







1. numpy读取数据
可以使用numpy中的loadtxt进行数据读取,所包含的参数如下
| 参数名 | 解释 |
|---|---|
| frame | 文件,字符串等也可以是.gz或bz2压缩文件 |
| dtype | 数据类型,即CSV中字符串以什么数据类型读入数组中,默认是np.float |
| delimiter | 分隔字符串,即CSV文件中分隔数据的字符串,默认空格 |
| skiprows | 跳过前多少行,一般跳过第一行表头 |
| usecols | 读取指定的列,索引,元组类型 |
| unpack | 如果是True,读入属性将分别写入不同数组变量,False读入数据只写入一个数组变量,默认False |
本次数据分析所使用的数据源,我已经上传,名称为python中nmupy获取本地数据和索引-US-video-data-numbers,可以进我的主页免费下载,里面数据基本就是截图这样,共有四列
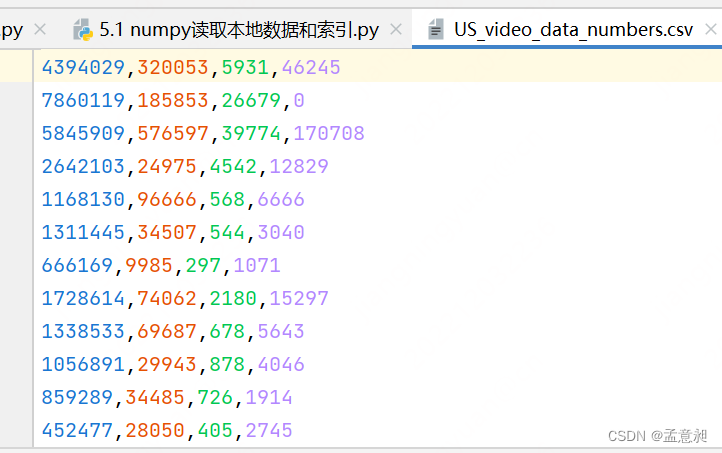
此时可以通过numpy进行数据读取
import numpy as np
#数据源的路径
us_file_path = r"D:\Python_Project\data_analysis\csdn\matplotlib\data\US_video_data_numbers.csv"
t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int")
print(t1)
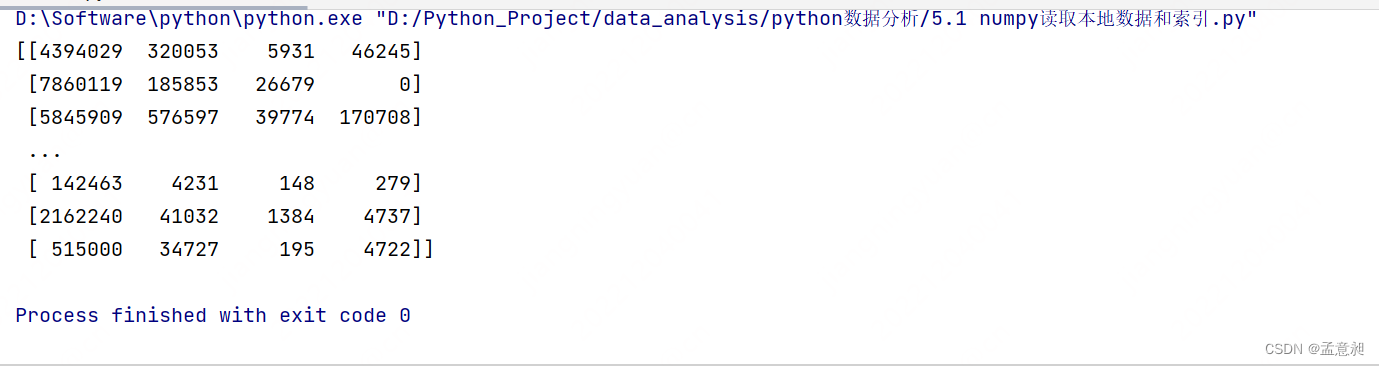
这样就能看到文件里的内容,如果增加unpack=True,那就会得到一个转置后的数据
import numpy as np
#数据源的路径
us_file_path = r"D:\Python_Project\data_analysis\csdn\matplotlib\data\US_video_data_numbers.csv"
t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
print(t1)

2. numpy的索引和切片
2.1 获取特定行
在数据量比较大的时候,直接查询也不会展示所有数据,所以会出现只取其中某行或某列的情况,可以通过索引的方式获取指定行
import numpy as np
#数据源的路径
us_file_path = r"D:\Python_Project\data_analysis\csdn\matplotlib\data\US_video_data_numbers.csv"
t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int")
t2 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
print(t1)
print("*"*100)
#取第3行
print(t1[2])
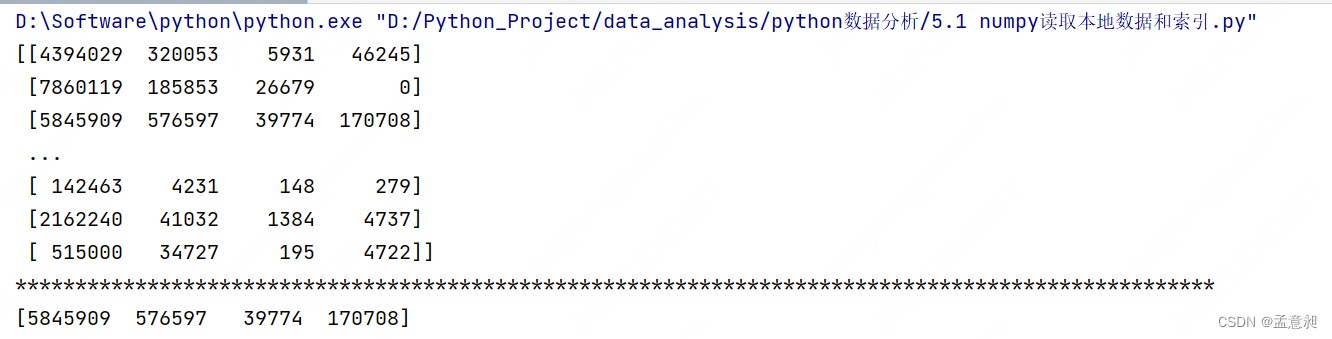
这样就能看到只单独获取了第三行,同样的,也可以获取连续的多行
import numpy as np
#数据源的路径
us_file_path = r"D:\Python_Project\data_analysis\csdn\matplotlib\data\US_video_data_numbers.csv"
t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int")
t2 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
print(t1)
print("*"*100)
#取连续多行 3至5行
print(t1[2:5])

不仅可以获取连续行,也可以获取不连续行
import numpy as np
#数据源的路径
us_file_path = r"D:\Python_Project\data_analysis\csdn\matplotlib\data\US_video_data_numbers.csv"
t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int")
t2 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
print(t1)
print("*"*100)
#取不连续多行 3、6行
print(t1[[2,5]])

2.2 获取特定列
上面说的是如何取特定行,同样的,也可以按需求获取特定列
import numpy as np
#数据源的路径
us_file_path = r"D:\Python_Project\data_analysis\csdn\matplotlib\data\US_video_data_numbers.csv"
t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int")
t2 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
print(t1)
print("*"*100)
#取第一列
print(t1[:,0])
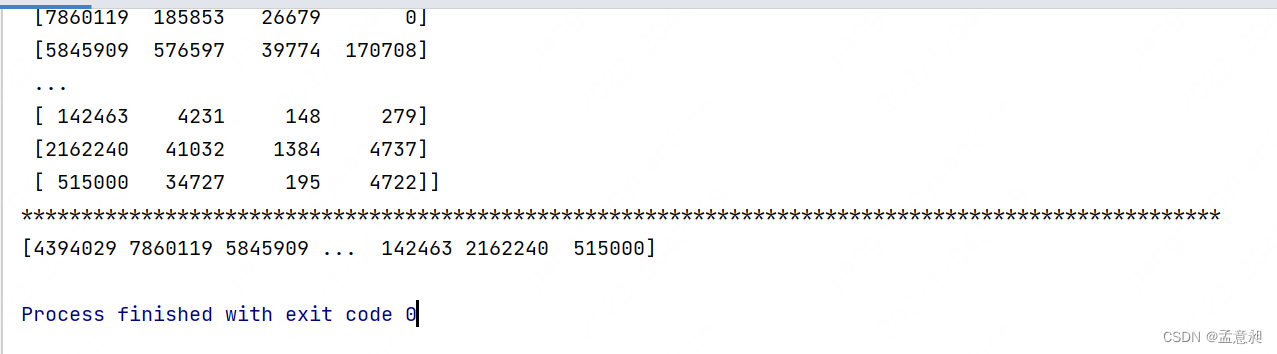
这样就会获取第一列的数据,与取行类似,取列的时候,也可以获取指定列
import numpy as np
#数据源的路径
us_file_path = r"D:\Python_Project\data_analysis\csdn\matplotlib\data\US_video_data_numbers.csv"
t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int")
t2 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
print(t1)
print("*"*100)
#取不连续多列 第一列和第三列
print(t1[:,[0,2]])

2.3 获取特定单元格内的数值
上面已经写了如何获取特定列与特定行,那自然就可以获取指定单元格内的数据
import numpy as np
#数据源的路径
us_file_path = r"D:\Python_Project\data_analysis\csdn\matplotlib\data\US_video_data_numbers.csv"
t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int")
t2 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
print(t1)
print("*"*100)
#取第三行 第四列的值
print(t1[2,3])
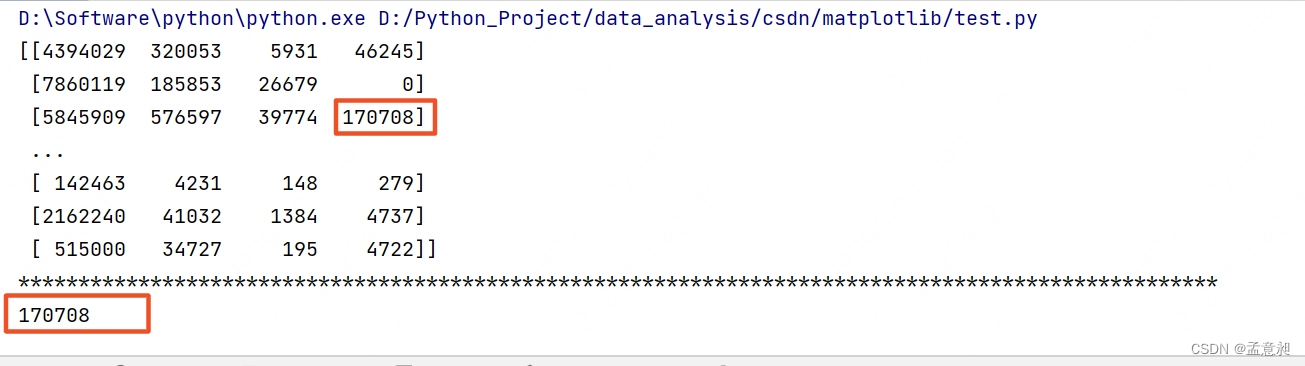
简单来说,就是逗号前的内容用来取行,逗号后的内容用来取列
3. numpy进行数据修改
3.1 numpy对指定数据进行修改
根据上面的内容,我们可以获取文件中指定的行列数值,同时也可以对其进行修改,t1[2,3]的值本来是170708,对其赋值后再进行获取,就会变成修改后的数据
import numpy as np
#数据源的路径
us_file_path = r"D:\Python_Project\data_analysis\csdn\matplotlib\data\US_video_data_numbers.csv"
t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int")
t2 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
#print(t1)
#print("*"*100)
#取第三行 第四列的值
print(t1[2,3])
#数值修改
t1[2,3] = 0
print(t1[2,3])



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











