






Spark使用scala语言编写的,scala是面向函数编程
1.Spark的Collect是一个action算子,作用:以数组的形式返回数据集的所有元素
2.Spark的RDD(弹性分布式数据集) 粗颗粒的:将转换规则和数据处理的逻辑进行了封装,实际上是不保存数据,他代表一个不可变、可分区、里面的元素可并行计算的集合。(会进行分区,为了去并行计算)
3.Spark—算子(operate):从认知心理学角度讲,解决问题就是将问题的初始状态,通过一系列的操作(算子)对问题的状态进行转换,然后达到完成(解决)状态
4.Spark中的所有的RDD方法都称之为算子,分为两类:转换算子、行动(执行)算子
5.Spark中创建RDD的方式分三种:从集合中创建(主要)、从外部存储创建(主要)、从其他方式创建(new出来的)
从集合中创建有两种方式:makeRDD()、parallelize()
从外部存储创建:textFile()
6.创建RDD的时候会传两个参数:第一个参数就是文件路径或者数据源,第二个参数是(数据分片数量)分区数量(defaultParallelism),如果第二个参数不写的话会有一个默认值2个
例如: val arrayRDD: RDD[Int] = sc.makeRDD(Array(1,2,3,4,5)) 这时默认分为两个分区
7.map和mapPartitions 算子区别:
map:是对数据源的每一个元素进行遍历
mapPartitions:是对数据源的每一个分区进行遍历
mapPartitions效率优于map算子,减少了发送到执行器执行的交互次数
mapPartitions可能会出现内存溢出(OOM)
小案例
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("Test3").setMaster("local[*]"))
val listRDD: RDD[Int] = sc.makeRDD(1 to 10)
//map算子
val dataRDD: RDD[Int] = listRDD.map(_*2)
//mapPartitions算子
val unit: RDD[Int] = listRDD.mapPartitions(datas => {
datas.map(data => data * 2)
})
unit.collect().foreach(println)
}结果都是一样的
8.Driver:创建Spark上下文对象的应用程序称之为Driver。(有发送任务功能)
Driver主要负责:
1.把用户程序转为作业(job)
2.跟踪Executor运行情况
3.为执行器节点调度任务
4.UI展示应用程序状况
一个类中只要创建了上下文对象(val sc = new SparkContext(config) ),那么这个类就称之为Driver
含有:val sc = new SparkContext(config) 的应用程序就是Driver
Executor(执行器):用于接受任务执行任务(计算),所有RDD算子的计算功能都是在Executor执行的
9.groupBy作用:分组,按照传入函数的返回值进行分组。相同的key对应的值放入一个迭代器。
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("Test3").setMaster("local[*]"))
val listRDD: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6,7,8))
//生成数据,按照指定规则进行分组
//分组后的数据形成了对偶元组(k-v),k代表的是结果(以什么做的分组),v代表的是分组的数据集合
val groupByRDD: RDD[(Int, Iterable[Int])] = listRDD.groupBy(i=>i%2)
groupByRDD.foreach(println)
}运行结果:
相同的key对应的值放入一个迭代器
(0,CompactBuffer(2, 4, 6, 8))
(1,CompactBuffer(1, 3, 5, 7))10.filter:过滤
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("Test3").setMaster("local[*]"))
val listRDD: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6,7,8))
val filterRDD: RDD[Int] = listRDD.filter(i=>i%2==0)
filterRDD.foreach(println)
}结果:
8
6
4
211.aggregateByKey:合并
关于aggreByKey的源代码:
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)] = self.withScope {
aggregateByKey(zeroValue, defaultPartitioner(self))(seqOp, combOp)
}解析源代码:
[U: ClassTag]:是一个泛型aggregateByKey算子有两个参数:第一个初始值:zeroValue,第二个:(seqOp: (U, V) => U, combOp: (U, U) => U)
seqOp:序列计算(在分区内用初始值逐步迭代value) combOp:欲聚合计算(用于合并每个分区中的结果)
RDD[(K, U):返回值类型小案例:
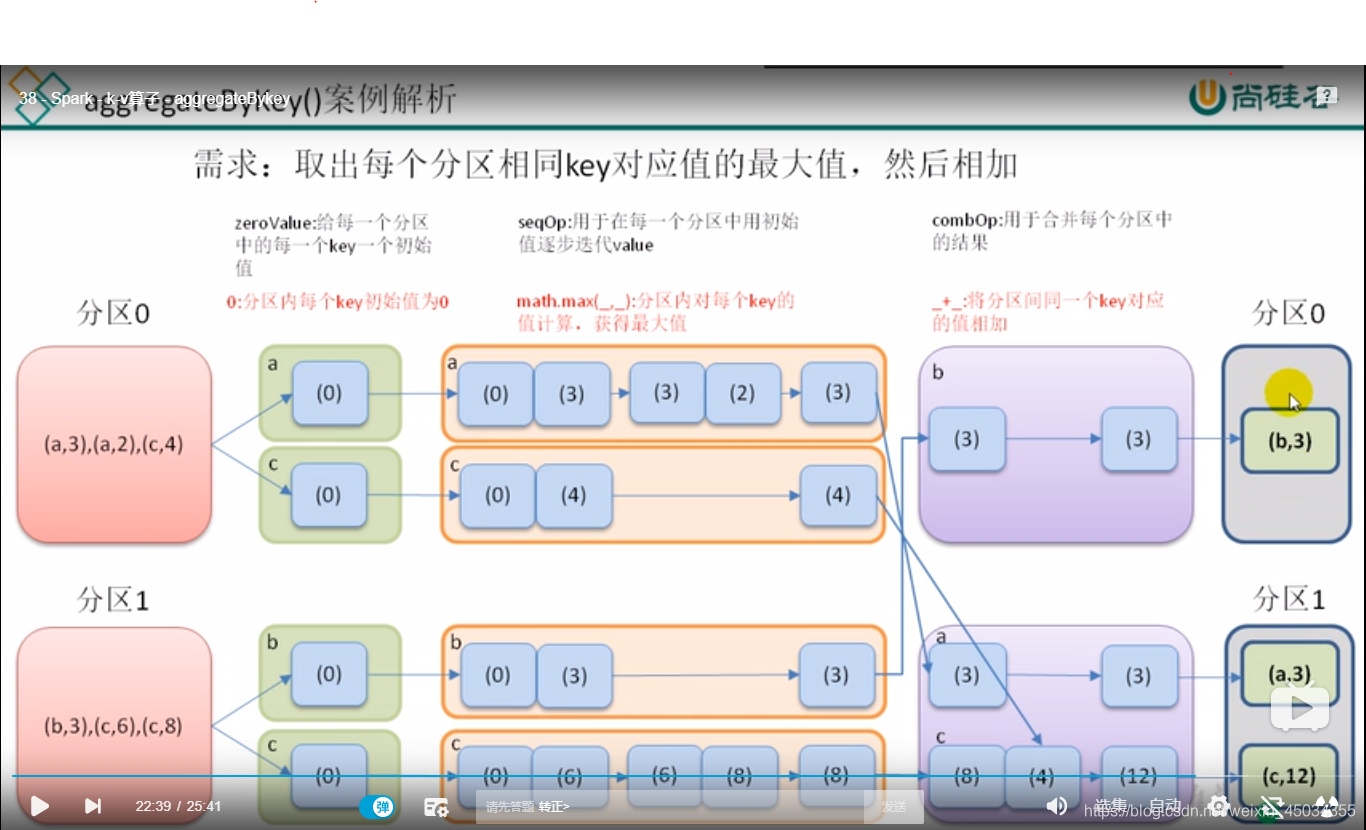
需求:取出每个分区相同的key对应值的最大值,然后key相同,v相加(分区间)
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("Test3").setMaster("local[*]"))
//需求:取出每个分区相同的key对应值的最大值,然后key相同,v相加(分区间)
val tuples = List(("a",3),("a",2),("b",3),("c",4),("c",6),("c",8))
val lines: RDD[(String, Int)] = sc.makeRDD(tuples,2)
val value: RDD[(String, Int)] = lines.aggregateByKey(0)(math.max(_,_),_+_)
value.collect().toBuffer.foreach(println)
sc.stop()
}结果:
(c,12)
(a,3)
(b,3)图解:
12. foldByKey
作用:aggregateByKey的简化操作,seqOp(分区内)和combOp(分区间)相同
源代码:
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)] = self.withScope {
foldByKey(zeroValue, defaultPartitioner(self))(func)
}参数:(zeroValue: V)(func: (V, V) => V)
第一个:初始值:(zeroValue: V) 第二个:计算相同的key对应的值的操作
小案例:
需求:创建一个pairRDD(成对的),计算相同的key对应值的相加结果
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("Test3").setMaster("local[*]"))
val tuples = List(("a",3),("a",2),("b",3),("c",4),("c",6),("c",8))
val lines: RDD[(String, Int)] = sc.makeRDD(tuples,2)
val value: RDD[(String, Int)] = lines.foldByKey(0)(_+_)
value.collect().toBuffer.foreach(println)
sc.stop()
}同理,如果用aggregateByKey来满足上述需求
实现代码:
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("Test3").setMaster("local[*]"))
val tuples = List(("a",3),("a",2),("b",3),("c",4),("c",6),("c",8))
val lines: RDD[(String, Int)] = sc.makeRDD(tuples,2)
val value: RDD[(String, Int)] = lines.aggregateByKey(0)(_+_,_+_)
value.collect().toBuffer.foreach(println)
sc.stop()
}结果:
(b,3)
(a,5)
(c,18)重要实现代码:
flodByKey:val value: RDD[(String, Int)] = lines.foldByKey(0)(_+_)
aggregateByKey:val value: RDD[(String, Int)] = lines.aggregateByKey(0)(_+_,_+_)
所以我们得出:flodByKey是不分区间进行计算的,而是直接按key进行相加,而这里aggregateByKey 是先进行分区内相加,再分区间相加
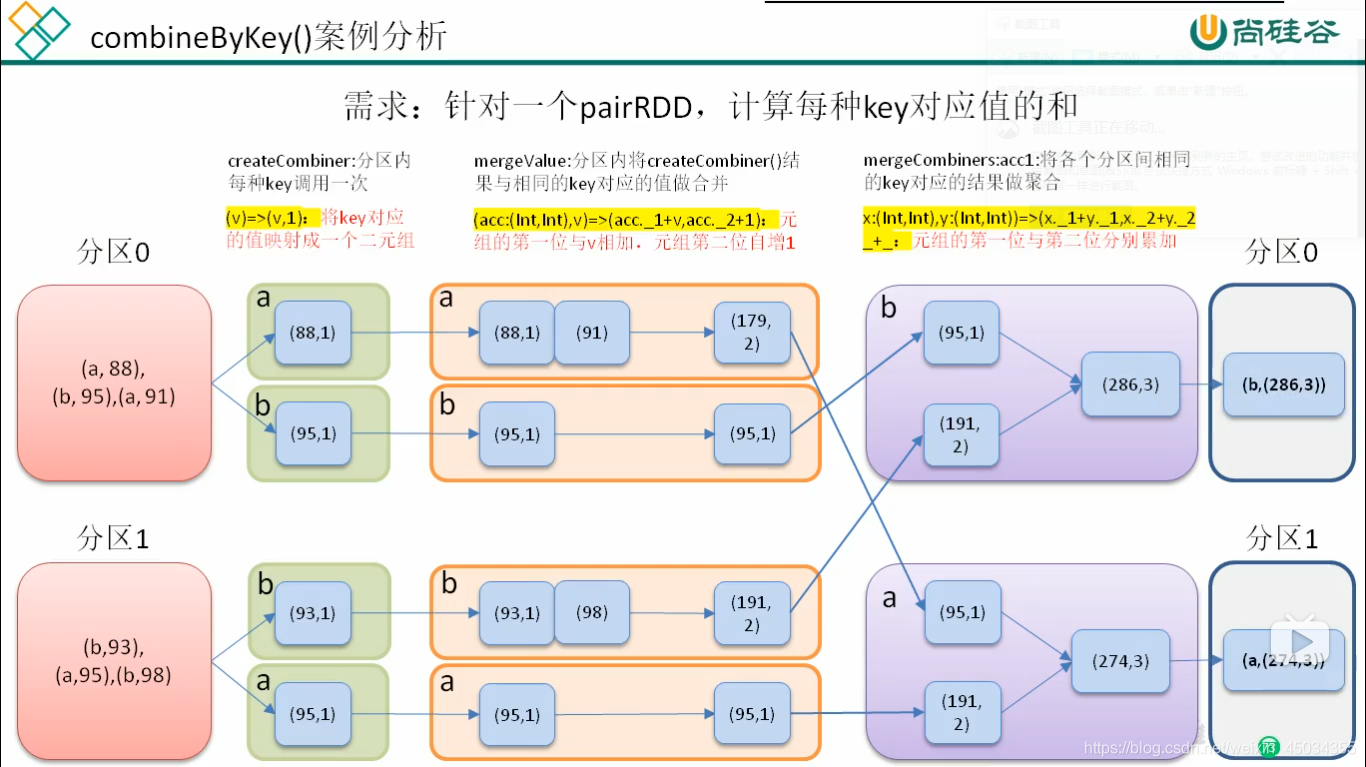
13.combineByKey
作用:对相同的k,把v合并成一个集合
源代码:
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)] = self.withScope {
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners)(null)
}combineByKey算子有三个参数
createCombiner:combineByKey()会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键(k)相同。如果是一个新元素,combineByKey会使用一个叫作createCombiner()函数来创建那个键对应的累加器的初始值(例如:分区中只有一个元素("a",2)那么createCombiner()函数就会创建一个(0))
mergeValue:如果这是一个在处理当前分区之前已经遇到的键,combineByKey会使用mergeValue()方法将该键的累加器对应的当前值与新的值进行合并
mergeCombiners:由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者多个分区对应同一个键的累加器,就需要使用combineByKey提供的mergeCombiners()方法将各个分区结果进行合并。
小案例:
需求:创建一个pairRDD,根据key计算每种key的均值。(先计算每个key出现的次数以及key出现的次数以及可以对应值的综合,在相除得到结果)
实现代码:
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("Test3").setMaster("local[*]"))
val tuples = List(("a",88),("b",95),("a",91),("b",93),("a",95),("b",98))
val lines: RDD[(String, Int)] = sc.makeRDD(tuples,2)
val value: RDD[(String, (Int, Int))] = lines.combineByKey((_,1),(acc:(Int,Int),v)=>(acc._1+v,acc._2+1),(acc1:(Int,Int),acc2:(Int,Int))=>(acc1._1+acc2._1,acc1._2+acc2._2))
value.collect().toBuffer.foreach(print) //结果 1
// (b,(3,1))====(k,v)
val value1: RDD[(String, Double)] = value.map {
case (k, v) => (
k, v._1 / v._2.toDouble
)
}结果:
combineByKey()得出的结果:
(b,(286,3))(a,(274,3))
求的平均值
(b,95.33333333333333)(a,91.33333333333333)图解:
14.mapValues 算子
作用:只针对于(K,V)形式的类型只对V进行操作
用途:在分组之后适合用
小案例:
需求:创建一个pairRDD 并将value添加字符 "|||"
实现代码(scala)
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("Test3").setMaster("local[*]"))
val value: RDD[(String, Int)] = sc.makeRDD(Array(("a",1),("b",3),("c",4),("d",2)))
value.mapValues(_+"|||").foreach(println)
sc.stop()
}结果:
(a,1|||)(b,3|||)(c,4|||)(d,2|||)
15.join 算子
作用:在类型为(K,V)和(K,W)的RDD上调用join,返回一个相同的key对应的所有元素对在一起的(K,(V,W))的RDD
要求:必须是key相同才可以,如果value相同是实现不了.。 性能是比较低的
小案例
需求:创建两个pairRDD,并将key相同的数据聚合到一个元组
实现代码:
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("Test3").setMaster("local[*]"))
val value: RDD[(String, Int)] = sc.makeRDD(Array(("a",1),("b",3),("c",4)))
val value1: RDD[(String, Int)] = sc.makeRDD( Array(("a",5),("b",6),("c",7)))
value.join(value1).foreach(println)
sc.stop()
}运行结果:
(c,(4,7))
(b,(3,6))
(a,(1,5))15.Spark的任务划分(面试重点)
RDD任务切分中间为:Application、Job、Stage和Task
1).Application:初始化一个SparkContext即生成一个Application
2).Job:一个Action算子就会生成一个Job
3).Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage
4).Task:Stage是一个Taskset,将Stage划分的结果发送到不同的Executor执行即为一个Task
注意:Application>Job>Stage>Task 每一层都是1对n的关系
17.Spark目前支持Hash分区和Range分区,用户也可以自定义分区。hash分区(hashpartition)为当前的默认分区,Sparkde分区器直接决定了RDD的分区个数、RDD的每条数据经过shuffle过程属于哪个分区和Reduce的个数
注意:只有Key-Value类型的RDD才具有分区器,非Key-Value类型的RDD分区器的值是None

















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









