







Elasticsearch
一)ES的基本介绍
1. Elasticsearch 是什么
Elaticsearch,简称为 ES,ES 是一个开源的高扩展的分布式全文搜索引擎,是整个 Elastic Stack 技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。

The Elastic Stack, 包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
2. Eelasticsearch的作用
Elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容。
- 在GitHub搜索代码
- 用于搜索引擎中搜索内容
- 各大电商网站搜索商品
- 打车软件搜索附近的车辆
3. Elasticsearch,Solr和Lucene三者之间的关系
目前市面上流行的搜索引擎软件,主流的就两款:Elasticsearch 和 Solr,这两款都是基于 Lucene 搭建的,可以独立部署启动的搜索引擎服务软件。
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
Elasticsearch和Solr对比
| 特征 | Solr/SolrCloud | Elasticsearch |
|---|---|---|
| 社区和开发者 | Apache软件基金和社区支持 | 单一商业实体及其员工 |
| 节点发现 | Apache Zookeeper.在大量项目中成熟且经过实战测试 | Zen内置于Elasticsearch本身,需要专用的主节点才能进行裂脑保护 |
| 碎片放置 | 本质上是静态,需要手动工作来迁移分片,从Solr 7开始- AutoscalingAPI允许一些动态操作 | 动态,可以根据群集状态按需移动分片 |
| 高速缓存 | 全局,每个段更改无效 | 每段,更适合动态更改数据 |
| 分析引擎性能 | 非常适合精确计算的静态数据 | 结果的准确性取决于数据放置 |
| 全文搜索功能 | 基于Lucene的语言分析,多建议,拼写检查,丰富的高亮显示支持 | 基于Lucene的语言分析,单一建议API实现, 高亮显示重新计算 |
| DevOps支持 | 尚未完全,但即将到来 | 非常好的API |
| 非平面数据处理 | 嵌套文档和父子支持 | 嵌套和对象类型的自然支持允许几乎无限的嵌套和父-子支持 |
| 查询DSL | JSON (有限),XML (有限)或URL参数 | JSON |
| 机器学习 | 内置-在流聚合之上,专注于逻辑回归和学习排名贡献模块 | 商业功能,专注于异常和异常值以及时间序列数据 |
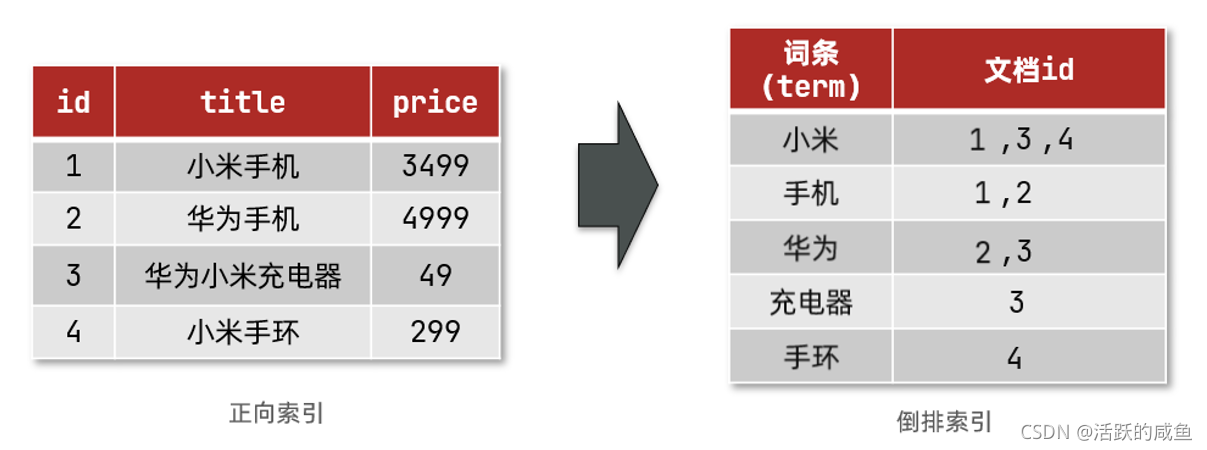
4. Elasticsearch的索引结构–倒排索引
倒排索引的概念是基于MySQL这样的正向索引而言的。
正向索引
那么什么是正向索引呢?例如给下表(tb_goods)中的id创建索引:

如果是根据id查询,那么直接走索引,查询速度非常快。
但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难。
倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息。 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
如图:
倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
如图:
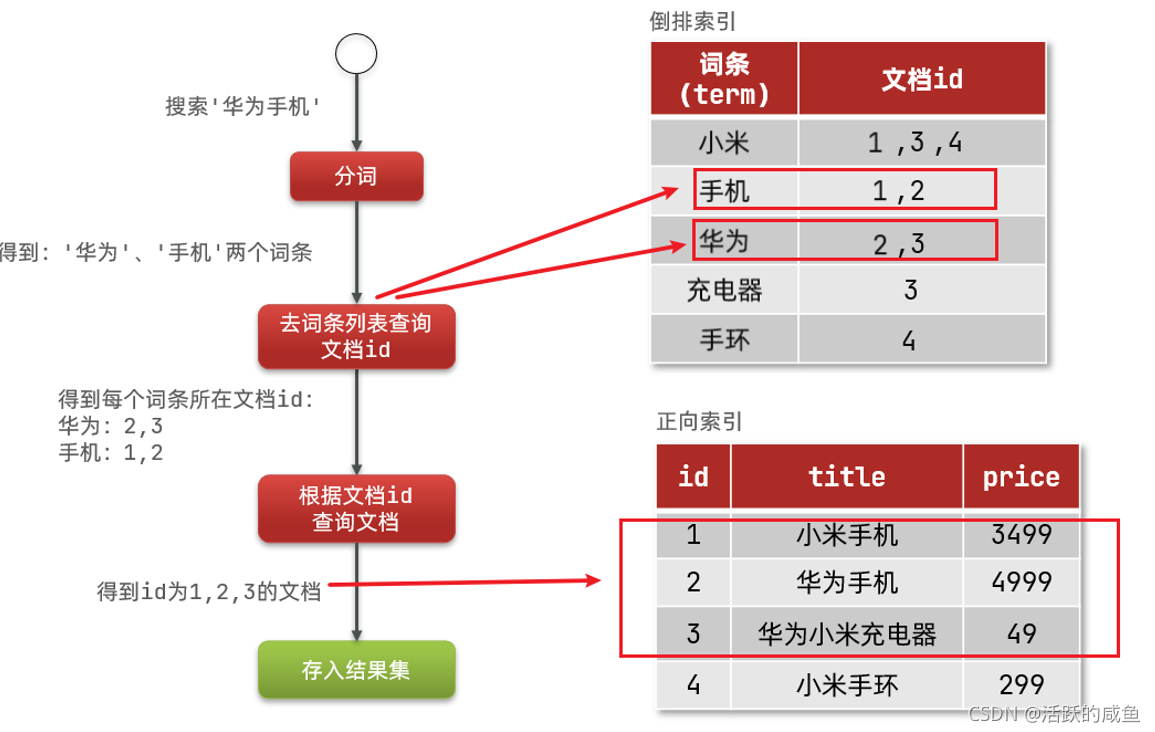
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
正向索引和倒排索引比较
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
5. ES中的一些基本概念
elasticsearch中有很多独有的概念,与mysql中略有差别,但也有相似之处。
文档和字段
elasticsearch是面向文档(Document) 存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4JWzZNSz-1633240596343)(assets/image-20210720202707797.png)]](https://i-blog.csdnimg.cn/blog_migrate/a2d7dc47301f034209ca4d8d6aa77ccb.png)
而Json文档中往往包含很多的字段(Field),类似于数据库中的列。
索引和映射
索引(Index),就是相同类型的文档的集合。
例如:
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;

因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
mysql与elasticsearch
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长支出:
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
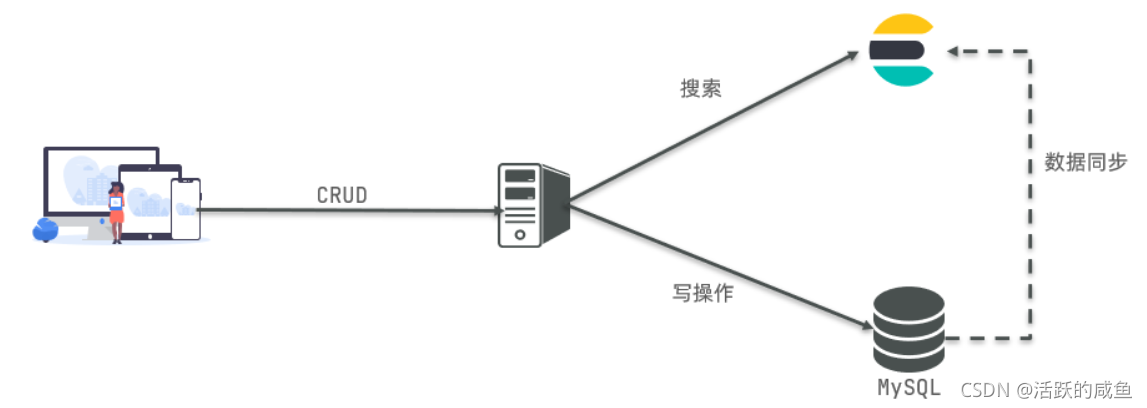
二)ES索引的增删改查
索引库就类似数据库表,mapping映射就类似表的结构。我们要向es中存储数据,必须先创建“库”和“表”。
1. mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- store:是否将数据进行独立存储,默认为 false
原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置"store": true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。 - properties:该字段的子字段
2. 索引库的创建
基本语法:
- 请求方式:PUT
- 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
格式:
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
示例:
PUT /xianyu
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": "falsae"
},
"name":{
"properties": {
"firstName": {
"type": "keyword"
}
}
},
// ... 略
}
}
}
RestAPI:
//1.创建请求
CreateIndexRequest request=new CreateIndexRequest("hotel");
//2.准备请求参数
request.source(HotelConstants.MAPPING_TEMPLATE, XContentType.JSON);
//3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);
3. 查询索引库
基本语法:
-
请求方式:GET
-
请求路径:/索引库名
-
请求参数:无
格式:
GET /索引库名
示例:
GET /xianyu
{
"xianyu"【索引名】: {
"aliases"【别名】: {},
"mappings"【映射】: {},
"settings"【设置】: {
"index"【设置 - 索引】: {
"creation_date"【设置 - 索引 - 创建时间】: "1614265373911",
"number_of_shards"【设置 - 索引 - 主分片数量】: "1",
"number_of_replicas"【设置 - 索引 - 副分片数量】: "1",
"uuid"【设置 - 索引 - 唯一标识】: "eI5wemRERTumxGCc1bAk2A",
"version"【设置 - 索引 - 版本】: {
"created": "7080099"
},
"provided_name"【设置 - 索引 - 名称】: "xianyu"
}
}
}
}
查询所有的索引库
#查询所有的索引库
GET /_cat/indices?v

| 表头 | 含义 |
|---|---|
| health 当前服务器健康状态: | green(集群完整) yellow(单点正常、集群不完整)red(单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
RestAPI
// 查询索引 - 请求对象
GetIndexRequest request = new GetIndexRequest("hotel");
// 发送请求,获取响应
GetIndexResponse response = client.indices().get(request,
RequestOptions.DEFAULT);
4. 修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
语法说明:
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
5. 删除索引库
语法:
-
请求方式:DELETE
-
请求路径:/索引库名
-
请求参数:无
格式:
DELETE /索引库名
RestAPI:
//创建删除请求
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
//发送请求
client.indices().delete(request,RequestOptions.DEFAULT);
三)ES文档的增删改查
1. 创建文档
语法:
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
示例:
POST /xianyu/_doc/1 不加id会随机生成一个id
{
"name":"咸鱼",
"age":23
}
{
"_index" : "xianyu", //索引名
"_type" : "_doc", //类型
"_id" : "1", //唯一标识 类似主键
"_version" : 1, //版本
"result" : "created", //结果 表示创建成功
"_shards" : { //分片
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
RESTAPI
// 1.根据id查询酒店数据
Hotel hotel = hotelService.getById(61083L);
// 2.转换为文档类型
HotelDoc hotelDoc = new HotelDoc(hotel);
// 3.将HotelDoc转json
String jsonString = JSON.toJSONString(hotelDoc);
// 1.准备Request对象
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 2.准备Json文档
request.source(jsonString, XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
2. 查询文档
语法:
GET /{索引库名称}/_doc/{id}
GET /xianyu/_doc/1
{
"_index" : "xianyu",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "咸鱼",
"age" : 23
}
}
RESTAPI
GetRequest request = new GetRequest("hotel","61083");
//得到响应
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String json = response.getSourceAsString();
//解析文档
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
3. 删除文档
语法:
DELETE /{索引库名称}/_doc/{id}
DELETE /xianyu/_doc/1
{
"_index" : "xianyu",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
条件删除文档
POST /xianyu/_delete_by_query
{
"query":{
"match":{
"age":23
}
}
}
RESTAPI
// 1.准备Request
DeleteRequest request = new DeleteRequest("hotel", "61083");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
4. 修改文档
修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 增量修改:修改文档中的部分字段
语法:
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
增量修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
POST /xianyu/_update/1
{
"doc": {
"no":"20183033523"
}
}
{
"_index" : "xianyu",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
RESTAPI
// 1.准备Request
UpdateRequest request = new UpdateRequest("hotel", "61083");
// 2.准备请求参数
request.doc(
"price", "952",
"starName", "四钻"
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
四)ES的高级查询
1. DSL查询分类
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
-
查询所有:查询出所有数据,一般测试用。例如:match_all
-
全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
- match_query
- multi_match_query
-
精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
- ids
- range
- term
-
地理(geo)查询:根据经纬度查询。例如:
- geo_distance
- geo_bounding_box
-
复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
- bool
- function_score
查询基本语法:
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
2. 查询所有文档
// 查询所有
GET /indexName/_search
{
"query": {
"match_all": {
}
}
}

RestAPI
//1.创建请求
SearchRequest request = new SearchRequest("hotel");
//2.构建DSL
request.source().query(QueryBuilders.matchAllQuery());
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
extractResponse(response);
结果解析:
//将响应结果解析
private void extractResponse(SearchResponse response) {
SearchHits searchHits = response.getHits();
//获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("文档总条数为"+total);
//获取文档数组
SearchHit[] hits = searchHits.getHits();
// Arrays.stream(hits).forEach(v-> JSON.parseObject(v.getSourceAsString(),HotelDoc.class));
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
log.info("酒店数据:{}",hotelDoc);
}
}
3. 全文检索查询
使用场景
全文检索查询的基本流程如下:
- 对用户搜索的内容做分词,得到词条
- 根据词条去倒排索引库中匹配,得到文档id
- 根据文档id找到文档,返回给用户
比较常用的场景包括:
- 商城的输入框搜索
- 百度输入框搜索
因为是拿着词条去匹配,因此参与搜索的字段也必须是可分词的text类型的字段。
基本语法
常见的全文检索查询包括:
- match查询:单字段查询
- multi_match查询:多字段查询,任意一个字段符合条件就算符合查询条件,搜索字段越多,对查询性能影响越大,因此建议采用copy_to,然后单字段查询的方式。
match查询语法如下:
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}
#匹配查询
GET /hotel/_search
{
"query": {
"match": {
"city": "上海"
}
}
}
RestAPI
//创建请求
SearchRequest request = new SearchRequest("hotel");
//2.构建DSL
request.source().query(QueryBuilders.matchQuery("city","上海"));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
extractResponse(response);
mulit_match语法如下:
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1", " FIELD12"]
}
}
}
#多字段匹配查询
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "汉庭",
"fields": ["name","business"]
}
}
}
RestAPI
//1.创建请求
SearchRequest request = new SearchRequest("hotel");
//2.构建DSL
request.source().query(QueryBuilders.multiMatchQuery("汉庭","name","business"));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
extractResponse(response);
4. 关键字精确查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
- term:根据词条精确值查询
- range:根据值的范围查询
- terms:根据多个词条精确查询
term查询
因为精确查询的字段搜是不分词的字段,因此查询的条件也必须是不分词的词条。查询时,用户输入的内容跟自动值完全匹配时才认为符合条件。如果用户输入的内容过多,反而搜索不到数据。
语法说明:
// term查询
GET /indexName/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}
#精确查询
GET /hotel/_search
{
"query": {
"term": {
"brand": {
"value": "汉庭"
}
}
}
}
RestAPI
//1.创建请求
SearchRequest request = new SearchRequest("hotel");
//2.构建DSL
request.source().query(QueryBuilders.termQuery("city","上海"));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
extractResponse(response);
range查询
范围查询,一般应用在对数值类型做范围过滤的时候。比如做价格范围过滤。

基本语法:
// range查询
GET /indexName/_search
{
"query": {
"range": {
"FIELD": {
"gte": 10, // 这里的gte代表大于等于,gt则代表大于
"lte": 20 // lte代表小于等于,lt则代表小于
}
}
}
}
#范围查询
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 300,
"lte": 400
}
}
}
}
RestAPI
//1.创建请求
SearchRequest request = new SearchRequest("hotel");
//2.构建DSL
request.source().query(QueryBuilders.rangeQuery("price").gt(200).lt(400));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
extractResponse(response);
terms查询
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件,类似于 mysql 的 in。
// term查询
GET /indexName/_search
{
"query": {
"term": {
"FIELD": {
"value": ["VALUE1","VALUE2"]
}
}
}
}
GET /hotel/_search
{
"query": {
"terms": {
"city": [
"上海",
"北京"
]
}
}
}
RestAPI
//1.创建请求
SearchRequest request = new SearchRequest("hotel");
//2.构建DSL
request.source().query(QueryBuilders.termsQuery("city","北京","上海"));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
extractResponse(response);
5. 指定查询字段
默认情况下,Elasticsearch 在搜索的结果中,会把文档中保存在_source 的所有字段都返回。如果我们只想获取其中的部分字段,我们可以添加_source 的过滤。
#指定筛选字段
GET /hotel/_search
{
"_source": ["address","city"] ,
"query": {
"term": {
"city": {
"value": "上海"
}
}
}
}
- includes:来指定想要显示的字段
- excludes:来指定不想要显示的字段
GET /hotel/_search
{
"_source": {
//"excludes": , ["address","city"],
"includes": ["brand","price"]
},
"query": {
"term": {
"city": {
"value": "上海"
}
}
}
}
RestAPI
//1.创建请求
SearchRequest request = new SearchRequest("hotel");
//查询字段过滤
String[] includes={};
String[] excludes={"brand","location"};
//2.构建DSL
request.source().query(QueryBuilders.termQuery("city","上海")).fetchSource(includes,excludes);
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
extractResponse(response);
6. 地理坐标查询
所谓的地理坐标查询,其实就是根据经纬度查询。
常见的使用场景包括:
- 携程:搜索我附近的酒店
- 滴滴:搜索我附近的出租车
- 微信:搜索我附近的人
矩形范围查询
矩形范围查询,也就是geo_bounding_box查询,查询坐标落在某个矩形范围的所有文档:
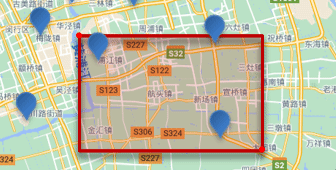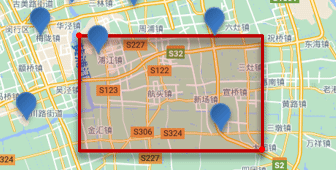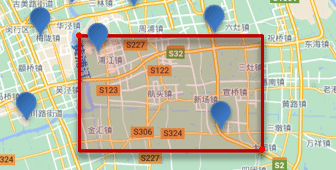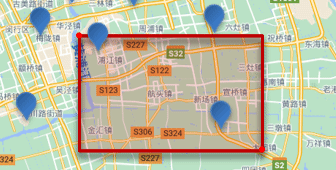
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
语法如下:
// geo_bounding_box查询
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": { // 左上点
"lat": 31.1,
"lon": 121.5
},
"bottom_right": { // 右下点
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
附近查询
附近查询,也叫做距离查询(geo_distance):查询到指定中心点小于某个距离值的所有文档。
换句话来说,在地图上找一个点作为圆心,以指定距离为半径,画一个圆,落在圆内的坐标都算符合条件:
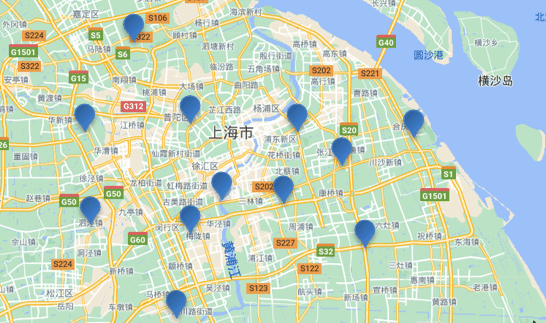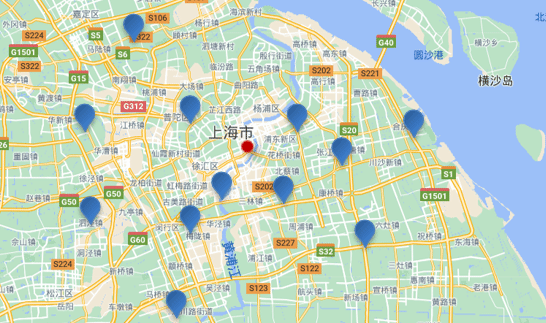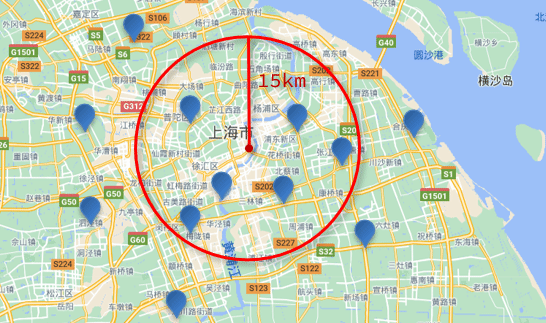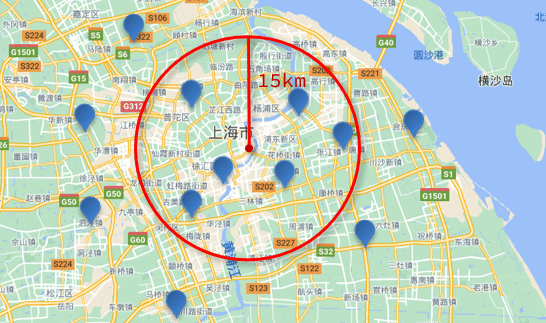
语法说明:
// geo_distance 查询
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km", // 半径
"FIELD": "31.21,121.5" // 圆心
}
}
}
#地理坐标查询 半径5km范围内的
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance": "5km",
"location": "31.21,121.5"
}
}
}
RestAPI
//1.创建请求
SearchRequest request = new SearchRequest("hotel");
//2.构建DSL
request.source().query(QueryBuilders
.geoDistanceQuery("location")
.distance("5", DistanceUnit.KILOMETERS)
.point(31.21,121.5));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
extractResponse(response);
7. 算分函数查询
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。常见的有两种:
- fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名
- bool query:布尔查询,利用逻辑关系组合多个其它的查询,实现复杂搜索
相关性算分
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
例如,我们搜索 “虹桥如家”,结果如下:
[
{
"_score" : 17.850193,
"_source" : {
"name" : "虹桥如家酒店真不错",
}
},
{
"_score" : 12.259849,
"_source" : {
"name" : "外滩如家酒店真不错",
}
},
{
"_score" : 11.91091,
"_source" : {
"name" : "迪士尼如家酒店真不错",
}
}
]
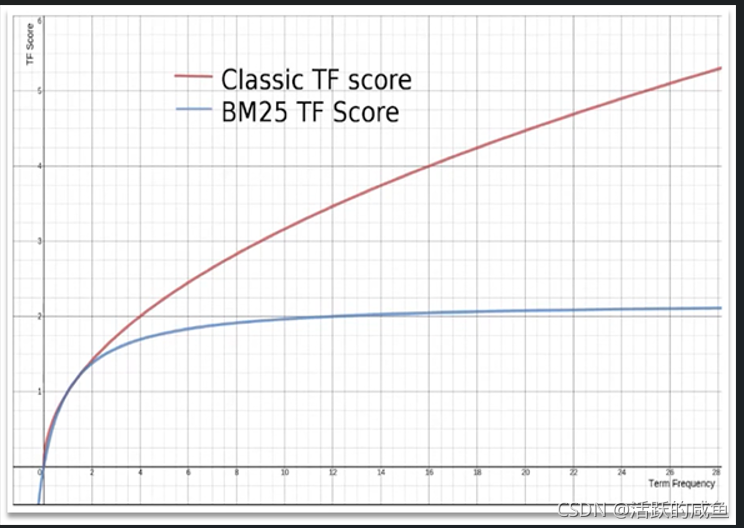
在elasticsearch中,早期使用的打分算法是TF-IDF算法,公式如下:

在后来的5.1版本升级中,elasticsearch将算法改进为BM25算法,公式如下:

TF-IDF算法有一各缺陷,就是词条频率越高,文档得分也会越高,单个词条对文档影响较大。而BM25则会让单个词条的算分有一个上限,曲线更加平滑:
算分函数查询
根据相关度打分是比较合理的需求,但合理的不一定是产品经理需要的。
以百度为例,你搜索的结果中,并不是相关度越高排名越靠前,而是谁掏的钱多排名就越靠前。
要想认为控制相关性算分,就需要利用elasticsearch中的function score 查询了。
1)语法说明
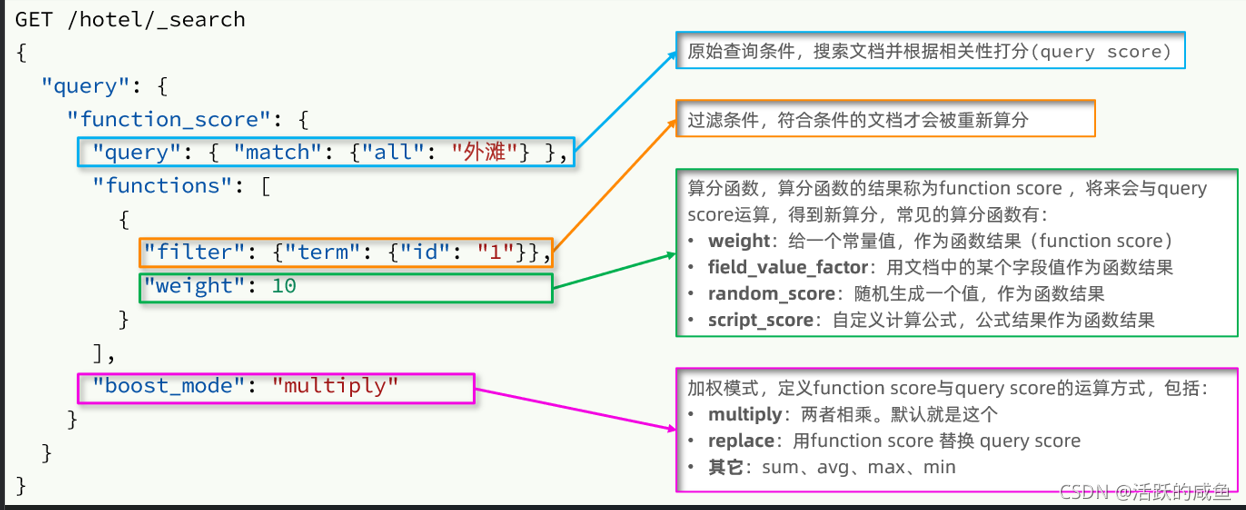
function score 查询中包含四部分内容:
- 原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
- 过滤条件:filter部分,符合该条件的文档才会重新算分
- 算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
- 运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
- multiply:相乘
- replace:用function score替换query score
- 其它,例如:sum、avg、max、min
function score的运行流程如下:
- 1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
- 2)根据过滤条件,过滤文档
- 3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
- 4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
因此,其中的关键点是:
- 过滤条件:决定哪些文档的算分被修改
- 算分函数:决定函数算分的算法
- 运算模式:决定最终算分结果
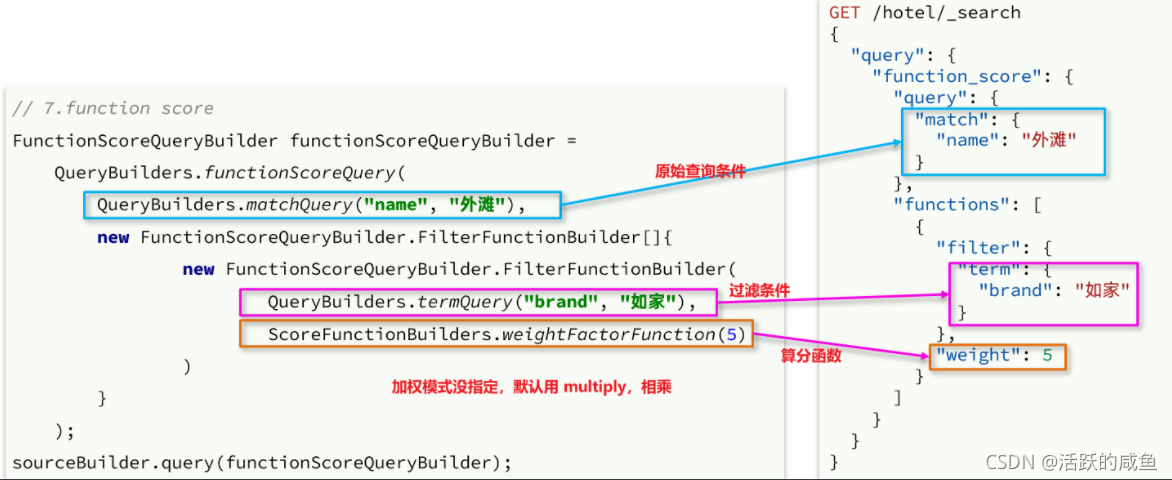
GET /hotel/_search
{
"query": {
"function_score": {
"query": { .... }, // 原始查询,可以是任意条件
"functions": [ // 算分函数
{
"filter": { // 满足的条件,品牌必须是如家
"term": {
"brand": "如家"
}
},
"weight": 2 // 算分权重为2
}
],
"boost_mode": "sum" // 加权模式,求和
}
}
}
RestAPI
8. 模糊查询
返回包含与搜索字词相似的字词的文档。
GET /hotel/_search
{
"query": {
"fuzzy": {
"name": {
"value": "酒店",
"fuzziness": 0.8
}
}
}
}
RestAPI
//1.创建请求
SearchRequest request = new SearchRequest("hotel");
//2.构建DSL
request.source().query(QueryBuilders.fuzzyQuery("name","酒店").fuzziness(Fuzziness.AUTO));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
extractResponse(response);
9. 复合查询
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
比如在搜索酒店时,除了关键字搜索外,我们还可能根据品牌、价格、城市等字段做过滤:
每一个不同的字段,其查询的条件、方式都不一样,必须是多个不同的查询,而要组合这些查询,就必须用bool查询了。
需要注意的是,搜索时,参与打分的字段越多,查询的性能也越差。因此这种多条件查询时,建议这样做:
- 搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
- 其它过滤条件,采用filter查询。不参与算分
语法所示:
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{"term": {"city": "上海" }}
],
"should": [
{"term": {"brand": "皇冠假日" }},
{"term": {"brand": "华美达" }}
],
"must_not": [
{ "range": { "price": { "lte": 500 } }}
],
"filter": [
{ "range": {"score": { "gte": 45 } }}
]
}
}
}
RestAPI
SearchRequest request = new SearchRequest("hotel");
// 2.1.准备BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.filter(QueryBuilders.rangeQuery("score").gte(45));
boolQuery.must(QueryBuilders.termQuery("city","上海"));
boolQuery.should(QueryBuilders.termQuery("brand","华美达"));
boolQuery.should(QueryBuilders.termQuery("brand","皇冠假日"));
boolQuery.mustNot(QueryBuilders.rangeQuery("price").lte(500));
request.source().query(boolQuery);
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//解析结果
extractResponse(response);
2)示例
需求:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
分析:
- 名称搜索,属于全文检索查询,应该参与算分。放到must中
- 价格不高于400,用range查询,属于过滤条件,不参与算分。放到must_not中
- 周围10km范围内,用geo_distance查询,属于过滤条件,不参与算分。放到filter中
#复合查询
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"brand": {
"value": "如家"
}
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 400
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}
}
]
}
}
}
RestAPI
SearchRequest request = new SearchRequest("hotel");
// 2.1.准备BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.filter(QueryBuilders
.geoDistanceQuery("location")
.distance(10,DistanceUnit.KILOMETERS)
.point(31.21,121.5));
boolQuery.must(QueryBuilders.termQuery("brand","如家"));
boolQuery.mustNot(QueryBuilders.rangeQuery("price").gt(500));
request.source().query(boolQuery);
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//解析结果
extractResponse(response);
10. 排序
elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
1.普通单字段排序
keyword、数值、日期类型排序的语法基本一致。
{
"query": {
...条件
},
"sort": [{
"FIELD": {
"order":"desc"
}
}]
}
2.普通多字段排序
GET /hotel/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"price": {
"order": "asc"
},
"score": {
"order": "asc"
}
}
]
}
RestAPI
//1.创建请求
SearchRequest request = new SearchRequest("hotel");
//2.构建DSL
request.source()
.query(QueryBuilders.matchAllQuery())
.sort("price",SortOrder.ASC)
.sort("score",SortOrder.ASC);
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
extractResponse(response);
3.地理坐标排序
语法说明:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance" : {
"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点
"order" : "asc", // 排序方式
"unit" : "km" // 排序的距离单位
}
}
]
}
这个查询的含义是:
- 指定一个坐标,作为目标点
- 计算每一个文档中,指定字段(必须是geo_point类型)的坐标 到目标点的距离是多少
- 根据距离排序
示例: 需求描述:实现对酒店数据按照到你的位置坐标的距离升序排序
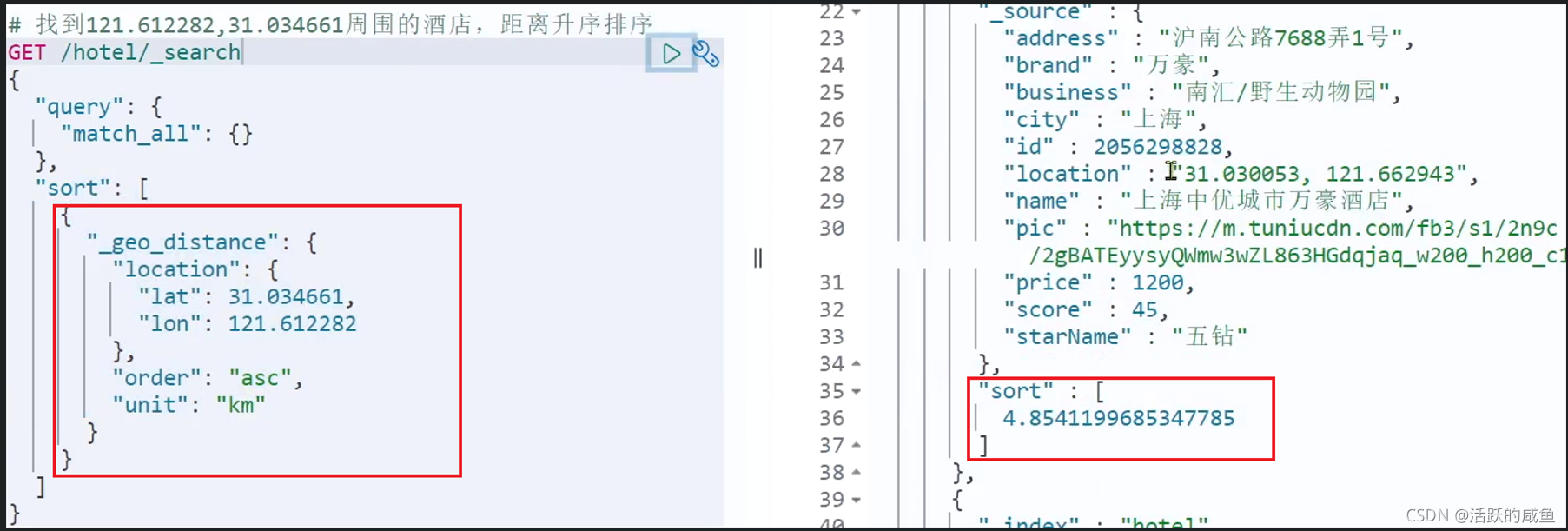
RestAPI
//1.创建请求
SearchRequest request = new SearchRequest("hotel");
//2.构建DSL
request.source()
.query(QueryBuilders.matchAllQuery())
.sort(SortBuilders
.geoDistanceSort("location",31.5,121.5)
.order(SortOrder.ASC)
.unit(DistanceUnit.KILOMETERS));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应
extractResponse(response);
11. 分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始,默认从 0 开始。 from = (pageNum - 1) * size
- size:总共查询几个文档
类似于mysql中的limit ?, ?
基本分页语法:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
RestAPI
//创建请求
SearchRequest request = new SearchRequest("hotel");
//构建DSL
request.source().query(QueryBuilders
.matchAllQuery())
.sort("price",SortOrder.ASC)
.from(0)
.size(10);
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//解析响应
extractResponse(response);
深度分页问题
现在,我要查询990~1000的数据,查询逻辑要这么写:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 990, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
这里是查询990开始的数据,也就是 第990~第1000条 数据。
不过,elasticsearch内部分页时,必须先查询 0~1000条,然后截取其中的990 ~ 1000的这10条:

查询TOP1000,如果es是单点模式,这并无太大影响。
但是elasticsearch将来一定是集群,例如我集群有5个节点,我要查询TOP1000的数据,并不是每个节点查询200条就可以了。
因为节点A的TOP200,在另一个节点可能排到10000名以外了。
因此要想获取整个集群的TOP1000,必须先查询出每个节点的TOP1000,汇总结果后,重新排名,重新截取TOP1000。
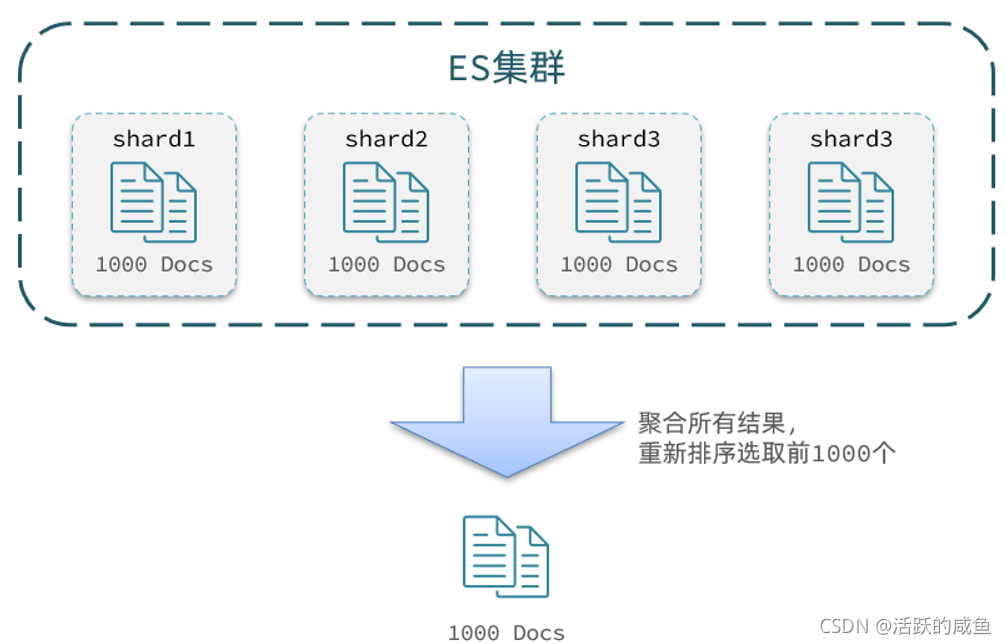
当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,因此elasticsearch会禁止from+ size 超过10000的请求。
针对深度分页,ES提供了两种解决方案,官方文档:
- search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
- scroll:原理将排序后的文档id形成快照,保存在内存。官方已经不推荐使用。
分页查询的常见实现方案以及优缺点:
-
from + size:- 优点:支持随机翻页
- 缺点:深度分页问题,默认查询上限(from + size)是10000
- 场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
-
after search:- 优点:没有查询上限(单次查询的size不超过10000)
- 缺点:只能向后逐页查询,不支持随机翻页
- 场景:没有随机翻页需求的搜索,例如手机向下滚动翻页
-
scroll:- 优点:没有查询上限(单次查询的size不超过10000)
- 缺点:会有额外内存消耗,并且搜索结果是非实时的
- 场景:海量数据的获取和迁移。从ES7.1开始不推荐,建议用 after search方案。
12. 高亮查询
高亮原理
什么是高亮显示呢?
我们在百度,京东搜索时,关键字会变成红色,比较醒目,这叫高亮显示:
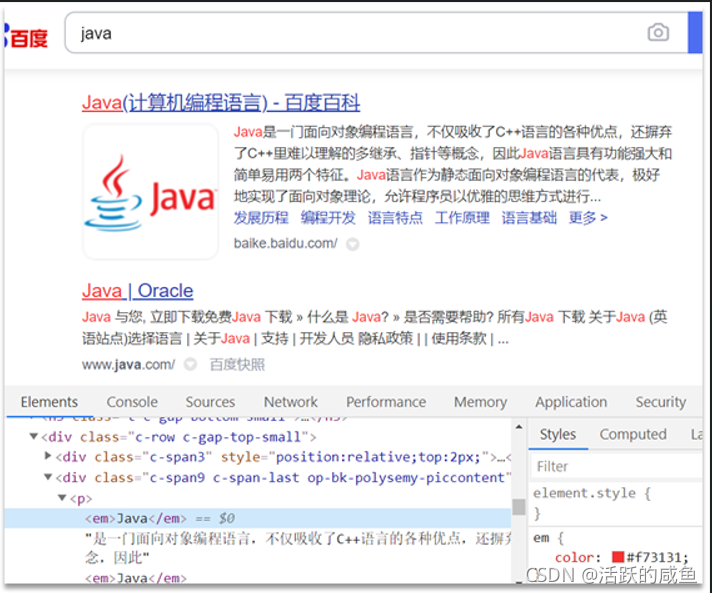
高亮显示的实现分为两步:
- 1)给文档中的所有关键字都添加一个标签,例如
<em>标签 - 2)页面给
<em>标签编写CSS样式
实现高亮
高亮的语法:
GET /hotel/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": {
"pre_tags": "<em>", // 用来标记高亮字段的前置标签
"post_tags": "</em>" // 用来标记高亮字段的后置标签
}
}
}
}
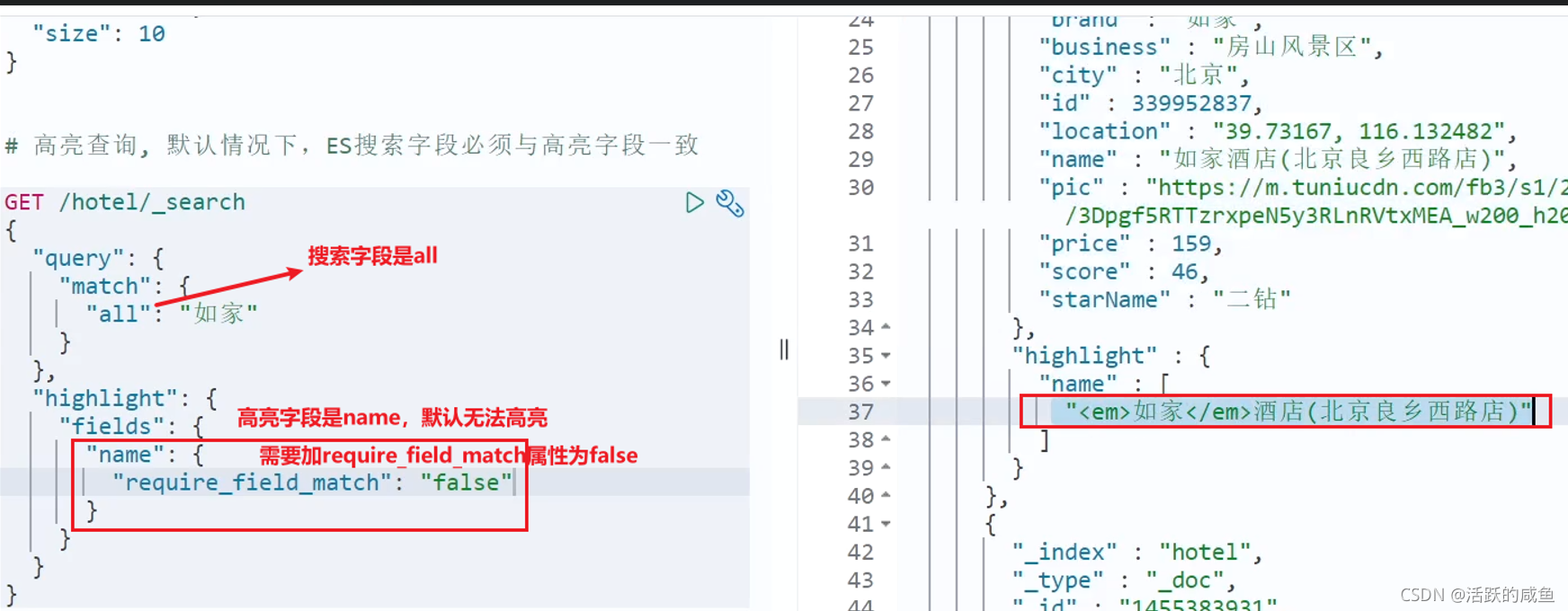
注意:
- 高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
- 默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
- 如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
ResAPI
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchQuery("all", "如家"));
// 2.2.高亮
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// 获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(highlightFields)) {
// 根据字段名获取高亮结果
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null) {
// 获取高亮值
String name = highlightField.getFragments()[0].string();
// 覆盖非高亮结果
hotelDoc.setName(name);
}
}
System.out.println("hotelDoc = " + hotelDoc);
}
13. 聚合查询
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
聚合的种类
聚合常见的有三类:
-
桶(Bucket)聚合:用来对文档做分组
-
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
-
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
-
管道(pipeline)聚合:其它聚合的结果为基础做聚合
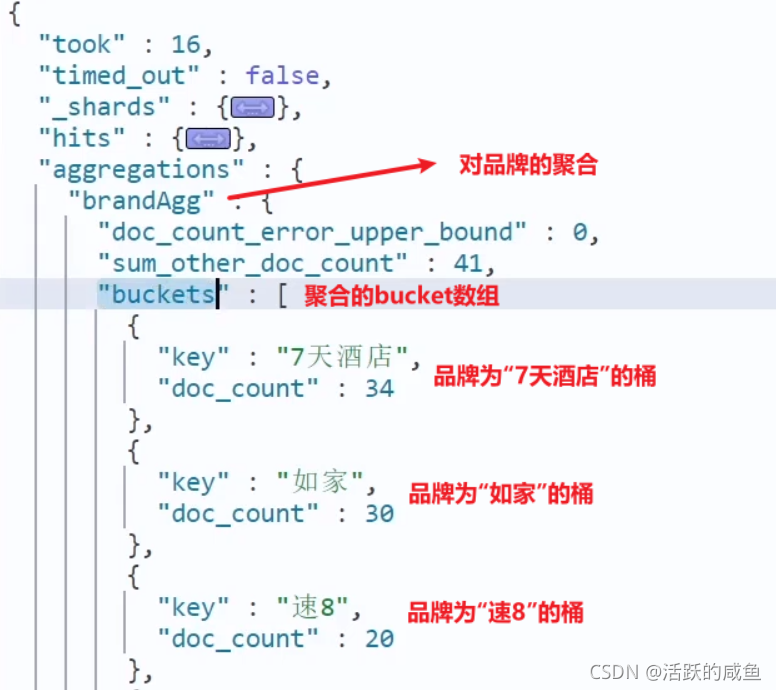
Bucket聚合语法如下:
GET /hotel/_search
{
"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果
"aggs": { // 定义聚合
"brandAgg": { //给聚合起个名字
"terms": { // 聚合的类型,按照品牌值聚合,所以选择term
"field": "brand", // 参与聚合的字段
"size": 20 // 希望获取的聚合结果数量
}
}
}
}
结果:
RestAPI
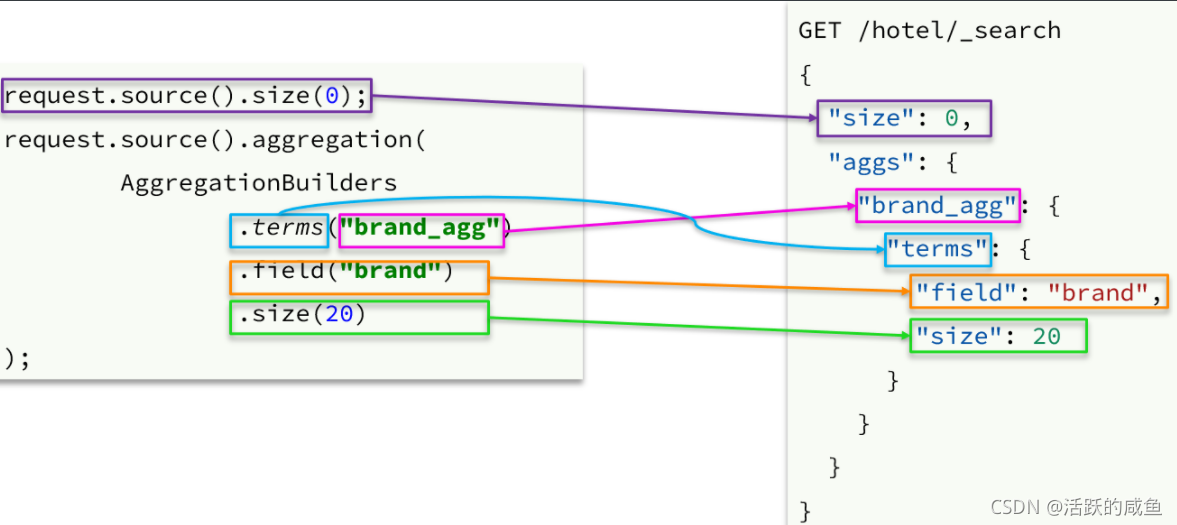
//创建请求
SearchRequest request = new SearchRequest("hotel");
//创建DSL
request.source().aggregation(AggregationBuilders
.terms("brand_agg")
.field("brand")
.size(20)).size(0);
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
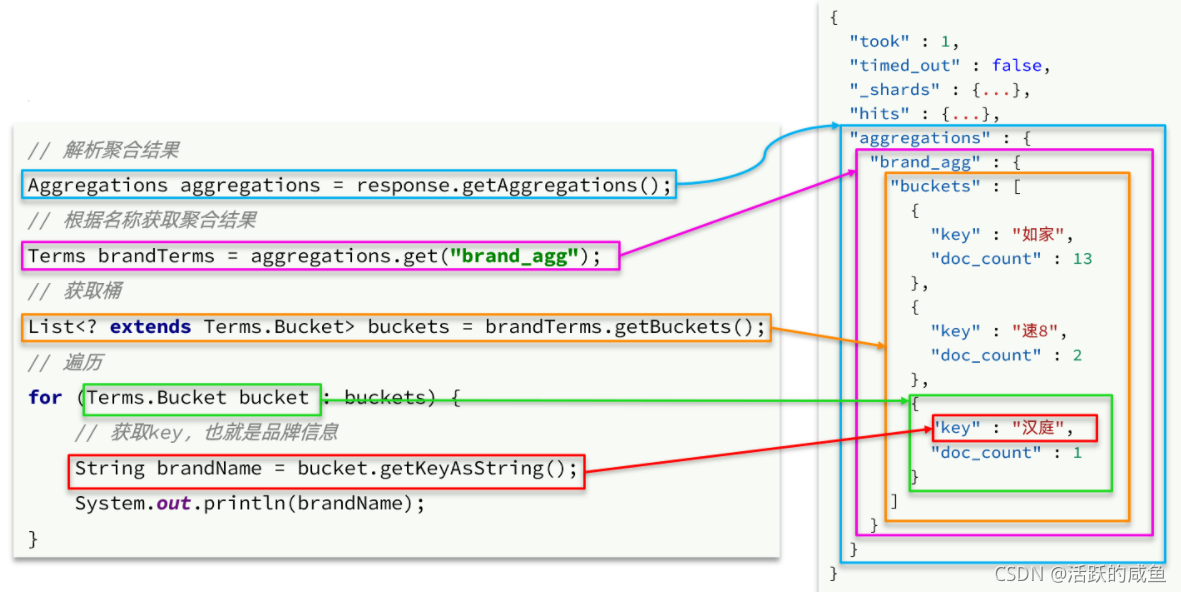
//解析响应
Aggregations aggregations = response.getAggregations();
//根据名称获取结果
Terms brand_agg = aggregations.get("brand_agg");
//拿到桶
List<? extends Terms.Bucket> buckets = brand_agg.getBuckets();
//遍历桶
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString());
}
聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
我们可以指定order属性,自定义聚合的排序方式:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"order": {
"_count": "asc" // 按照_count升序排列
},
"size": 20
}
}
}
}
SearchRequest request = new SearchRequest("hotel");
//创建DSL
request.source().aggregation(AggregationBuilders
.terms("brand_agg")
.field("brand")
.size(20)).size(0)
.sort("_count",SortOrder.ASC);
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
我们可以限定要聚合的文档范围,只要添加query条件即可:
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 200 // 只对200元以下的文档聚合
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
RestAPI
//创建请求
SearchRequest request = new SearchRequest("hotel");
//创建DSL
request.source().query(QueryBuilders.rangeQuery("price").lte(200));
request.source()
.aggregation(AggregationBuilders
.terms("brand_agg")
.field("brand")
.size(20)).size(0);
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//解析响应
Aggregations aggregations = response.getAggregations();
//根据名称获取结果
Terms brand_agg = aggregations.get("brand_agg");
//拿到桶
List<? extends Terms.Bucket> buckets = brand_agg.getBuckets();
//遍历桶
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString());
}
Metric聚合语法
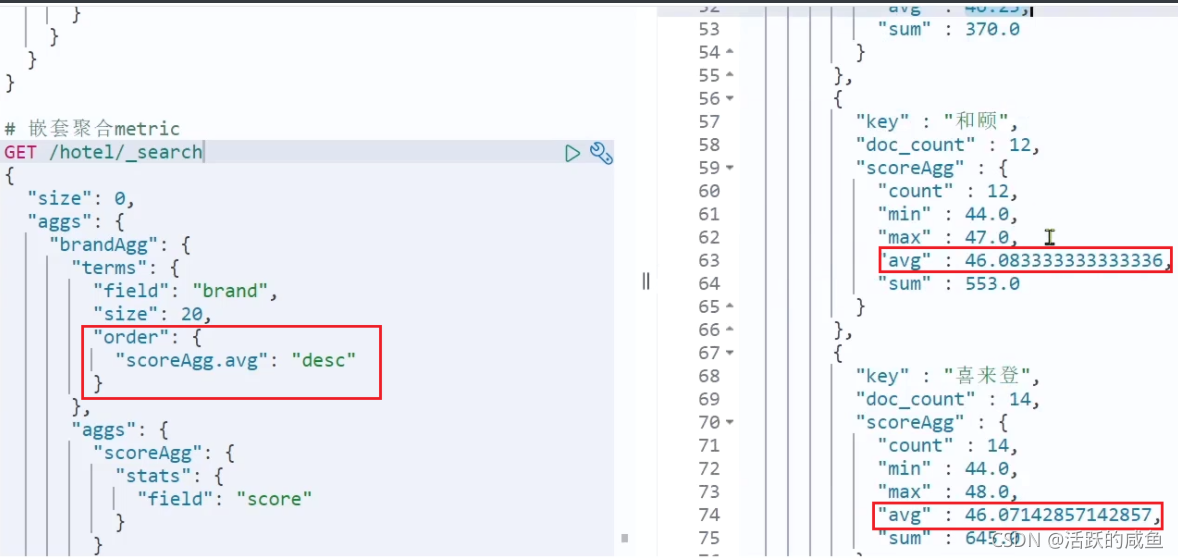
我们对酒店按照品牌分组,形成了一个个桶。现在我们需要对桶内的酒店做运算,获取每个品牌的用户评分的min、max、avg等值。
这就要用到Metric聚合了,例如stat聚合:就可以获取min、max、avg等结果。
语法如下:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
},
"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算
"score_stats": { // 聚合名称
"stats": { // 聚合类型,这里stats可以计算min、max、avg等
"field": "score" // 聚合字段,这里是score
}
}
}
}
}
}
这次的score_stats聚合是在brandAgg的聚合内部嵌套的子聚合。因为我们需要在每个桶分别计算。
另外,我们还可以给聚合结果做个排序,例如按照每个桶的酒店平均分做排序:
RestAPI
//创建请求
SearchRequest request = new SearchRequest("hotel");
//创建DSL
request.source().aggregation(AggregationBuilders
.terms("brand_agg")
.field("brand")
.subAggregation(AggregationBuilders.stats("score_stats").field("score"))
.size(20))
.size(0);
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//解析响应
Aggregations aggregations = response.getAggregations();
//根据名称获取结果
Terms brand_agg = aggregations.get("brand_agg");
//拿到桶
List<? extends Terms.Bucket> buckets = brand_agg.getBuckets();
//遍历桶
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString());
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











