




 业务需求是显示每个部门最高薪水的三条记录,每个部门人数超三人,结果应输出九条记录。可按部门分组、薪水降序排列,但获取每个部门最高薪水前三记录存在问题。使用Hive的Windows函数可解决,如将函数改为DENSE_RANK(),并给出了相应SQL示例。
业务需求是显示每个部门最高薪水的三条记录,每个部门人数超三人,结果应输出九条记录。可按部门分组、薪水降序排列,但获取每个部门最高薪水前三记录存在问题。使用Hive的Windows函数可解决,如将函数改为DENSE_RANK(),并给出了相应SQL示例。
业务需求
有以下两张表
--雇员表
create table emp(
empno INT,COMMENT '雇员编号'
ename STRING,COMMENT '雇员名字'
job STRING,COMMENT '雇员职位'
mgr INT,COMMENT '雇员领导编号'
hiredate STRING,COMMENT '雇员入职时间'
sal DOUBLE,COMMENT '雇员薪水'
comm DOUBLE,COMMENT '雇员奖金'
deptno INT COMMENT '雇员部门编号'
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
--部门表
create table dept(
deptno INT,COMMENT '部门编号'
dname STRING,COMMENT '部门名称'
loc STRING COMMENT '部门所在地'
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
要求显示每个部门最高薪水的三条记录
假设每个部门的人数都会超过三个人 那么这个结果的输出就是九条记录
按照部门分组再根据薪水降序 但是问题在于怎么取得每个部门的最高薪水薪水之前三条呢??
解决办法
hive的Windows函数可以做到 请看以下例子
select
t.empno,t.ename,t.sal,t.deptno,t.rnk
from(
select empno,ename,sal,deptno,ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC ) as rnk from emp
) t```
**输出结果如下:**
[外链图片转存失败(img-vTVubHTQ-1562685843032)(https://img-blog.youkuaiyun.com/20180626200505592?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zOTA1Njg2NA==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)]
**结论**
可以看到使用ROW_NUMBER() 函数可以在分组排序后显示各个分组中的组内排名情况 ,如果只需要每组的前三条记录 加上limit 3即可
select
t.empno,t.ename,t.sal,t.deptno,t.rnk
from(
select empno,ename,sal,deptno,ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC ) as rnk from emp
) t
where
t.rnk<=3**输出结果**
[外链图片转存失败(img-wP98kQ8G-1562685843034)(https://img-blog.youkuaiyun.com/20180626201212325?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zOTA1Njg2NA==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)]
可以看到这个代号为20这个编号的部门有两个人的薪水都是3000 但是排名确不一样 如果需要设置两个3000并列第一的话 改成RANK()函数即可
select
t.empno,t.ename,t.sal,t.deptno,t.rnk
from(
select empno,ename,sal,deptno,RANK() OVER (PARTITION BY deptno ORDER BY sal DESC ) as rnk from emp
) t
where
t.rnk<=3“`
输出结果
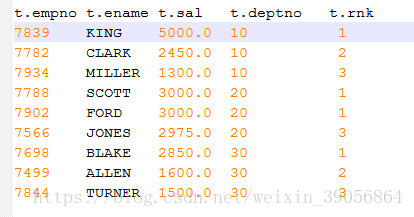
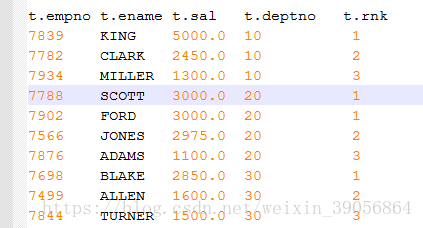
可以看到同一个部门的有两个薪水为3000为并列第一高薪水 但是再下一个就是第3了 如果希望的结果1 1 2 3的话 将函数改为DENSE_RANK()即可
select
t.empno,t.ename,t.sal,t.deptno,t.rnk
from(
select empno,ename,sal,deptno,DENSE_RANK() OVER (PARTITION BY deptno ORDER BY sal DESC ) as rnk from emp
) t
where
t.rnk<=3
输出结果

















 5369
5369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









