







PowerDesigner的安装及使用
一、PowerDesigner安装
1、下载安装包及安装
1.1 安装包
- 安装文件 .exe
- 破解文件
- 汉化文件
下载PowerDesigner16.5、破解、汉化文件地址::百度网盘 提取码:qwas
1.2 安装
- 解压下载的PowerDesigner16.5.exe文件,双击.exe文件,来到安装界面,点击Next

- 选择Trial,点击Next

- 地区选择,选择我同意,点击Next

- 选择安装路径,默认是C盘
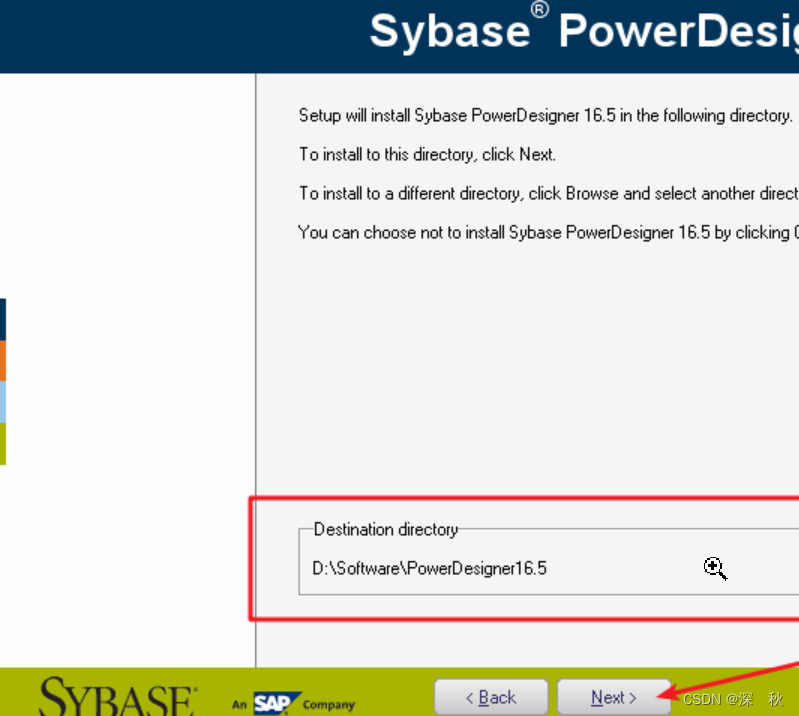
- 这一步直接点击Next
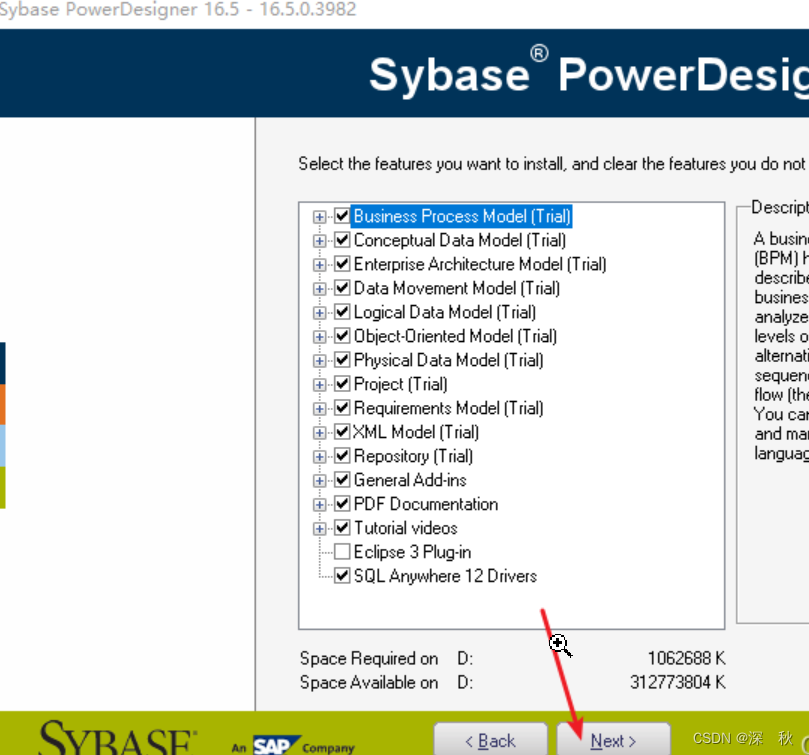
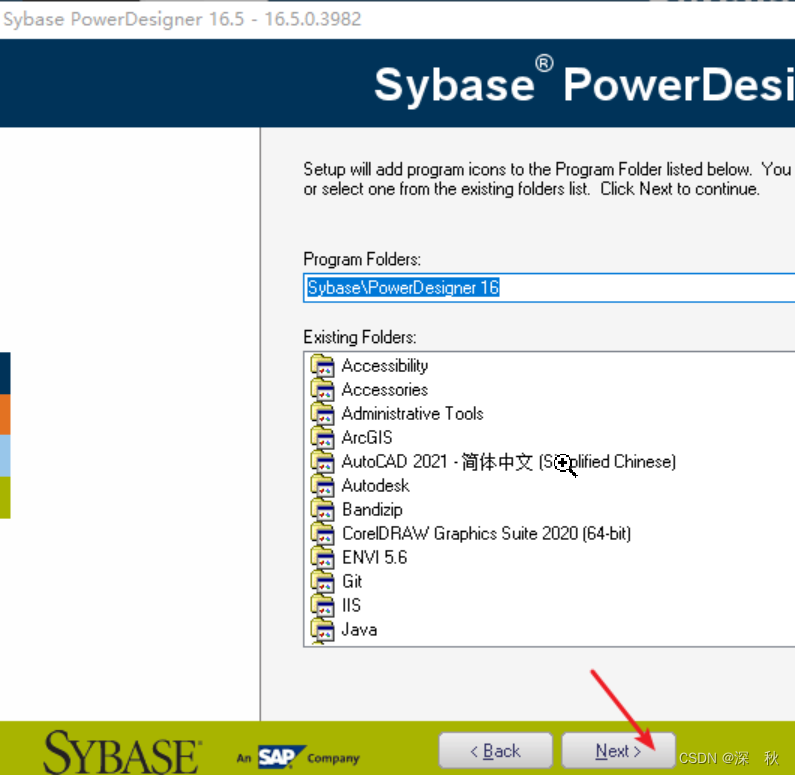
- 选择General和Notation
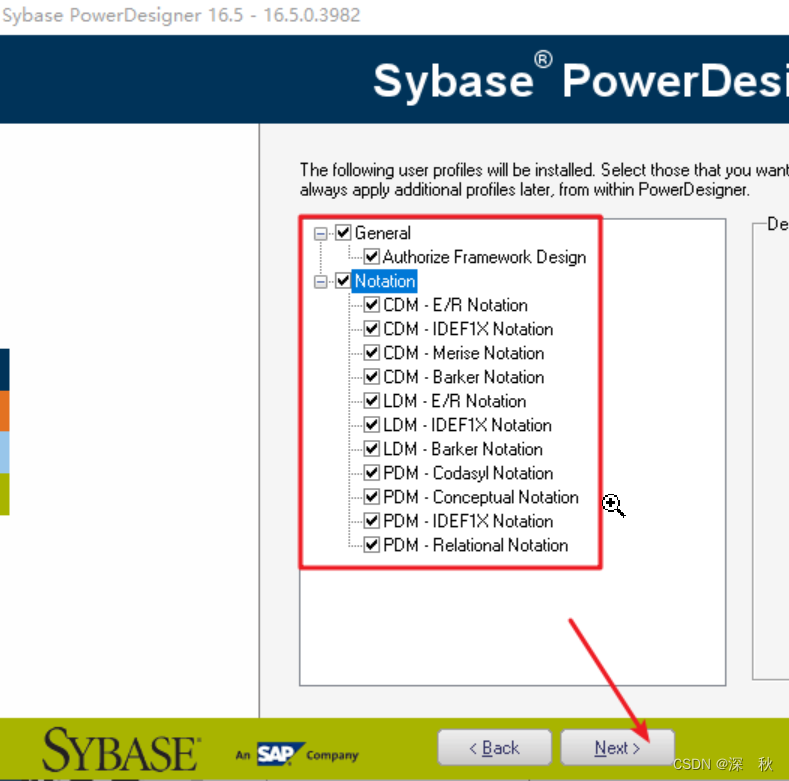
- 点击Next
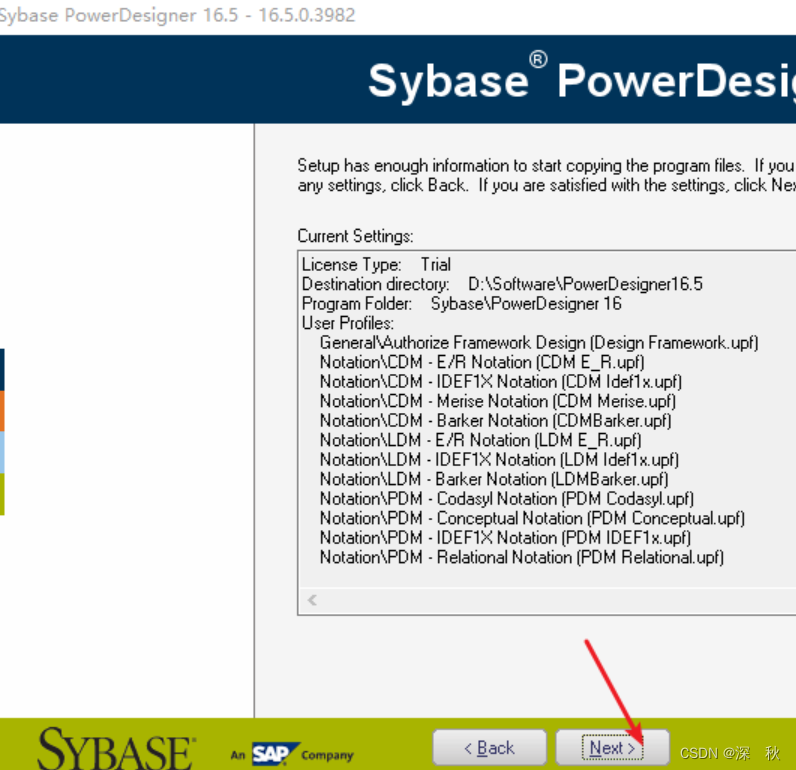

- 安装完成,点击Finish。
2、破解
2.1 解压破解zip文件。
2.2 复制pdflm16.dll文件。
2.3 把文件覆盖到你的软件安装目录下。

3、汉化
3.1 解压汉化zip文件。
3.2 将汉化文件”文件夹下的所有文件全选复制。
3.3 粘贴并覆盖到你软件安装的目录中。
二、PowerDesigner使用
1、逆向工程
1.1 PowerDesigner连接数据库(oracle为例)
因为PowerDesigner是32位的,oraclce是64位的,所以导致通过jdbc连接不上数据库。解决办法,安装32位jdk。
-
这里我用的是免安装32位jdk。
下载地址:百度网盘 提取码:qwas -
下载解压后,添加环境变量。
JAVA_HOME:
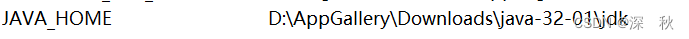
path:

-
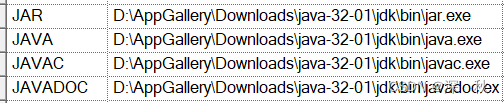
安装后将PowerDesigner的JAR,JAVA,JAVAC,JAVADOC的文件路径指定到安装的jdk的安装文件夹下,Tool ->General Options… ->Variables :
-
测试连接,选择Database -> Connect…
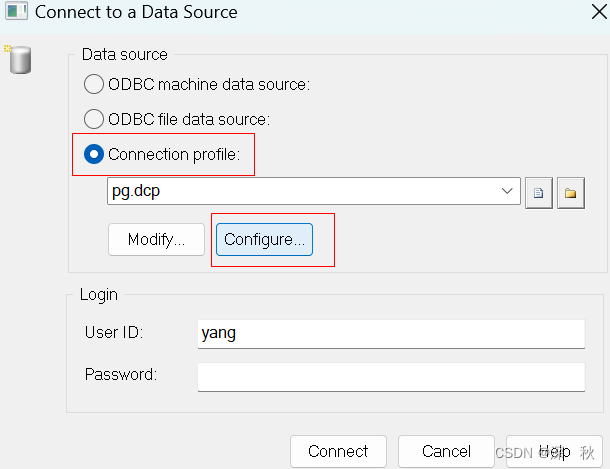
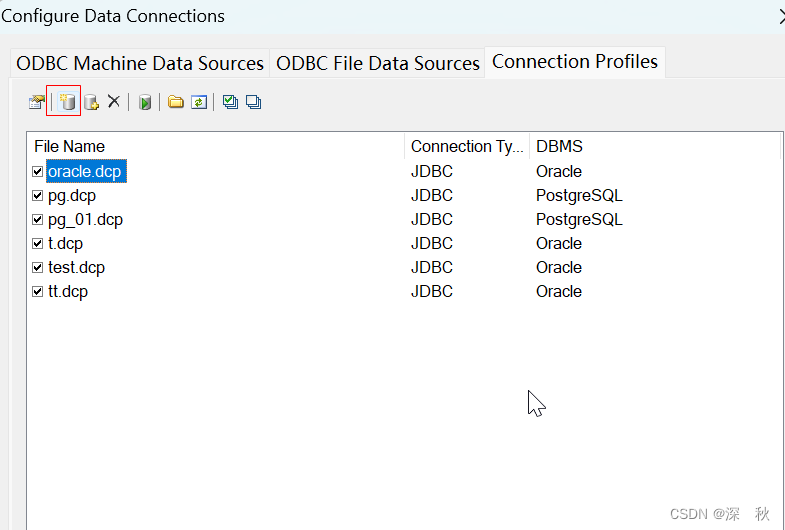
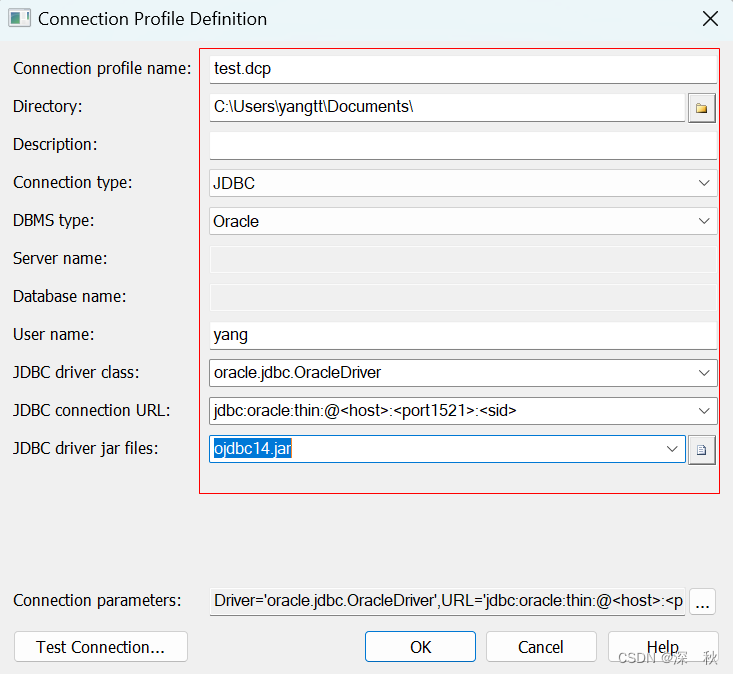
最后确定保存连接就OK了。
1.2 使用逆向工程生成PDM
-
创建pdm模型,先创建一个工作空间,然后在创建模型。
-
选择Database -> Update Model from Database… ,选择要连接的数据库,从数据库获取模型信息。

-
导入表,并设置显示内容。tools->display preferendes->table->advanced.->columns->…
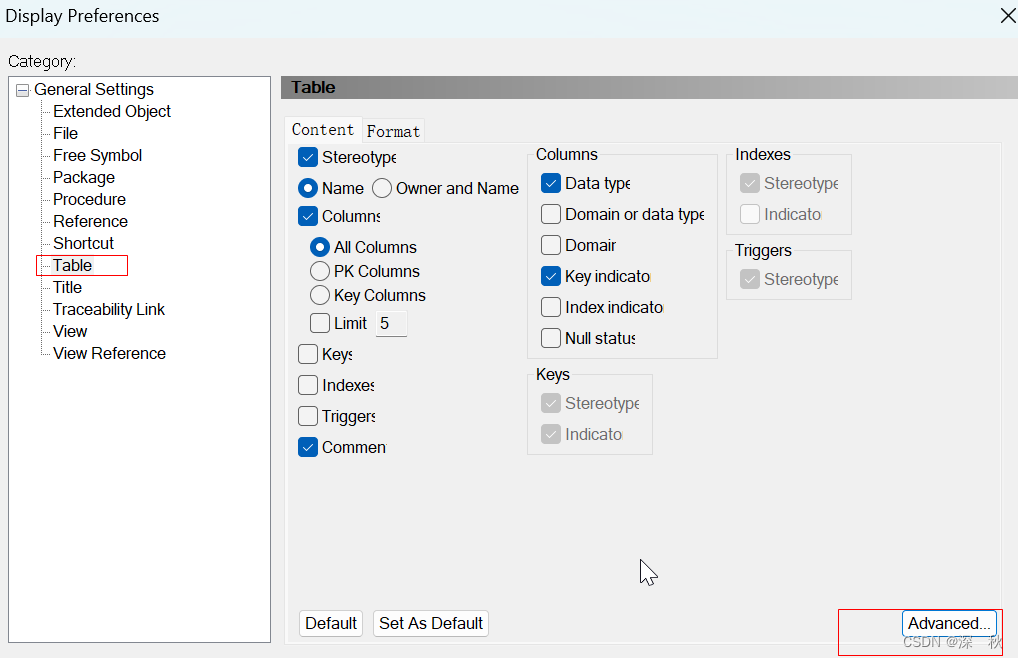

选择需要展示的列
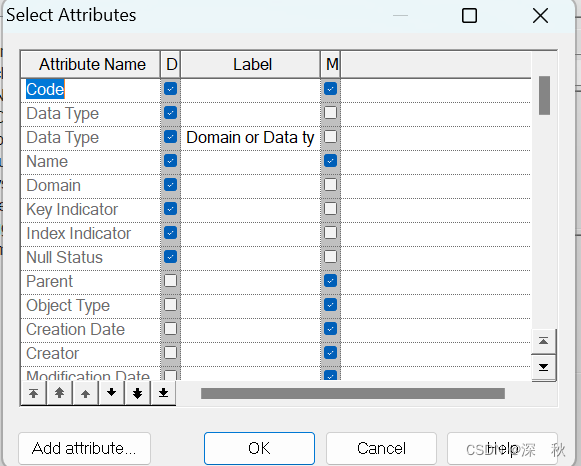
显示结果
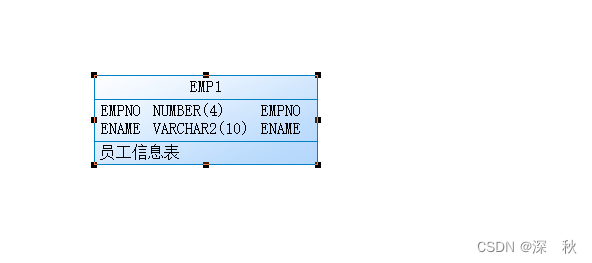
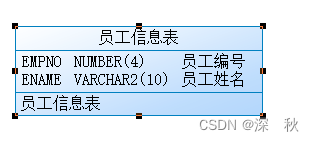
name替换成表注释,tools->,附转换vbs脚本
结果展示
ValidationMode = True InteractiveMode = im_Batch Dim mdl ' the current model ' get the current active model Set mdl = ActiveModel If (mdl Is Nothing) Then MsgBox "There is no current Model " ElseIf Not mdl.IsKindOf(PdPDM.cls_Model) Then MsgBox "The current model is not an Physical Data model. " Else ProcessFolder mdl End If Private sub ProcessFolder(folder) On Error Resume Next Dim Tab 'running table for each Tab in folder.tables if not tab.isShortcut then tab.name = tab.comment Dim col ' running column for each col in tab.columns if col.comment="" then else col.name= col.comment end if next end if next Dim view 'running view for each view in folder.Views if not view.isShortcut then view.name = view.comment end if next ' go into the sub-packages Dim f ' running folder For Each f In folder.Packages if not f.IsShortcut then ProcessFolder f end if Next end sub
表名显示设置,Tool->Model Options->Name Convention->右侧display中选择显示name还是code。
三、总结
本文章是在做表设计的时候用到PowerDesigner中遇到的问题和解决办法的记录,还在学习中,文章中存在不足之处,还请多多包涵。发出来是希望可以帮助遇到同样问题的同学可以参考解决。

















 6566
6566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









