






根据此大佬学习改变,大佬博客链接
基础配置:
windows10
安装cuda11.8点击此链接
安装支持cuda11.8的cudnn
安装anaconda,点击下载anaconda
一、环境配置
1.官方指定配置文档(README),此文档在自己电脑中配置可能会存在问题。
conda create -n mambayolo -y python=3.11
conda activate mambayolo
pip3 install torch===2.3.0 torchvision torchaudio
pip install seaborn thop timm einops
cd selective_scan && pip install . && cd ..
pip install -v -e .
2.笔者在此做了修改,在笔者电脑已经测试成功。修改如下:
# 注意安装Python的版本改为3.10
conda create -n mambayolo -y python=3.10
conda activate mambayolo
#注意安装Torch指定支持cuda(也就是支持GPU),默认情况下安装仅仅支持CPU。而且不可以使用镜像安装,国内镜像无法指定安装GPU版本的Torch。使用国内镜像安装默认下载支持cpu,检验Torch支持CPU还是CPU可以看后面教程。如果命令下载不了显示网络问题,可以手动去https://download.pytorch.org/whl/cu118网站下载指定版本,再使用命令安装。
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
pip install seaborn thop timm einops
pip install setuptools==68.2.2
conda install packaging
#在Mamba-Yolo-main目录下运行
pip install -v -e .
#最后一步
手动将下载的selective_scan_cuda.cp310-win_amd64.pyd文件手动复制到创建的虚拟环境mambayolo的DLLs文件下。(下载方式见下方)
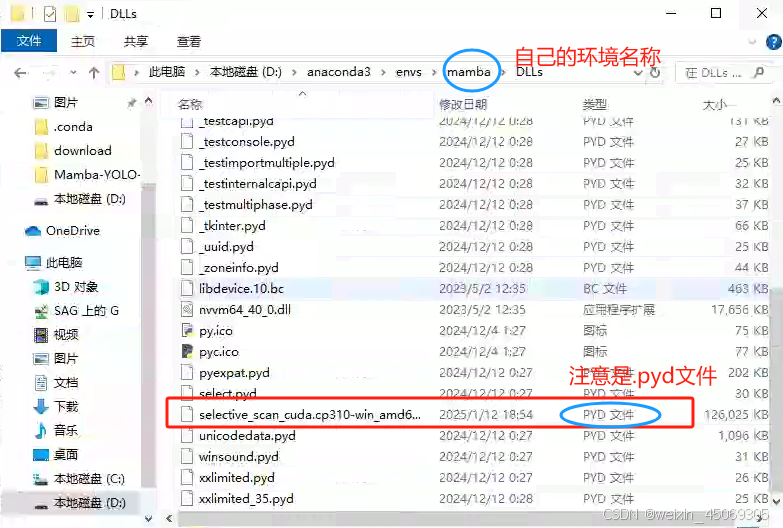
没有对应Windows的库,所以需要对selective_scan的源码进行一些修改(以适应Windows的编译环境),然后使用源码编译和安装,这一步比较困难(Window 下Mamba 环境安装踩坑问题汇总及解决方法 (无需绕过selective_scan_cuda)_windows安装mamba-优快云博客),建议直接使用大佬改好编译好的whl文件,这个文件只适用于torch2.1。可以联系大佬添加微信进行下载whl文件,文章中有大佬微信。
检验Torch支持CPU还是CPU可以看后面教程。
#虚拟环境下
python
#此时进入python编辑器
import torch #不报错,不输出表示torch安装成功
print(torch.__version__) #检查torch版本并且是否支持gpu
#支持GPU输出,例如:torch==2.1.1 + cu118
#支持CPU输出,例如:torch==2.1.1 + cpu
#检查torch与cuda版本是否兼容
print(torch.cuda.is_available())
#兼容输出:True 不兼容输出:False
二、项目配置
打开pycharm
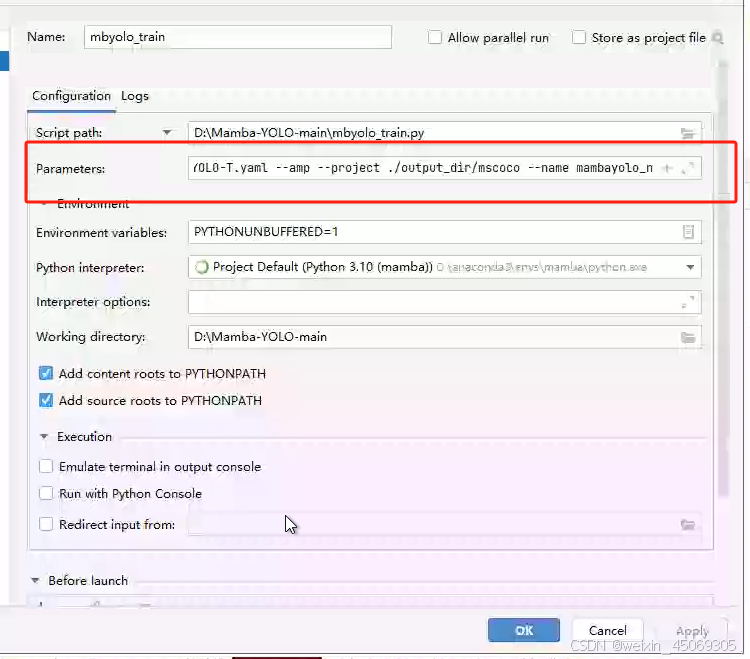
参数:
–task
train
–data
ultralytics/cfg/datasets/coco.yaml
–config
ultralytics/cfg/models/mamba-yolo/Mamba-YOLO-T.yaml
–amp
–project
./output_dir/mscoco
–name
mambayolo_n


















 6649
6649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









