






 本文介绍了如何利用Scrapy框架结合Ajax技术爬取腾讯招聘网站上的Python职位信息,并将数据存储到MongoDB数据库。通过分析网络请求,找到数据源URL,设置Scrapy的配置,包括日志等级、robots.txt协议、User-Agent及启用管道,最终成功抓取并存储了5页职位数据。
本文介绍了如何利用Scrapy框架结合Ajax技术爬取腾讯招聘网站上的Python职位信息,并将数据存储到MongoDB数据库。通过分析网络请求,找到数据源URL,设置Scrapy的配置,包括日志等级、robots.txt协议、User-Agent及启用管道,最终成功抓取并存储了5页职位数据。
本次爬取网站的链接:https://careers.tencent.com/
第一步:
在搜索框输入我们想要爬取职位的关键信息 如python c/c++ 点击搜索

第二步:
来到相关职位信息的页面

第三步:
在页面任何地方点击右键,再点击检查 然后点击network 会出现如下页面

点击刷新后 如图

点击新出现内容的第二行 进入如下页面

我们想要的数据就在Data里 然后点击Headers找到我们需要的url如图

图片中Request URL对应的我们要找的url ,对这个url发送请求就能得到我们这个页面里的数据然后进行解析就可以了,我这次以爬取5页为例,你们若想爬取全站修改一下参数就可以了
Scrapy代码:
import scrapy
import json
import time
class QiushiSpider(scrapy.Spider):
name = 'qiushi'
# allowed_domains = ['www.xxx.com']
start_urls = []
for i in range(1,6): #在这里修改参数(想要爬取的页数)
url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1620526940655&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=python&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
new_url = url.format(i)
# print(url)
start_urls.append(new_url)
time.sleep(2) # 爬取不要太频繁防止封ip
def parse(self, response):
print(response.url)
html = json.loads(response.text)
data = html['Data']
if data:
for it in data['Posts']:
RecruitPostName = it['RecruitPostName']
Responsibility = it['Responsibility']
item = {}
item['RecruitPostName'] = RecruitPostName
item['Responsibility'] = Responsibility
yield item
pipelines.py中的代码实现
from itemadapter import ItemAdapter
import pymongo
client = pymongo.MongoClient(host='127.0.0.1', port=27017) # 连接mongoDB数据库
db = client.zhanpin #使用zhanpin数据库
collection = db.tengxun # 使用腾讯集合
class SpiderproPipeline:
def process_item(self, item, spider):
#print(item)
collection.insert(item) # 保存到mongoDB数据库
return item
settings.py中的文件配置
1、添加日志的等级为ERROR

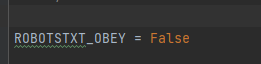
2、机器人协议改为False
3、添加User-Agent

4、开启管道

打开mongoDB可视化工具可看到存储的数据



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









