里读取的文件是first.txt文件里的内容
运行结果:


















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









