







一.Docker简介
1.为什么会有docker出现
假定您在开发一个商城,您使用的是一台笔记本电脑而且您的开发环境具有特定的配置。其他开发人员身处的环境配置也各有不同。您正在开发的应用依赖于您当前的配置且还要依赖于某些配置文件。此外,您的企业还拥有标准化的测试和生产环境,且具有自身的配置和一系列支持文件。您希望尽可能多在本地模拟这些环境而不产生重新创建服务器环境的开销。请问?
您要如何确保应用能够在这些环境中运行和通过质量检测?并且在部署过程中不出现令人头疼的版本、配置问题,也无需重新编写代码和进行故障修复?
答案就是使用容器。Docker之所以发展如此迅速,也是因为它对此给出了一个标准化的解决方案-----系统平滑移植,容器虚拟化技术。
环境配置相当麻烦,换一台机器,就要重来一次,费力费时。很多人想到,能不能从根本上解决问题,软件可以带环境安装?也就是说,安装的时候,把原始环境一模一样地复制过来。开发人员利用 Docker 可以消除协作编码时“在我的机器上可正常工作”的问题。
之前在服务器配置一个应用的运行环境,要安装各种软件,就拿电商项目的环境来说,Java/RabbitMQ/MySQL/JDBC驱动包等。安装和配置这些东西有多麻烦就不说了,它还不能跨平台。假如我们是在 Windows 上安装的这些环境,到了 Linux 又得重新装。况且就算不跨操作系统,换另一台同样操作系统的服务器,要移植应用也是非常麻烦的。
传统上认为,软件编码开发/测试结束后,所产出的成果即是程序或是能够编译执行的二进制字节码等(java为例)。而为了让这些程序可以顺利执行,开发团队也得准备完整的部署文件,让维运团队得以部署应用程式,开发需要清楚的告诉运维部署团队,用的全部配置文件+所有软件环境。不过,即便如此,仍然常常发生部署失败的状况。Docker的出现使得Docker得以打破过去「程序即应用」的观念。透过镜像(images)将作业系统核心除外,运作应用程式所需要的系统环境,由下而上打包,达到应用程式跨平台间的无缝接轨运作。
2.Doocker是什么
Docker是基于Go语言实现的云开源项目。
Docker的主要目标是“Build,Ship and Run Any App,Anywhere”,也就是通过对应用组件的封装、分发、部署、运行等生命周期的管理,使用户的APP(可以是一个WEB应用或数据库应用等等)及其运行环境能够做到“一次镜像,处处运行”。
Linux容器技术的出现就解决了这样一个问题,而 Docker 就是在它的基础上发展过来的。将应用打成镜像,通过镜像成为运行在Docker容器上面的实例,而 Docker容器在任何操作系统上都是一致的,这就实现了跨平台、跨服务器。只需要一次配置好环境,换到别的机子上就可以一键部署好,大大简化了操作。
解决了运行环境和配置问题的软件容器,方便做持续集成并有助于整体发布的容器虚拟化技术。
3.Docker能干嘛
-
更快速的应用交付和部署
传统的应用开发完成后,需要提供一堆安装程序和配置说明文档,安装部署后需根据配置文档进行繁杂的配置才能正常运行。Docker化之后只需要交付少量容器镜像文件,在正式生产环境加载镜像并运行即可,应用安装配置在镜像里已经内置好,大大节省部署配置和测试验证时间。 -
更便捷的升级和扩缩容
随着微服务架构和Docker的发展,大量的应用会通过微服务方式架构,应用的开发构建将变成搭乐高积木一样,每个Docker容器将变成一块“积木”,应用的升级将变得非常容易。当现有的容器不足以支撑业务处理时,可通过镜像运行新的容器进行快速扩容,使应用系统的扩容从原先的天级变成分钟级甚至秒级。 -
更简单的系统运维
应用容器化运行后,生产环境运行的应用可与开发、测试环境的应用高度一致,容器会将应用程序相关的环境和状态完全封装起来,不会因为底层基础架构和操作系统的不一致性给应用带来影响,产生新的BUG。当出现程序异常时,也可以通过测试环境的相同容器进行快速定位和修复。 -
更高效的计算资源利用
Docker是内核级虚拟化,其不像传统的虚拟化技术一样需要额外的Hypervisor支持,所以在一台物理机上可以运行很多个容器实例,可大大提升物理服务器的CPU和内存的利用率。
4.Docker的基本组成
-
镜像(image)
Docker 镜像(Image)就是一个只读的模板。镜像可以用来创建 Docker 容器,一个镜像可以创建很多容器。
它也相当于是一个root文件系统。比如官方镜像 centos:7 就包含了完整的一套 centos:7 最小系统的 root 文件系统。
相当于容器的“源代码”,docker镜像文件类似于Java的类模板,而docker容器实例类似于java中new出来的实例对象。 -
容器(container)
-
1 .从面向对象角度
Docker 利用容器(Container)独立运行的一个或一组应用,应用程序或服务运行在容器里面,容器就类似于一个虚拟化的运行环境,容器是用镜像创建的运行实例。就像是Java中的类和实例对象一样,镜像是静态的定义,容器是镜像运行时的实体。容器为镜像提供了一个标准的和隔离的运行环境,它可以被启动、开始、停止、删除。每个容器都是相互隔离的、保证安全的平台 -
2 .从镜像容器角度
可以把容器看做是一个简易版的 Linux 环境(包括root用户权限、进程空间、用户空间和网络空间等)和运行在其中的应用程序。
-
-
仓库(repository)
仓库(Repository)是集中存放镜像文件的场所。
类似于Maven仓库,存放各种jar包的地方;github仓库,存放各种git项目的地方;Docker公司提供的官方registry被称为Docker Hub,存放各种镜像模板的地方。
仓库分为公开仓库(Public)和私有仓库(Private)两种形式。
最大的公开仓库是 Docker Hub(https://hub.docker.com/),存放了数量庞大的镜像供用户下载。国内的公开仓库包括阿里云 、网易云等
需要正确的理解仓库/镜像/容器这几个概念:
Docker 本身是一个容器运行载体或称之为管理引擎。我们把应用程序和配置依赖打包好形成一个可交付的运行环境,这个打包好的运行环境就是image镜像文件。只有通过这个镜像文件才能生成Docker容器实例(类似Java中new出来一个对象)。
image文件可以看作是容器的模板。Docker 根据 image 文件生成容器的实例。同一个 image 文件,可以生成多个同时运行的容器实例。
镜像文件
- image 文件生成的容器实例,本身也是一个文件,称为镜像文件。
容器实例
- 一个容器运行一种服务,当我们需要的时候,就可以通过docker客户端创建一个对应的运行实例,也就是我们的容器
仓库
- 就是放一堆镜像的地方,我们可以把镜像发布到仓库中,需要的时候再从仓库中拉下来就可以了。
5.Docker工作原理
Docker是一个Client-Server结构的系统,Docker守护进程运行在主机上, 然后通过Socket连接从客户端访问,守护进程从客户端接受命令并管理运行在主机上的容器。 容器,是一个运行时环境,就是我们前面说到的集装箱。可以对比mysql演示对比讲解

6.Docker安装步骤
-
确定你是CentOS7及以上版本
cat /etc/redhat-release -
yum安装gcc相关
yum -y install gcc
yum -y install gcc-c++ -
安装需要的软件包
yum install -y yum-utils -
设置stable镜像仓库
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -
更新yum软件包索引
yum makecache fast -
安装DOCKER CE
yum -y install docker-ce docker-ce-cli containerd.io -
启动docker
systemctl start docker -
测试
docker version
docker run hello-world -
卸载
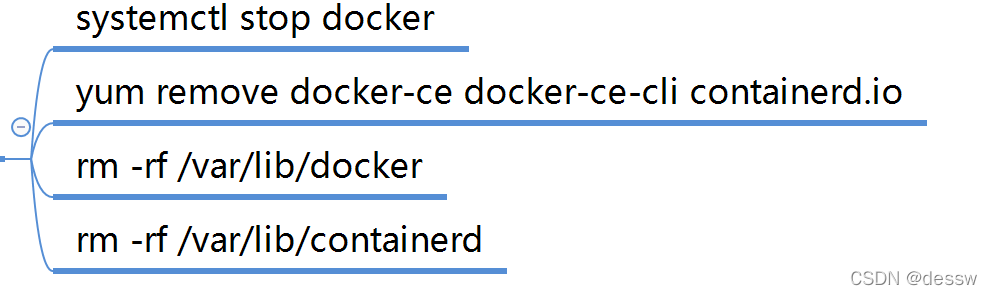
7.阿里云镜像加速
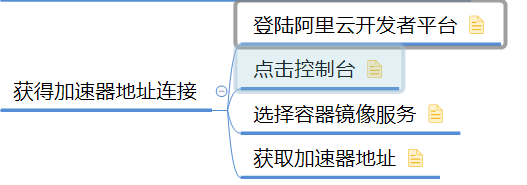
-
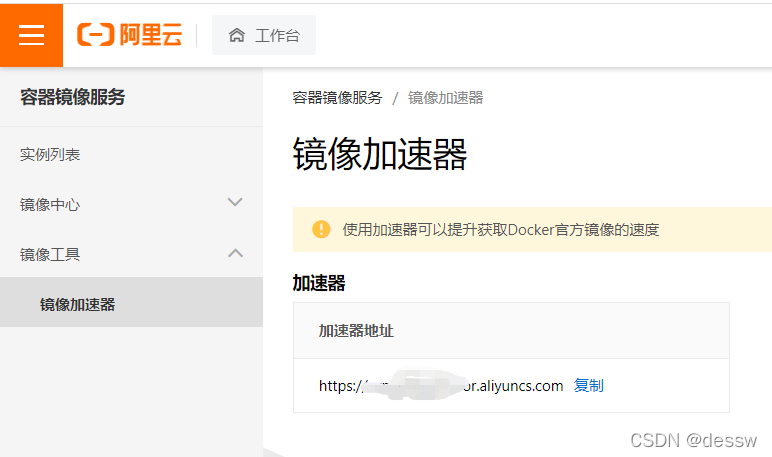
登录阿里云开发者平台获取加速器地址
阿里云地址
-
执行脚本
- mkdir -p /etc/docker
- vim /etc/docker/daemon.json
{
“registry-mirrors”: [“https://{自已的编码}.mirror.aliyuncs.com”]
}
-
重启服务器
systemctl daemon-reload
systemctl restart docker -
测试
docker run hello-world
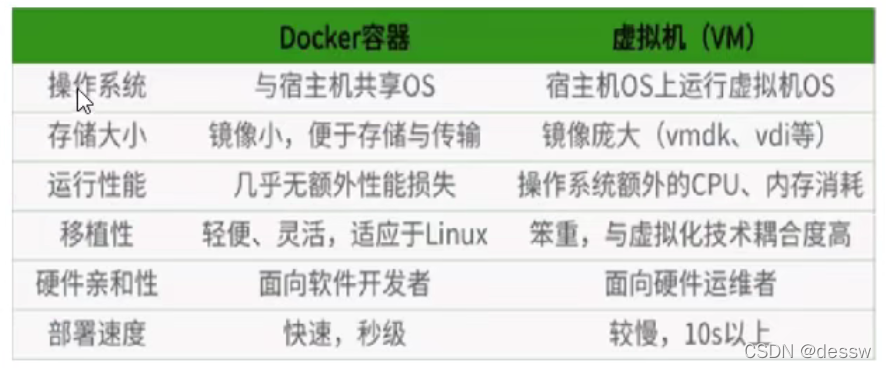
8.为什么Docker会比VM虚拟机快
- docker有着比虚拟机更少的抽象层
由于docker不需要Hypervisor(虚拟机)实现硬件资源虚拟化,运行在docker容器上的程序直接使用的都是实际物理机(宿主机)的硬件资源。因此在CPU、内存利用率上docker将会在效率上有明显优势。
- docker利用的是宿主机的内核,而不需要加载操作系统OS内核
当新建一个容器时,docker不需要和虚拟机一样重新加载一个操作系统内核。进而避免引寻、加载操作系统内核返回等比较费时费资源的过程,当新建一个虚拟机时,虚拟机软件需要加载OS,返回新建过程是分钟级别的。而docker由于直接利用宿主机的操作系统,则省略了返回过程,因此新建一个docker容器只需要几秒钟。
二.Docker常用命令
1.帮助启动类命令
-
启动docker: systemctl start docker
-
停止docker: systemctl stop docker
-
重启docker: systemctl restart docker
-
查看docker状态: systemctl status docker
-
开机启动: systemctl enable docker
-
查看docker概要信息: docker info
-
查看docker总体帮助文档: docker --help
-
查看docker命令帮助文档: docker 具体命令 --help
2.镜像命令
-
docker images
各个选项说明:
REPOSITORY:表示镜像的仓库源
TAG:镜像的标签版本号
IMAGE ID:镜像id
IDCREATED:镜像创建时间
SIZE:镜像大小
同一仓库源可以有多个 TAG版本,代表这个仓库源的不同个版本,我们使用 REPOSITORY:TAG 来定义不同的镜像。
如果你不指定一个镜像的版本标签,例如你只使用 ubuntu,docker 将默认使用 ubuntu:latest 镜像
-a :列出本地所有的镜像(含历史映像层)
-q :只显示镜像ID。

-
docker search [OPTIONS] 某个XXX镜像名字
–limit : 只列出N个镜像,默认25个
docker search --limit 5 redis
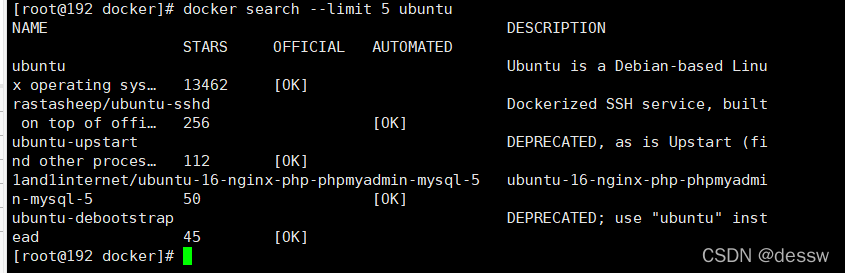
-
docker pull 某个XXX镜像名字[:TAG]
没有TAG就是最新版 等价于 docker pull 镜像名字:latest
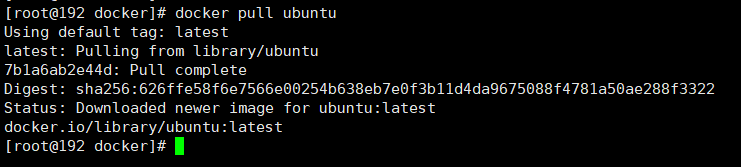
-
docker system df 查看镜像/容器/数据卷所占的空间
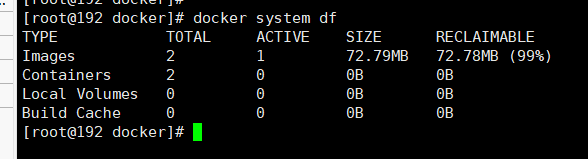
-
docker rmi
删除镜像 docker rmi 某个XXX镜像名字ID
删除单个 docker rmi -f 镜像ID
删除多个 docker rmi -f 镜像名1:TAG 镜像名2:TAG
删除全部 docker rmi -f $(docker images -qa)
-f : 强制删除

3.容器命令
-
docker run [OPTIONS] IMAGE [COMMAND] [ARG…]
OPTIONS说明(常用):有些是一个减号,有些是两个减号
–name=“容器新名字” 为容器指定一个名称;
-d: 后台运行容器并返回容器ID,也即启动守护式容器(后台运行);
-i:以交互模式运行容器,通常与 -t 同时使用;
-t:为容器重新分配一个伪输入终端,通常与 -i 同时使用;
也即启动交互式容器(前台有伪终端,等待交互);
-P: 随机端口映射,大写P
-p: 指定端口映射,小写p

-
启动交互式容器(前台命令行)
#使用镜像centos:latest以交互模式启动一个容器,在容器内执行/bin/bash命令 :docker run -it centos /bin/bash
参数说明:-i: 交互式操作。-t: 终端。centos : centos 镜像。/bin/bash:放在镜像名后的是命令,这里我们希望有个交互式 Shell,因此用的是 /bin/bash。要退出终端,直接输入 exit:

-
列出当前所有正在运行的容器 :docker ps [OPTIONS]
OPTIONS说明(常用):
-a :列出当前所有正在运行的容器+历史上运行过的
-l :显示最近创建的容器。
-n:显示最近n个创建的容器。
-q :静默模式,只显示容器编号。
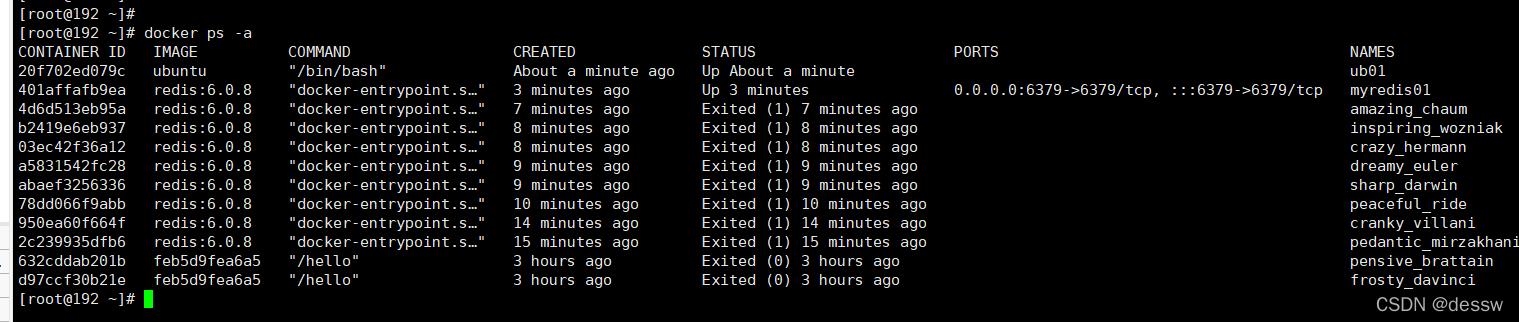
-
退出容器
两种退出方式
exit : run进去容器,exit退出,容器停止
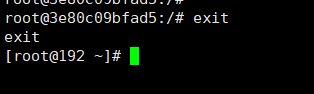
ctrl+p+q : run进去容器,ctrl+p+q退出,容器不停止

-
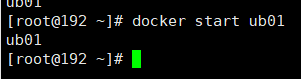
启动已停止运行的容器
docker start 容器ID或者容器名
-
重启容器
docker restart 容器ID或者容器名

-
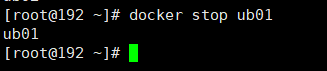
停止容器
docker stop 容器ID或者容器名
-
强制停止容器
docker kill 容器ID或容器名

-
删除已停止的容器
docker rm 容器ID

-
一次性删除多个容器实例
docker rm -f $(docker ps -a -q)
docker ps -a -q | xargs docker rm -
启动守护式容器(后台服务器):docker run -d 容器名
在大部分的场景下,我们希望 docker 的服务是在后台运行的,我们可以过 -d 指定容器的后台运行模式。 -
使用镜像centos:latest以后台模式启动一个容器
docker run -d centos
问题:然后docker ps -a 进行查看, 会发现容器已经退出
很重要的要说明的一点: Docker容器后台运行,就必须有一个前台进程.
容器运行的命令如果不是那些一直挂起的命令(比如运行top,tail),就是会自动退出的。
这个是docker的机制问题,比如你的web容器,我们以nginx为例,正常情况下,我们配置启动服务只需要启动响应的service即可。例如service nginx start,但是,这样做,nginx为后台进程模式运行,就导致docker前台没有运行的应用,这样的容器后台启动后,会立即自杀因为他觉得他没事可做了.所以,最佳的解决方案是,将你要运行的程序以前台进程的形式运行,常见就是命令行模式,表示我还有交互操作,别中断,O(∩_∩)O哈哈~

-
redis 前后台启动演示case
前台交互式启动 docker run -it redis:6.0.8
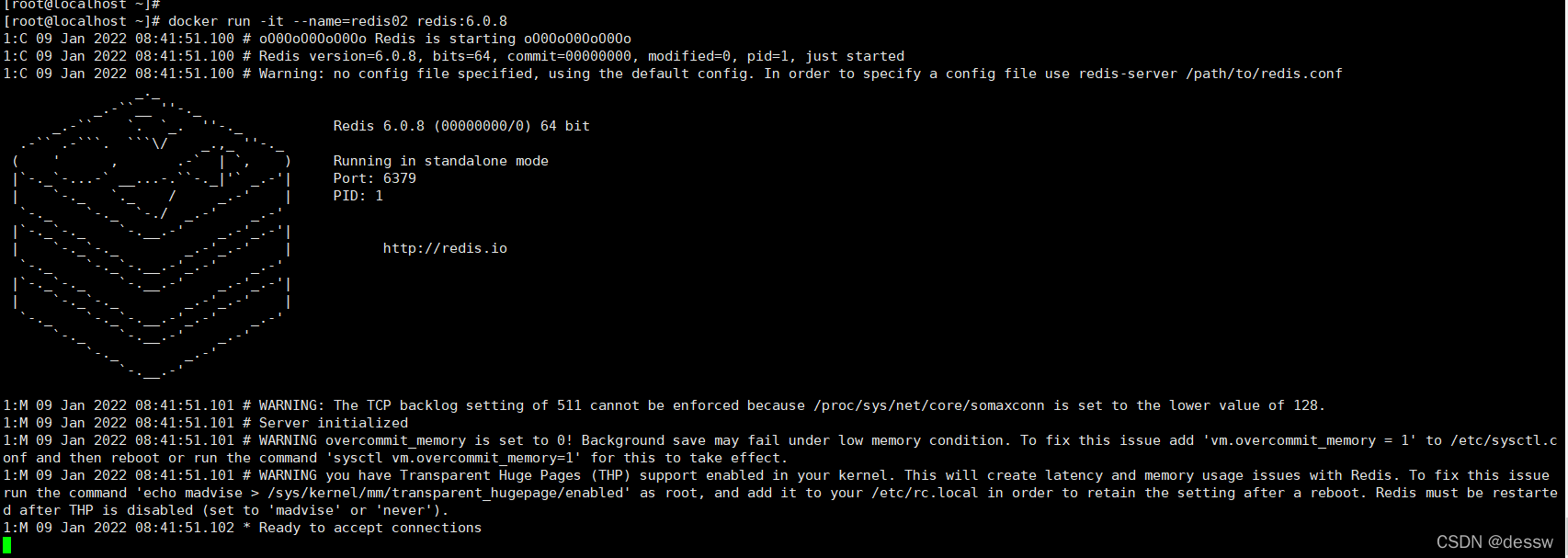
后台守护式启动 docker run -d redis:6.0.8

-
进入正在运行的容器并以命令行交互
docker exec -it 容器ID bashShell

重新进入docker attach 容器ID

区别:
一般用-d后台启动的程序,再用exec进入对应容器实例
attach 直接进入容器启动命令的终端,不会启动新的进程,用exit退出,会导致容器的停止。
exec 是在容器中打开新的终端,并且可以启动新的进程,用exit退出,不会导致容器的停止。
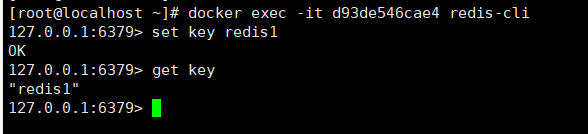
推荐大家使用 docker exec 命令,因为退出容器终端,不会导致容器的停止。
用之前的redis容器实例进入试试

-
查看容器日志
docker logs 容器ID

-
查看容器内运行的进程
docker top 容器ID

-
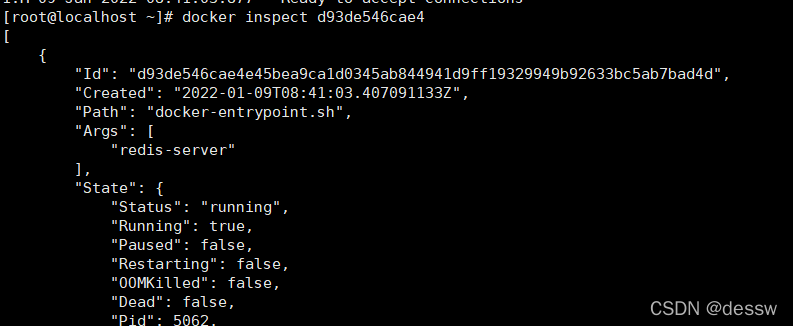
查看容器内部细节
docker inspect 容器ID
-
从容器内拷贝文件到主机上
docker cp 容器ID:容器内路径 目的主机路径 -
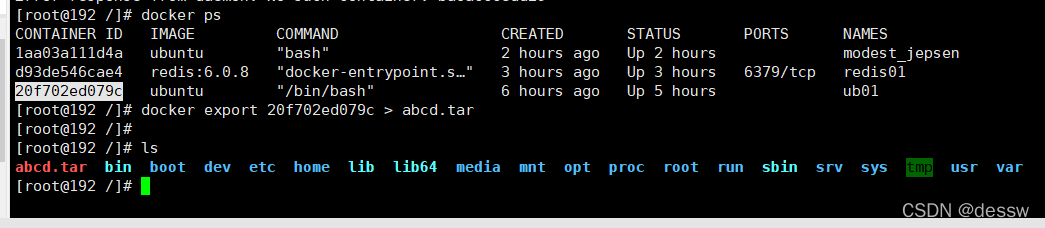
export 导出容器的内容留作为一个tar归档文件[对应import命令]
docker export 容器ID > 文件名.tar
-
import 从tar包中的内容创建一个新的文件系统再导入为镜像[对应export]
cat 文件名.tar | docker import - 镜像用户/镜像名:镜像版本号



三.Docker镜像
1.是什么
镜像是一种轻量级、可执行的独立软件包,它包含运行某个软件所需的所有内容,我们把应用程序和配置依赖打包好形成一个可交付的运行环境(包括代码、运行时需要的库、环境变量和配置文件等),这个打包好的运行环境就是image镜像文件。
只有通过这个镜像文件才能生成Docker容器实例(类似Java中new出来一个对象)。
2.分层的镜像
docker镜像是分层的,以我们的pull为例,在下载的过程中我们可以看到docker的镜像好像是在一层一层的在下载
UnionFS(联合文件系统):Union文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。Union 文件系统是 Docker 镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
特性:一次同时加载多个文件系统,但从外面看起来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录
3.Docker镜像加载原理
Docker镜像加载原理:
docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统UnionFS。
bootfs(boot file system)主要包含bootloader和kernel, bootloader主要是引导加载kernel, Linux刚启动时会加载bootfs文件系统,在Docker镜像的最底层是引导文件系统bootfs。这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。
rootfs (root file system) ,在bootfs之上。包含的就是典型 Linux 系统中的 /dev, /proc, /bin, /etc 等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,Centos等等。
平时我们安装进虚拟机的CentOS都是好几个G,为什么docker这里才200M?
对于一个精简的OS,rootfs可以很小,只需要包括最基本的命令、工具和程序库就可以了,因为底层直接用Host的kernel,自己只需要提供 rootfs 就行了。由此可见对于不同的linux发行版, bootfs基本是一致的, rootfs会有差别, 因此不同的发行版可以公用bootfs。
为什么 Docker 镜像要采用这种分层结构呢
镜像分层最大的一个好处就是共享资源,方便复制迁移,就是为了复用。
比如说有多个镜像都从相同的 base 镜像构建而来,那么 Docker Host 只需在磁盘上保存一份 base 镜像;
同时内存中也只需加载一份 base 镜像,就可以为所有容器服务了。而且镜像的每一层都可以被共享。
重点:
Docker镜像层都是只读的,容器层是可写的
当容器启动时,一个新的可写层被加载到镜像的顶部。
这一层通常被称作“容器层”,“容器层”之下的都叫“镜像层”。
4.Docker镜像commit操作案例
-
docker commit提交容器副本使之成为一个新的镜像
docker commit -m=“提交的描述信息” -a=“作者” 容器ID 要创建的目标镜像名:[标签名] -
案例演示ubuntu安装vim
从Hub上下载ubuntu镜像到本地并成功运行
原始的默认Ubuntu镜像是不带着vim命令的

外网连通的情况下,安装vim
docker容器内执行上述两条命令:
apt-get update
apt-get -y install vim安装完成后,commit我们自己的新镜像
启动我们的新镜像并和原来的对比
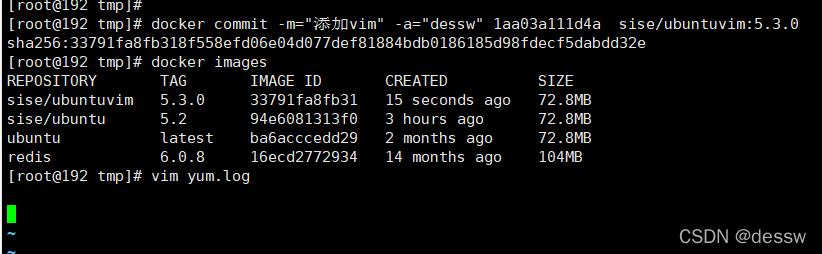
Docker中的镜像分层,支持通过扩展现有镜像,创建新的镜像。类似Java继承于一个Base基础类,自己再按需扩展。新镜像是从 base 镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一层
四.本地镜像发布到阿里云
-
镜像的生成方法
基于当前容器创建一个新的镜像,新功能增强
docker commit [OPTIONS] 容器ID [REPOSITORY[:TAG]] -
进入阿里云开发者平台

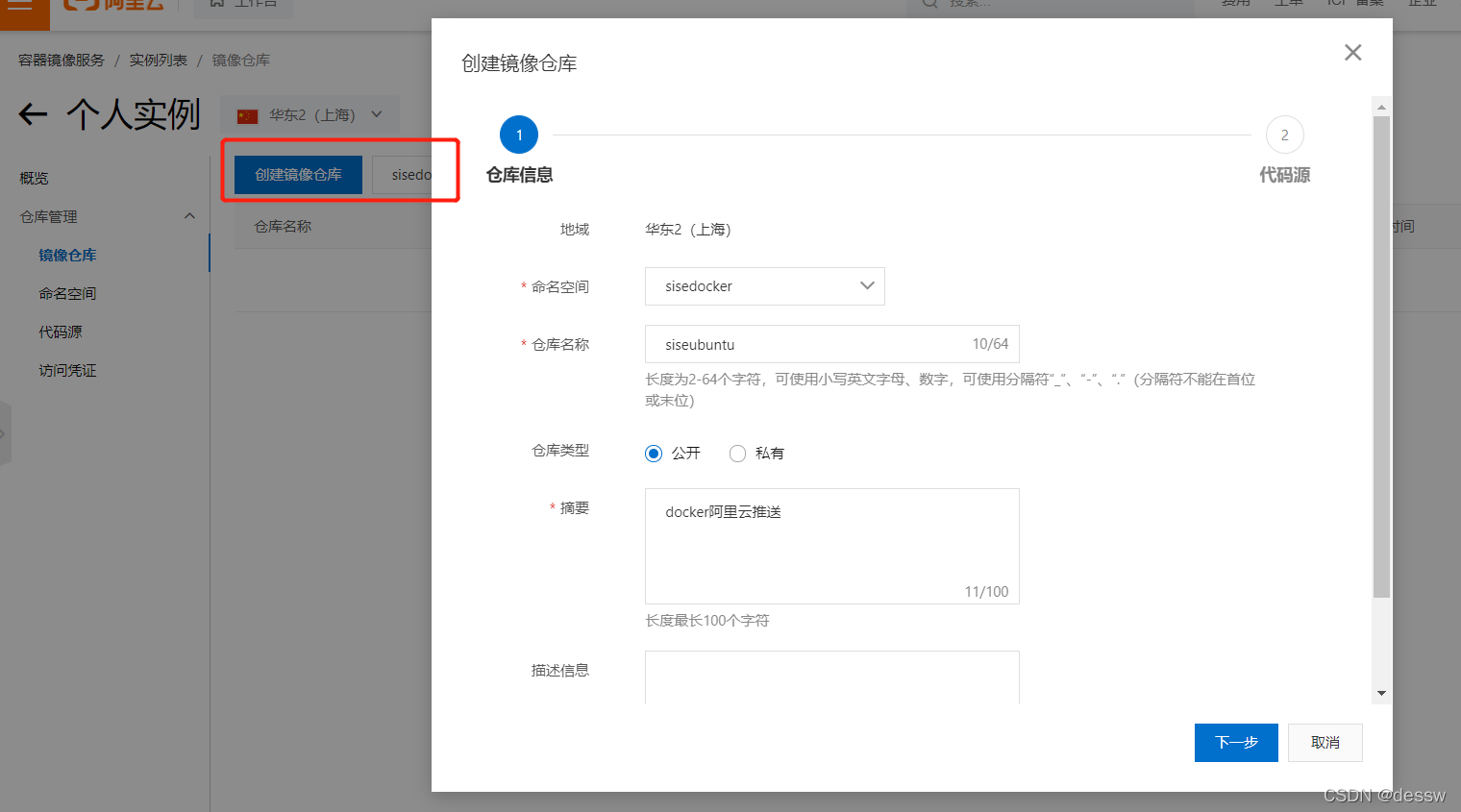
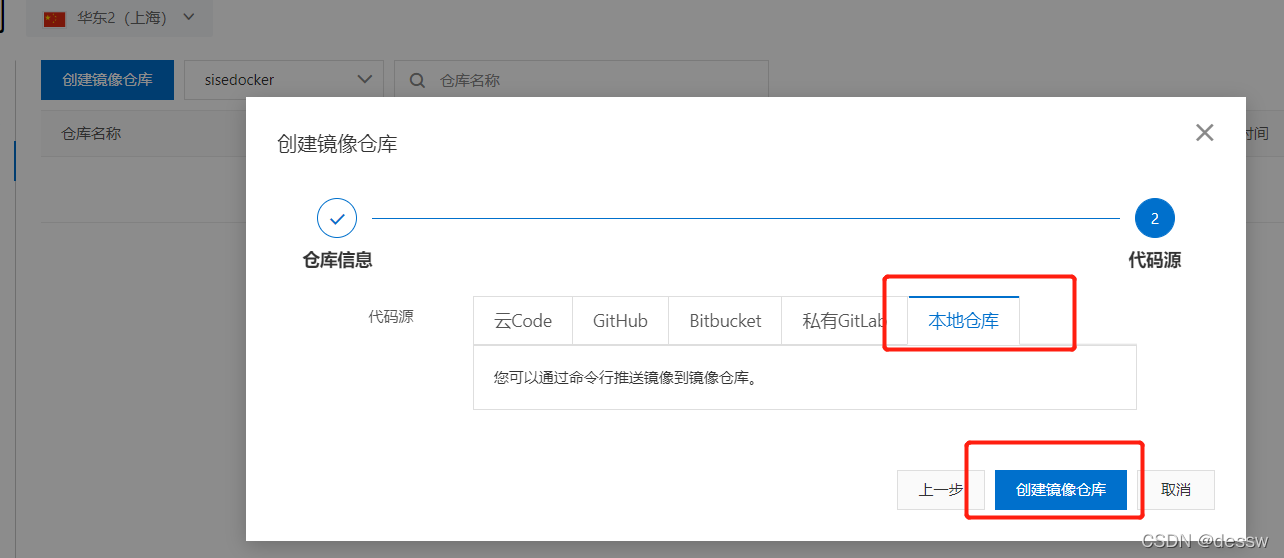
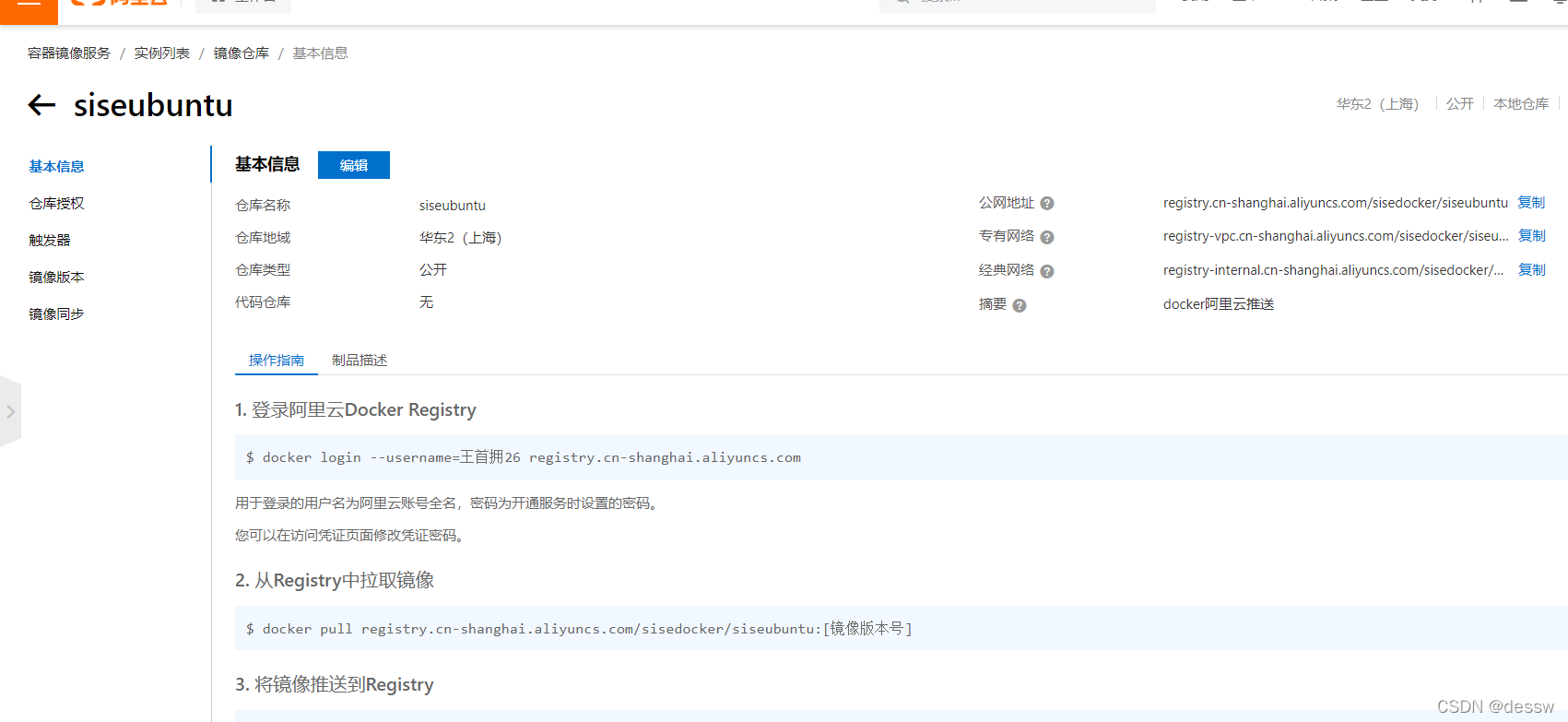
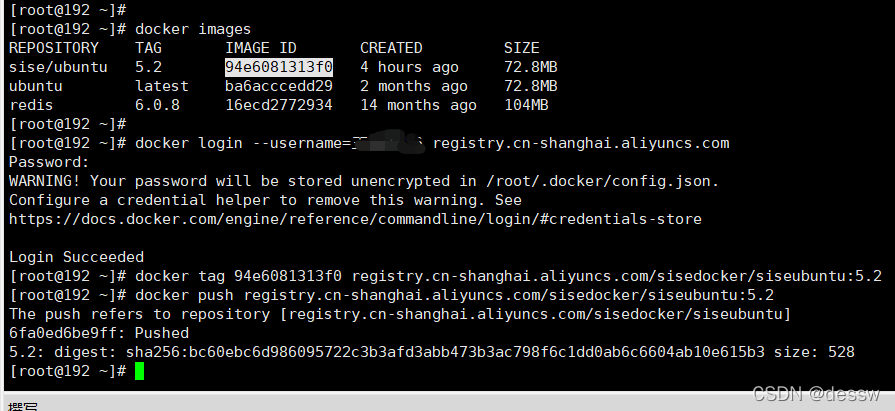
-
将阿里云上的镜像下载到本地
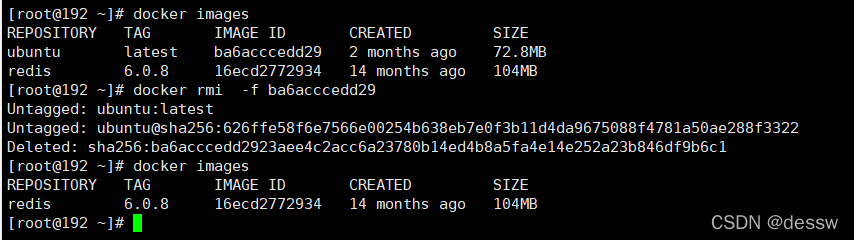
删除本地镜像
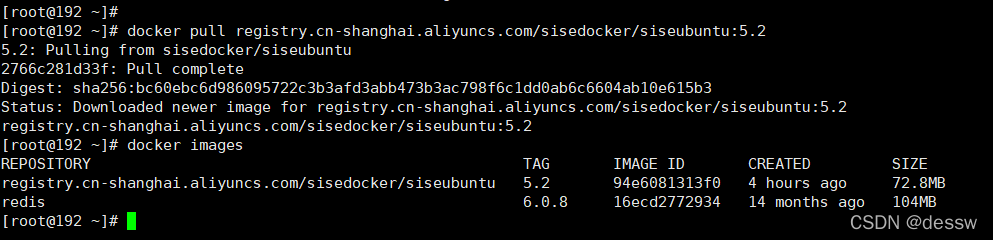
从阿里云上拉取
五.本地镜像发布到私有库
-
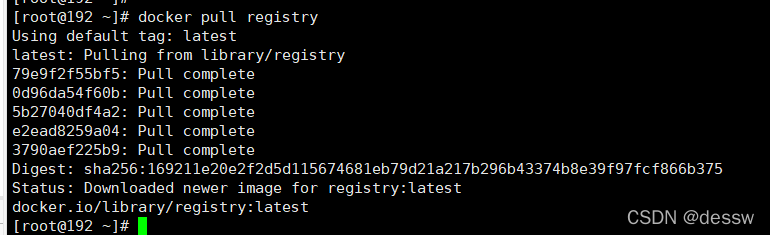
下载镜像Docker Registry
docker pull registry
-
运行私有库Registry,相当于本地有个私有Docker hub
docker run -d -p 5000:5000
-v /messi/myregistry/:/tmp/registry --privileged=true registry
默认情况,仓库被创建在容器的/var/lib/registry目录下,建议自行用容器卷映射,方便于宿主机联调

-
案例演示创建一个新镜像,ubuntu安装ifconfig命令
-
从Hub上下载ubuntu镜像到本地并成功运行原始的Ubuntu镜像是不带着ifconfig命令的
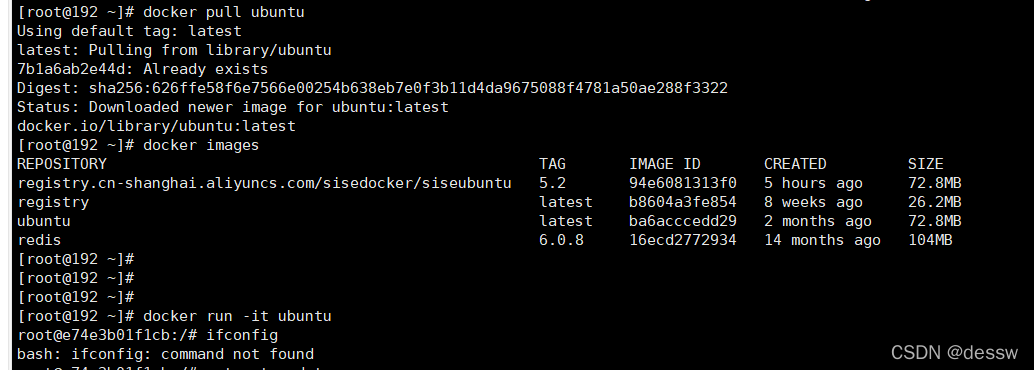
-
外网连通的情况下,安装ifconfig命令并测试通过
docker容器内执行上述两条命令:
apt-get update
apt-get install net-tools
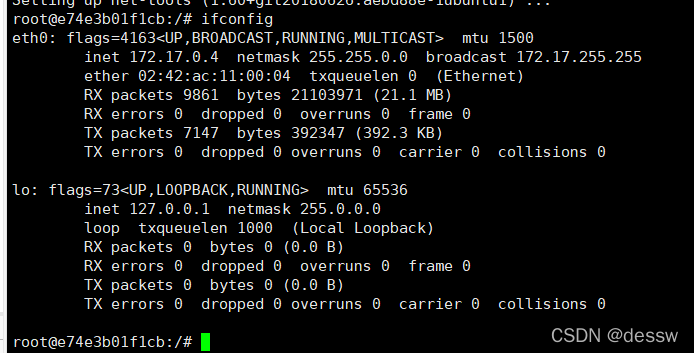
-
安装完成后,commit我们自己的新镜像
docker commit -m=“提交的描述信息” -a=“作者” 容器ID 要创建的目标镜像名:[标签名]
命令:在容器外执行,记得
docker commit -m=“ifconfig cmd add” -a=“zzyy” a69d7c825c4f zzyyubuntu:1.2

-
启动我们的新镜像并和原来的对比

-
-
curl验证私服库上有什么镜像
curl -XGET http://192.168.172.128:5000/v2/_catalog

可以看到,目前私服库没有任何镜像上传过。。。。。 -
将新镜像zzyyubuntu:1.2修改符合私服规范的Tag
docker tag 镜像:Tag Host:Port/Repository:Tag
自己host主机IP地址,
使用命令 docker tag 将wsybuntu:1.2 这个镜像修改为192.168.172.128:5000/wsyubuntu:1.2
docker tag wsyubuntu:1.2 192.168.172.128:5000/wsyubuntu:1.2

-
修改配置文件使之支持http
registry-mirrors 配置的是国内阿里提供的镜像加速地址,不用加速的话访问官网的会很慢。2个配置中间有个逗号 ','别漏了,这个配置是json格式的。
vim命令新增如下红色内容:
vim /etc/docker/daemon.json
{ “registry-mirrors”:[“https://aa25jngu.mirror.aliyuncs.com”],
“insecure-registries”: [“192.168.172.128:5000”]
}
上述理由:docker默认不允许http方式推送镜像,通过配置选项来取消这个限制。====> 修改完后如果不生效,建议重启docker

-
push推送到私服库
docker push 192.168.172.128:5000/wsyubuntu:1.2

-
curl验证私服库上有什么镜像2

-
pull到本地并运行
docker pull 192.168.172.128:5000/wsyubuntu:1.2
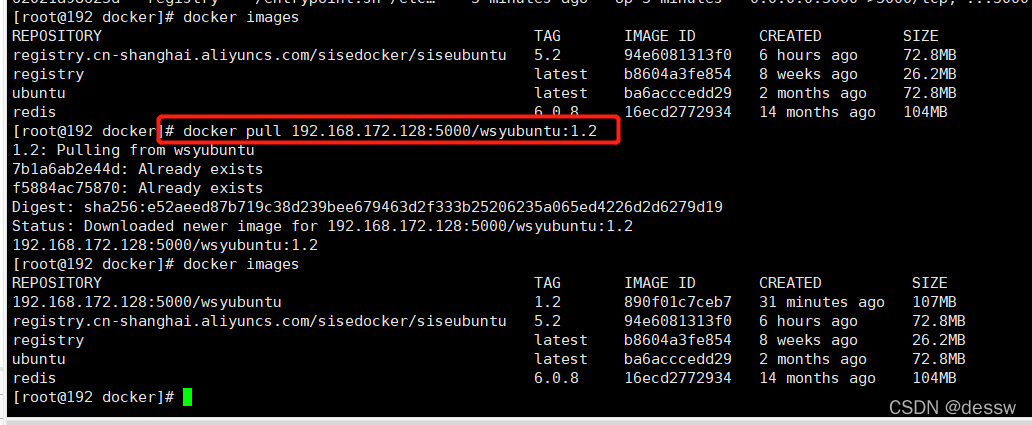
六.Docker容器数据卷
1.简介
Docker挂载主机目录访问如果出现cannot open directory .: Permission denied
解决办法:在挂载目录后多加一个–privileged=true参数即可。
如果是CentOS7安全模块会比之前系统版本加强,不安全的会先禁止,所以目录挂载的情况被默认为不安全的行为,在SELinux里面挂载目录被禁止掉了额,如果要开启,我们一般使用–privileged=true命令,扩大容器的权限解决挂载目录没有权限的问题,也即使用该参数,container内的root拥有真正的root权限,否则,container内的root只是外部的一个普通用户权限。
一句话:Docker容器数据卷有点类似我们Redis里面的rdb和aof文件,将docker容器内的数据保存进宿主机的磁盘中
运行一个带有容器卷存储功能的容器实例命令:
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名
作用: 将运用与运行的环境打包镜像,run后形成容器实例运行 ,但是我们对数据的要求希望是持久化的,Docker容器产生的数据,如果不备份,那么当容器实例删除后,容器内的数据自然也就没有了。为了能保存数据在docker中我们使用卷。
特点:
1:数据卷可在容器之间共享或重用数据
2:卷中的更改可以直接实时生效,爽
3:数据卷中的更改不会包含在镜像的更新中
4:数据卷的生命周期一直持续到没有容器使用它为止
2.数据卷案例
宿主vs容器之间映射添加容器卷
-
命令:docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名

-
查看数据卷是否挂载成功:docker inspect 容器ID
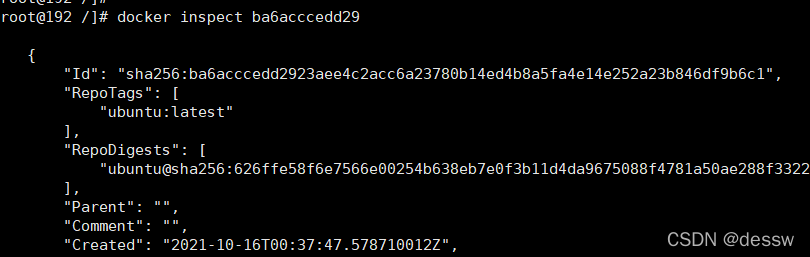
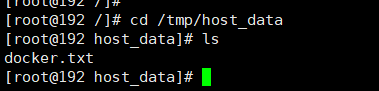
容器和宿主机之间数据共享:
1 docker修改,主机同步获得

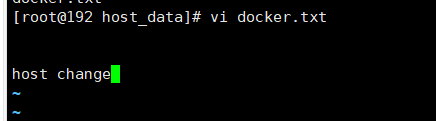
2 主机修改,docker同步获得

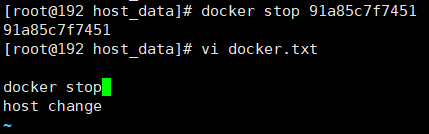
3 docker容器stop,主机修改,docker容器重启看数据是否同步。
3.卷的继承和共享
-
容器1完成和宿主机的映射
docker run -it --privileged=true -v /mydocker/u:/tmp --name u1 ubuntu -
容器2继承容器1的卷规则
docker run -it --privileged=true --volumes-from 父类 --name u2 ubuntu
七.Docker常规安装简介
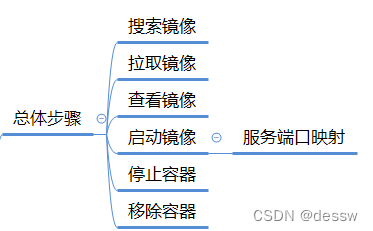
1.总体步骤
2.安装tomcat
-
docker hub上面查找tomcat镜像
docker search tomcat

-
从docker hub上拉取tomcat镜像到本地
docker pull billygoo/tomcat8-jdk8
(若输入docker pull tomcat,会下载最新版tomcat,无法通过8080端口打开首页,需要把webapps.dist目录换成webapps)
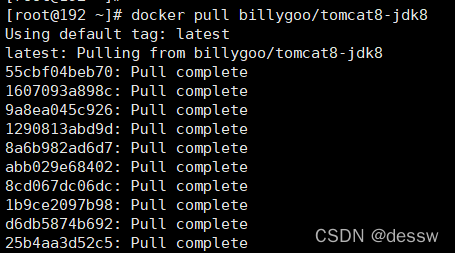
-
docker images查看是否有拉取到的tomcat

-
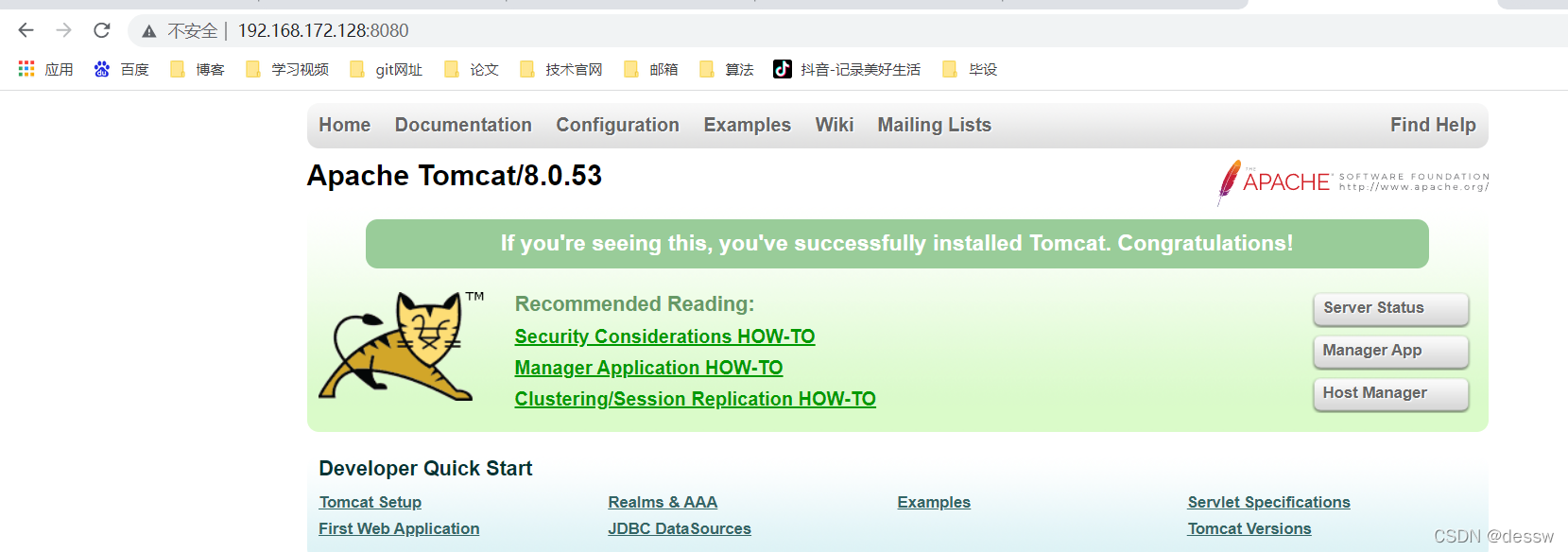
使用tomcat镜像创建容器实例(也叫运行镜像)
docker run -d -p 8080:8080 --name mytomcat8 billygoo/tomcat8-jdk8

3.安装mysql
3.1 简单版
-
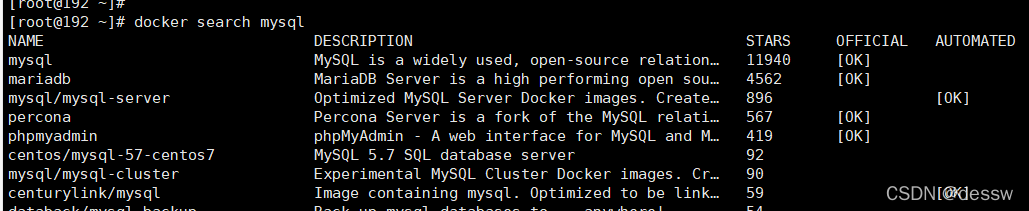
docker hub上面查找mysql镜像
-
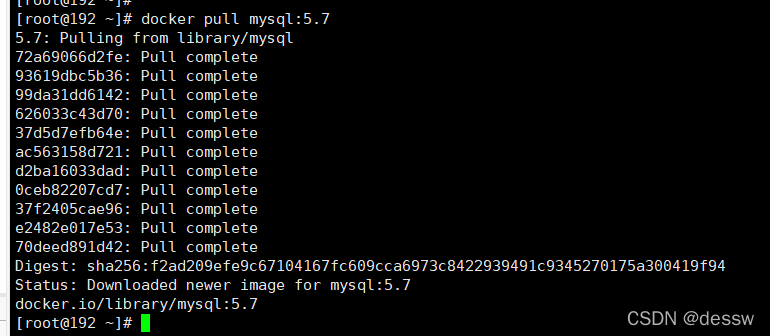
从docker hub上(阿里云加速器)拉取mysql镜像到本地标签为5.7
-
使用mysql镜像
docker run -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7

docker exec -it 82ce4febcce0 /bin/bash

-
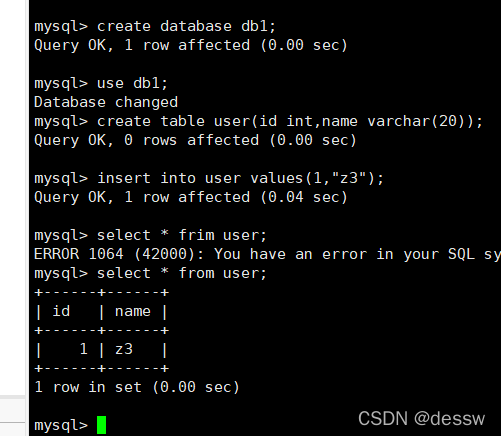
建库建表插入数据
-
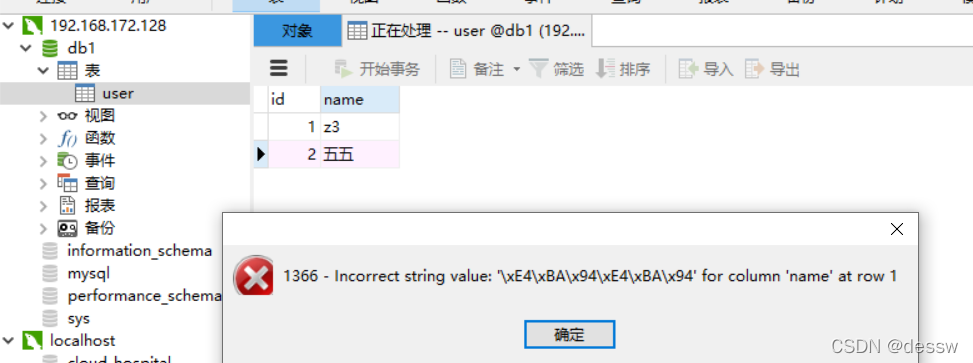
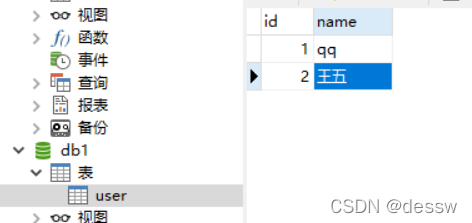
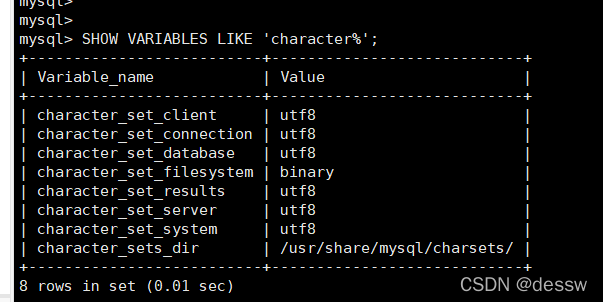
插入中文数据报错
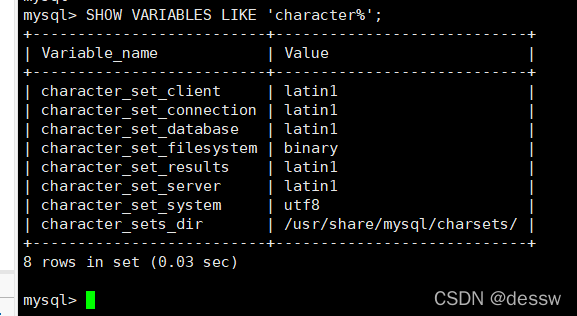
-
除了字符集问题外,删除容器后数据库的数据也会消失,所以需要对容器进行挂载
3.2 实战版
-
新建mysql容器实例
docker run -d -p 3306:3306 --privileged=true
-v /messi/mysql/log:/var/log/mysql
-v /messi/mysql/data:/var/lib/mysql
-v /messi/mysql/conf:/etc/mysql/conf.d
-e MYSQL_ROOT_PASSWORD=root
–name mysql
mysql:5.7

-
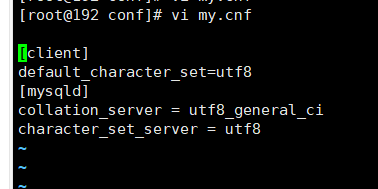
新建my.cnf
[client]
default_character_set=utf8
[mysqld]
collation_server = utf8_general_ci
character_set_server = utf8
-
重新启动mysql容器实例再重新进入并查看字符编码
-
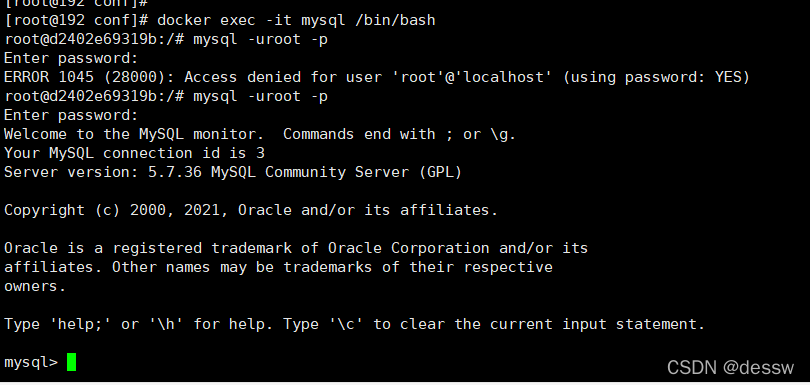
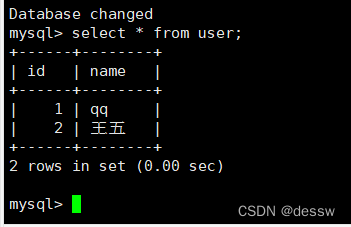
再新建库新建表再插入中文测试
- 倘若误删了mysql镜像,重新运行之后之前挂载的数据依然存在

4.安装redis
- 从docker hub上(阿里云加速器)拉取redis镜像到本地标签为6.0.8


- 使用redis6.0.8镜像创建容器(也叫运行镜像)
docker run -p 6379:6379 --name myr3 --privileged=true -v /messi/redis/redis.conf:/etc/redis/redis.conf -v /messi/redis/data:/data -d redis:6.0.8 redis-server /etc/redis/redis.conf
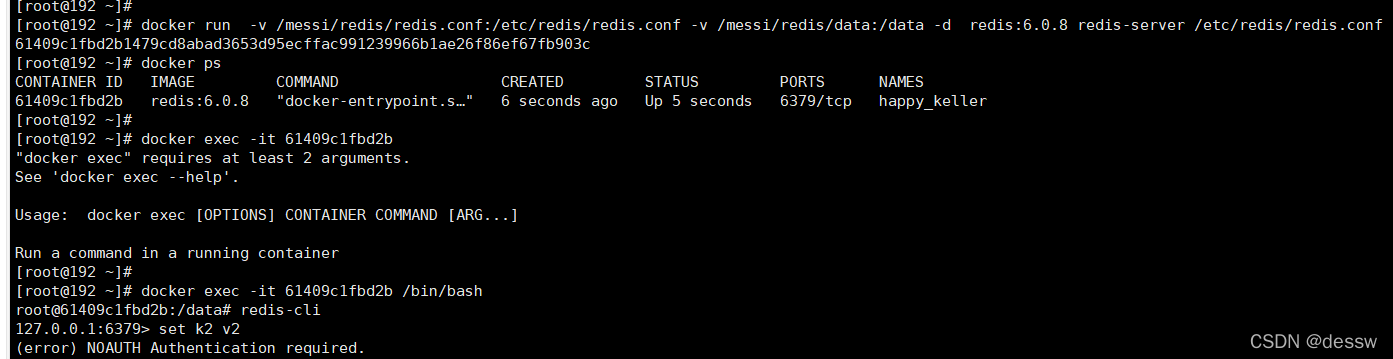
- 请证明docker启动使用了我们自己指定的配置文件


八.面试题
1.谈谈docker虚悬镜像是什么?
仓库名、标签都是的镜像,俗称虚悬镜像dangling image

2.1~2亿条数据需要缓存,请问如何设计这个存储案例
解决方案1:哈希取余分区
2亿条记录就是2亿个k,v,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。
优点: 简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
缺点: 原来规划好的节点,进行扩容或者缩容就比较麻烦了额,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key) /?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
解决方案2:一致性哈希算法分区
一致性Hash算法背景
一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了。
为什么提出一致性Hash解决方案
目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系。
3大步骤
-
算法构建一致性哈希环
什么是一致性哈希环
一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间[0,2^32-1],这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。它也是按照使用取模的方法,前面笔记介绍的节点取模法是对节点(服务器)的数量进行取模。而一致性Hash算法是对2^32 取模,简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-232-1(即哈希值是一个32位无符号整形),整个哈希环如下图:整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、……直到232-1,也就是说0点左侧的第一个点代表2^32-1, 0和232-1在零点中方向重合,我们把这个由232个点组成的圆环称为Hash环。
-
服务器IP节点映射
节点映射
将集群中各个IP节点映射到环上的某一个位置。
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:
key落到服务器的落键规则
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。 -
优点
一致性哈希算法的容错性
假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。
一致性哈希算法的扩展性
数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那收到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,不会导致hash取余全部数据重新洗牌。 -
缺点
一致性哈希算法的数据倾斜问题
Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,
解决方案3:哈希槽分区
-
1 为什么出现
哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。 -
2 能干什么
解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。
哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。 -
3 多少个hash槽
一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot = CRC16(key) % 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。 -
哈希槽计算
Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。如下代码,key之A 、B在Node2, key之C落在Node3上

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









