







embedding模型
1、token(词汇单元)
“token”主要用于文本数据的预处理阶段,将文本拆分为基本的词汇单元;“embedding”主要用于将离散的词汇单元连续向量化表示,以便在复杂的机器学习模型中进行处理;“encoding”则主要用于将文本数据转换为神经网络等深度学习模型可处理的向量表示。
token:模型输入基本单元。比如中文BERT中,token可以是一个字,也可以是等标识符。
embedding:一个用来表示token的稠密的向量。token本身不可计算,需要将其映射到一个连续向量空间,才可以进行后续运算,这个映射的结果就是该token对应的embedding。
encoding:表示编码的过程。将一个句子,浓缩成为一个稠密向量,也称为表征,(representation),这个向量可以用于后续计算,用来表示该句子在连续向量空间中的一个点。理想的encoding能使语义相似的句子被映射到相近的空间。
2、词向量
原理参考:https://blog.youkuaiyun.com/weixin_44986037/article/details/130259034
词向量是将字、词语转换成向量矩阵的计算模型。目前为止最常用的词表示方法是 One-hot,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。还有 Google 团队的 Word2Vec,值得一提的是,Word2Vec 词向量可以较好地表达不同词之间的相似和类比关系。除此之外,还有一些词向量的表示方式,如 Doc2Vec、WordRank 和 FastText 等。
向量与张量“维度”的理解:

- 向量:
向量是一维的。向量就是一个1维张量,矩阵是一个二维张量。他们都是张量,只不过dimension不同。(包括单个数字也是一个张量,不过维度不定,对于初学者来说可以理解为一个0维向量吧)。 - 张量和维度:
如果你只是想知道这个张量是几维的,只要看这是几维数组就可以了,更简单的,数一下最前面有几个中括号[就ok了呗。
{
#向量是一维数组
"向量1":[1,2], //维度:1,长度:2
"向量2":[1,2,3], //维度:1,长度:3
#张量是多维数组
"矩阵1":[[1,2], //维度:2,长度:2*2
[2,3]],
"矩阵2":[[1,2,3], //维度:2,长度:3*3
[2,3,4],
[3,4,5]]
}
- 向量组和向量:
在同济大学线性代数第六版中,有这样一句话,矩阵的列向量组和行向量组都是只含有限个向量的向量组;反之,一个含有限个向量的向量组总可以构成一个矩阵。因此我们可以推断,列向量是可以多维的,但是它的深度只能是一维(这里的深度是相对于矩阵和数组而言的,而这里的维度是指的空间的维度,这是两个不同的概念)。
3、相关模型
https://github.com/JovenChu/embedding_model_test
embedding方法分类为:word2vec(基于seq2seq的神经网络结构)、Glove(词共现矩阵)、Item2Vec(推荐中的双塔模型)、FastText(浅层神经网络)、ELMo(独立训练双向,stacked Bi-LSTM架构)、GPT(从左到右的单向Transformer)、BERT(双向transformer的encoder,attention联合上下文双向训练)
Word2Vec:是一种基于神经网络的模型,用于将单词映射到向量空间中。Word2Vec包括两种架构:CBOW (Continuous Bag-of-Words) 和 Skip-gram。CBOW 通过上下文预测中心单词,而 Skip-gram 通过中心单词预测上下文单词。这些预测任务训练出来的神经网络权重可以用作单词的嵌入。
GloVe:全称为 Global Vectors for Word Representation,是一种基于共现矩阵的模型。该模型使用统计方法来计算单词之间的关联性,然后通过奇异值分解(SVD)来生成嵌入。GloVe 的特点是在计算上比 Word2Vec 更快,并且可以扩展到更大的数据集。
FastText:是由 Facebook AI Research 开发的一种模型,它在 Word2Vec 的基础上添加了一个字符级别的 n-gram 特征。这使得 FastText 可以将未知单词的嵌入表示为已知字符级别 n-gram 特征的平均值。FastText 在处理不规则单词和罕见单词时表现出色。
OpenAI的Embeddings:这是OpenAI官方发布的Embeddings的API接口。目前有2代产品。目前主要是第二代模型:text-embedding-ada-002。它最长的输入是8191个tokens,输出的维度是1536。
4、文档向量
https://www.aneasystone.com/archives/2023/07/doc-qa-using-embedding.html
如何计算文档的向量?
对此,前辈大佬们提出了很多种不同的解决方案,比如 Word2vec、GloVe、FastText、ELMo、BERT、GPT 等等,不过这些都是干巴巴的论文和算法,对我们这种普通用户来说,可以直接使用一些训练好的模型。开源项目 Sentence-Transformers 是一个很好的选择,它封装了 大量可用的预训练模型;另外开源项目 Towhee 不仅支持大量的 Embedding 模型,而且还提供了其他常用的 AI 流水线的实现,这里是它支持的 Embedding 模型列表;不过在本地跑 Embedding 模型对机器有一定的门槛要求,我们也可以直接使用一些公开的 Embedding 服务,比如 OpenAI 提供的 /v1/embeddings 接口,它使用的 text-embedding-ada-002 模型是 OpenAI 目前提供的效果最好的第二代 Embedding 模型,相比于第一代的 davinci、curie 和 babbage 等模型,效果更好,价格更便宜。我们这里就直接使用该接口生成任意文本的向量。使用 OpenAI 的 Python SDK 调用该接口如下:
如何存储文档的向量?
第二个问题是计算出来的向量该如何存储?实际上,自从大模型兴起之后,Embedding 和向量数据库就变成了当前 AI 领域炙手可热的话题,一时间,涌出了很多专注于向量数据库的公司或项目,比如 Pinecone、Weaviate、Qdrant、Chroma、Milvus 等,很多老牌数据库厂商也纷纷加入向量数据库的阵营,比如 ElasticSearch、Cassandra、Postgres、Redis、Mongo 等。
5、Word2Vec
https://blog.youkuaiyun.com/IOT_victor/article/details/87914076
Google 团队的 Word2Vec,其主要包含两个模型:跳字模型(Skip-Gram)和连续词袋模型(Continuous Bag of Words,简称 CBOW),以及两种高效训练的方法:负采样(Negative Sampling)和层序 Softmax(Hierarchical Softmax)。
word2vec作为神经概率语言模型的输入,其本身其实是神经概率模型的副产品,是为了通过神经网络学习某个语言模型而产生的中间结果。具体来说,“某个语言模型”指的是“CBOW”和“Skip-gram”。具体学习过程会用到两个降低复杂度的近似方法——Hierarchical Softmax或Negative Sampling。两个模型乘以两种方法,一共有四种实现。
链接:https://blog.youkuaiyun.com/IOT_victor/article/details/87914076
优化:softmax->哈夫曼树->负采样 (softmax到二分类)
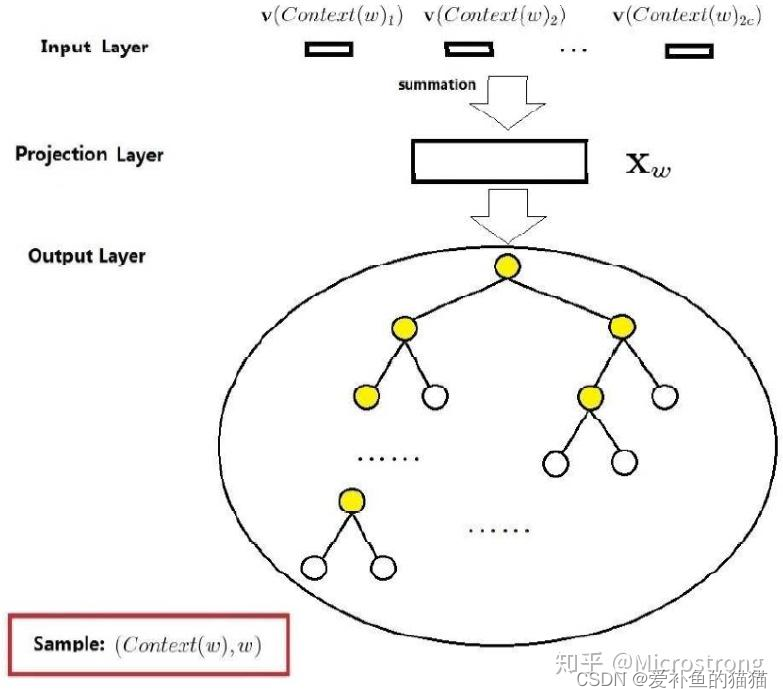
1、hierarchical softmax(利用CBOW)
为了避免要计算所有词的softmax概率,word2vec使用Huffman树来代替从隐藏层到输出softmax层的映射,softmax概率计算只需要沿着树形结构进行。
hierarchical softmax使用一颗二叉树表示词汇表中的单词,每个单词都作为二叉树的叶子节点。对于一个大小为V的词汇表,其对应的二叉树包含V-1非叶子节点。
假如每个非叶子节点向左转标记为1,向右转标记为0,那么每个单词都具有唯一的从根节点到达该叶子节点的由{01}组成的代号
(实际上为哈夫曼编码,为哈夫曼树,是带权路径长度最短的树,哈夫曼树保证了词频高的单词的路径短,词频相对低的单词的路径长,这种编码方式很大程度减少了计算量)。
关于Huffman树和 Huffman编码,有两个约定: (1)将权值大的结点作为左孩子结点,权值小的作为右孩子结点;(2)左孩子结点编码为1,右孩子结点编码为0.
在 word2vec源码中将权值较大的左孩子结点编码为1(负类),较小的右孩子结点编码为0(正类),每一次分支是二分类,将编码为1的结点定义为负类,而将编码为0的结点定义为正类,
将一个结点进行分类时,分到左边就是负类,分到右边就是正类。
2、负采样nagative sampling
https://developer.aliyun.com/article/1459761
https://www.bilibili.com/video/BV1MS4y147js/?spm_id_from=333.337.search-card.all.click
【负采样思想】为每个训练实例都提供负例。负采样算法实际上就是一个带权采样过程,负例的选择机制是和单词词频联系起来的。
【负采样作用】1.加速了模型计算,2保证了模型训练的效果,一个是模型每次只需要更新采样的词的权重,不用更新所有的权重,那样会很慢,第二,中心词其实只跟它周围的词有关系,位置离着很远的词没有关系,也没必要同时训练更新。
深入剖析nagative sampling(利用CBOW):
层次softmax的缺点:遇到生僻词的时候,在哈夫曼树中也要走很久,计算量也很大。
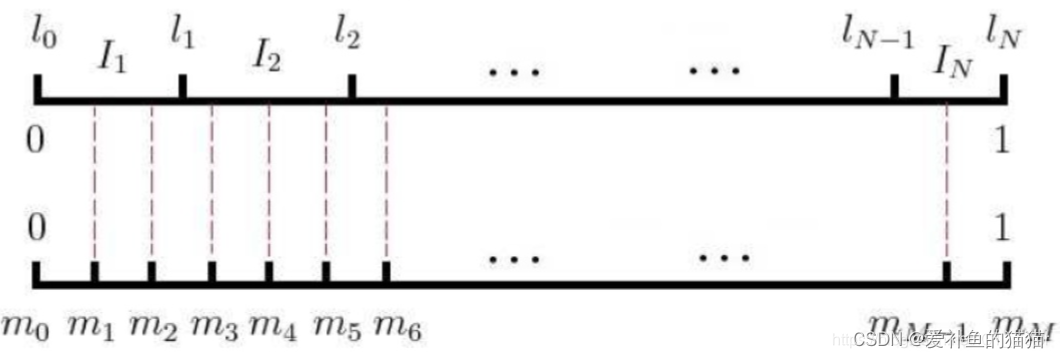
负采样算法:为带权采样,在语料库中计算每个词的词频,即某个词的count/语料库中所有单词总count(源码中分子分母都用的是count四分之三次方,并非直接用count),即为被采样到的概率。在word2vec里的具体做法是,经过概率的计算,可将所有词映射到一条线上,这条线是非等距划分的N份(因为N个词的概率不同),再对同样的线进行等距划分成M份,其中M>>N,在采样时,每次随机生成一个[1,M-1]之间的数,在对应到该小块所对应的单词区域,选区该单词(当选到正例单词自己时,跳过),具体如图:
nagative sampling(利用CBOW)源码中:
并没有对上下文的每一个词都进行负采样,
而是对中心词进行了上下文词个数个负采样,
意思就是本身是用中心词预测多个上下文词,
现在变成用相同数目的中心词预测相同数目的上下文词,但中心词里只有一个是真的,要保证这个概率最大,其他都是假的,要保证假的概率也最大。
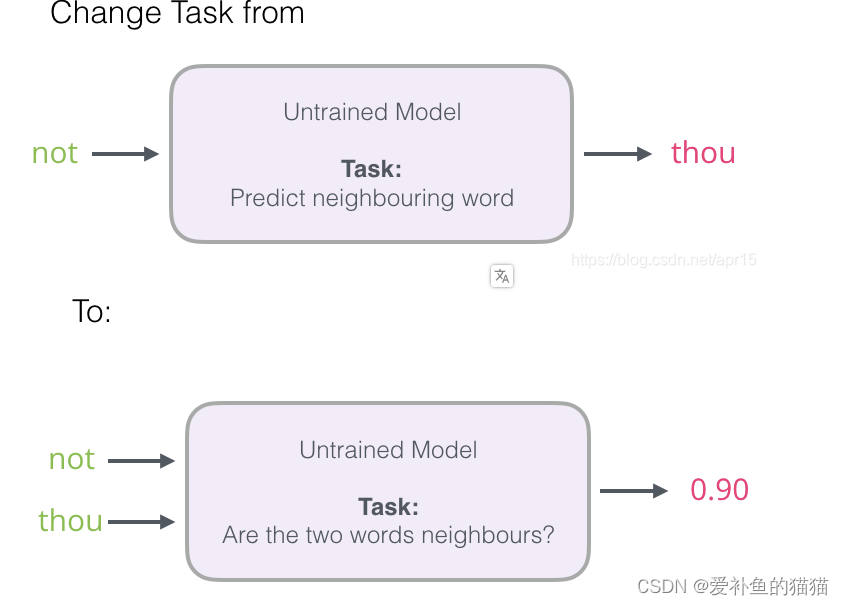
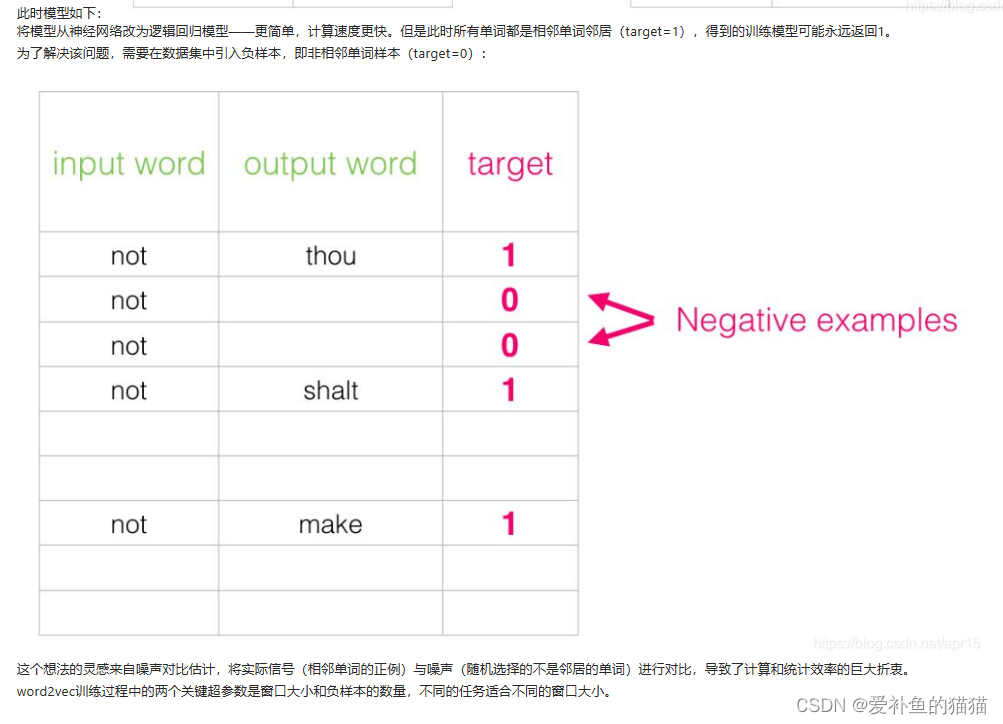
将输入一个词,预测所用词的概率(softmax);输入核心词和某个词,判断两者个正负(二分类)。
3、训练参数设置
https://developer.aliyun.com/article/1459761
gensim或tensorflow实现
5. 使用gensim
gensim是一个很好用的Python NLP的包,封装了google的C语言版的word2vec,不只可以用于word2vec,还有很多其他的API可以用。可以使用
pip install gensim安装。
在gensim中,word2vec 相关的API都在包gensim.models.word2vec中,和算法有关的参数都在类gensim.models.word2vec.Word2Vec中,主要参数如下:
• sentences: 要分析的语料,可以是一个列表,或者从文件中遍历读出。
• size: 词向量的维度,默认值是100。这个维度的取值一般与语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
• window:即词向量上下文最大距离,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
• sg: word2vec两个模型的选择:如果是0(默认), 则是CBOW模型;是1则是Skip-Gram模型。
• hs: word2vec两个解法的选择:如果是0(默认), 则是Negative Sampling;是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。
• negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
• cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的xw为上下文的词向量之和,为1则为上下文的词向量的平均值。
• min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
• iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
• alpha: 在随机梯度下降法中迭代的初始步长。算法原理篇中标记为η,默认是0.025。
• min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。
tensorflow使用:
参考官方:https://www.tensorflow.org/text/tutorials/word2vec
先制作数据集,将单词映射成整数,用Skip-gram抽样表进行抽样,搭建模型,训练模型。
注意:对于本教程,窗口大小n意味着每侧有 n 个单词,每个单词的总窗口跨度为 2*n+1 个单词。
Skip-gram抽样表
sequences现在是 int 编码句子的列表。只需调用generate_training_data前面定义的函数即可生成 word2vec 模型的训练示例。回顾一下,该函数迭代每个序列中的每个单词以收集积极和消极的上下文单词。目标、上下文和标签的长度应该相同,代表训练示例的总数。
大数据集意味着更大的词汇量以及更多更频繁的单词(例如停用词)。从采样常见单词(例如the,,, )中获得的训练示例不会is为on模型学习添加太多有用的信息。米科洛夫等人。建议对频繁出现的单词进行二次采样,作为提高嵌入质量的有用做法。
该tf.keras.preprocessing.sequence.skipgrams函数接受采样表参数来编码采样任何标记的概率。您可以使用tf.keras.preprocessing.sequence.make_sampling_table生成基于词频排名的概率采样表并将其传递给函数skipgrams。检查 a 为 10 的采样概率vocab_size。
6、Bert
原理:https://blog.youkuaiyun.com/sunhua93/article/details/102764783
https://github.com/datawhalechina/learn-nlp-with-transformers/tree/main
BERT是一个预训练的Transformer模型,它在大量的文本数据上进行了预训练,并在多种NLP任务上取得了显著的成果。预训练是指在大量数据上先训练一个通用的模型,然后在特定任务上进行微调的过程。预训练模型可以在特定任务上获得更好的性能,并且可以在不同的任务之间共享知识。这种方法比从头开始训练每个任务的模型更高效和经济。
1、BERT与Transformer的区别:
- BERT模型是Transformer的一种变体,采用了双向编码器结构,而传统的Transformer模型通常使用编码器-解码器结构。BERT模型的预训练过程也与传统的Transformer模型略有不同,采用了Masked Language Modeling和下一句预测任务。
- BERT模型主要用于预训练阶段,目标是学习通用的语义表示,而Transformer模型则更加灵活,可用于各种序列转换任务,如机器翻译、文本分类、命名实体识别等。

BERT双向表示和transformer区别:
transformer的encoding部分没有mask,而Bert的encoding输入部分是有mask的。首先我们指导BERT的预训练模型中,预训练任务是一个mask LM ,通过随机的把句子中的单词替换成mask标签, 然后对单词进行预测。这里注意到,对于模型,输入的是一个被挖了空的句子, 而由于Transformer的特性, 它是会注意到所有的单词的,这就导致模型会根据挖空的上下文来进行预测, 这就实现了双向表示, 说明BERT是一个双向的语言模型。
为了实现深度的双向表示,使得双向的作用让每个单词能够在多层上下文中间接的看到自己。文中就采用了一种简单的策略,也就是MLM。MLM:随机屏蔽掉部分输入token,然后再去预测这些被屏蔽掉的token。
2、Model(MLM)和Next Sentence Prediction(NSP)。
在MLM任务中,BERT将15%的词替换为[MASK]标记,并让模型学习预测这些被掩码的词。这有助于模型理解上下文并捕捉词之间的关系。
NSP任务则是让模型判断两句话是否属于同一个句子。这个任务可以帮助模型理解句子之间的连贯性和逻辑关系。
在微调阶段,BERT可以应用于各种NLP任务,如文本分类、命名实体识别、问答等。只需要对模型进行少量的有监督数据训练,即可在特定任务上取得较好的性能。
1.Masked Language Model
MLM可以理解为完形填空,作者会随机mask每一个句子中15%的词,用其上下文来做预测,例如:my dog is hairy → my dog is [MASK]
此处将hairy进行了mask处理,然后采用非监督学习的方法预测mask位置的词是什么,但是该方法有一个问题,因为是mask15%的词,其数量已经很高了,这样就会导致某些词在fine-tuning阶段从未见过,为了解决这个问题,作者做了如下的处理:
80%的时间是采用[mask],my dog is hairy → my dog is [MASK]
10%的时间是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
10%的时间保持不变,my dog is hairy -> my dog is hairy
那么为啥要以一定的概率使用随机词呢?这是因为transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是"hairy"。至于使用随机词带来的负面影响,文章中解释说,所有其他的token(即非"hairy"的token)共享15%*10% = 1.5%的概率,其影响是可以忽略不计的。Transformer全局的可视,又增加了信息的获取,但是不让模型获取全量信息。
2.Next Sentence Prediction (NSP)
在 BERT 的训练过程中,模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子。在训练期间,50% 的输入对在原始文档中是前后关系,另外 50% 中是从语料库中随机组成的,并且是与第一句断开的。
3、BERT:pre-training 和 fine-tuning预训练微调
参考:https://www.cnblogs.com/justLittleStar/p/17322240.html
BERT:分为pre-training 和 fine-tuning,两个阶段。
pre-training 阶段,BERT 在无标记的数据上进行无监督学习;
fine-tuning 阶段,BERT利用预训练的参数初始化模型,并利用下游任务标记好的数据进行有监督学习,并对所有参数进行微调。
自编码语言模型的优缺点:
优点:自然地融入双向语言模型,同时看到被预测单词的上文和下文
缺点:训练和预测不一致。训练的时候输入引入了[Mask]标记,但是在预测阶段往往没有这个[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致。https://github.com/datawhalechina/learn-nlp-with-transformers/blob/main
-
BERT采用Pre-training和Fine-tuning两阶段训练任务(源于GPT):
1)在Pre-training阶段使用多层双向Transformer Encoder进行训练,并采用Masked LM 和 Next Sentence Prediction两种训练任务解决 token-level 和 sentence-level 的问题,为下游任务提供了一个通用的模型框架;
2)在 Fine-tuning 阶段会针对具体 NLP 任务进行微调以适应不同种类的任务需求,并通过端到端的训练更新参数从而得到最终的模型。 -
BERT优点:
BERT的Transformer Encoder的Self-Attention结构能较好地建模上下文,而且在经过在语料上预训练后,能获取到输入文本较优质的语义表征。
BERT的MLP和NSP联合训练,让其能适配下游多任务(Token级别和句子级别)的迁移学习 -
BERT缺点:
[MASK] token在推理时不会出现,因此训练时用过多的[MASK]会影响模型表现(需要让下游任务去适配预训练语言模型,而不是让预训练语言模型主动针对下游任务做优化)
每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(BERT对语料的利用低。而GPT对语料的利用率更高,它几乎能利用句子的每个token);
BERT的上下文长度固定为512,输入过长需要阶段(对长文本不友好)
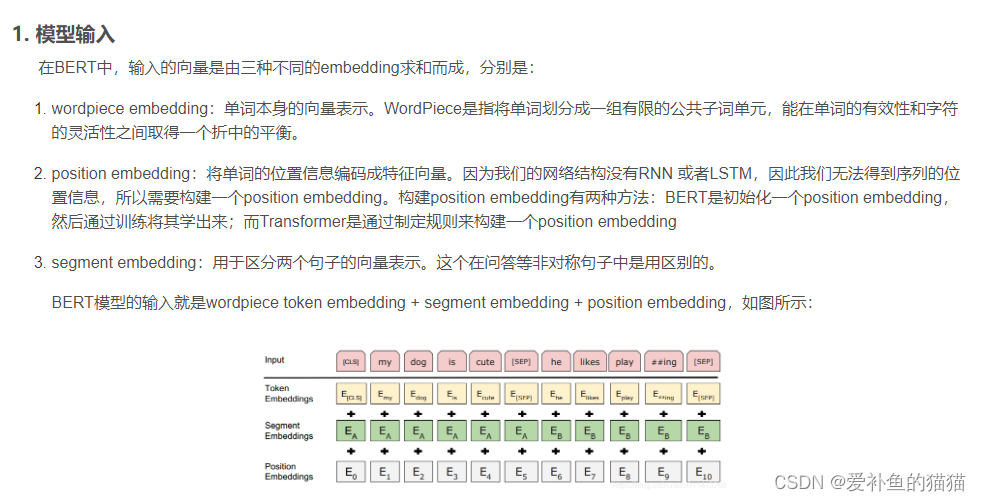
4、Bert的输入
5、XLNet和bert
XLNet在自回归语言模型中,通过PLM引入了双向语言模型。也就是在预训练阶段,采用attention掩码的机制,通过对句子中单词的排列组合,把一部分下文单词排到上文位置。
PLM预训练目标、更多更高质量的预训练数据,transformerXL的主要思想。这就是XLNet的三个主要改进点,这使XLNet相比bert在生成类任务上有明显优势,对于长文档输入的nlp任务也会更有优势。
XLNet的实验可以看出,对于阅读理解类任务相对bert有极大提升,transformerXL的引入肯定是起了较大的作用,但由于数据差异没有抹平,所以无法确定是否是模型差异带来的效果差异。对于其他的nlp任务,效果有幅度不大的提升,同样无法确定这种性能提升来自于那个因素。其中磨平了数据规模因素的实验,可以发现,PLM和transformerXL确实带来了收益。XLNet在长文档和生成类任务比较有优势,在优势领域的应用结果值得期待,以及在这些任务上的进一步改进模型。
LNet 是一种大型双向 transformer,采用的是一种经过改进的训练方法。这种训练方法能够利用规模更大的数据集与更强的计算能力在 20 项语言任务中获得优于 BERT 的预测指标。为了改进训练方法,XLNet 还引入了转换语言建模,其中所有标记都按照随机顺序进行预测。这就与 BERT 的掩蔽语言模型形成了鲜明对比。具体来讲,BERT 只预测文本中的掩蔽部分(占比仅为 15%)。这种方法也颠覆了传统语言模型当中,所有标记皆按顺序进行预测的惯例。新的方法帮助模型掌握了双向关系,从而更好地处理单词之间的关联与衔接方式。此外该方法还采用 Transformer XL 作为基础架构,以便在非排序训练场景下同样带来良好的性能表现。
6、transformer和bert应用场景
Bert主要用于各种自然语言处理任务,如文本分类、命名实体识别、问答系统等,而Transformer主要用于序列到序列的任务,如机器翻译、语音识别等。
7、文本概括算法
https://developer.baidu.com/article/details/1847167
一、文本摘要的基本概念
文本摘要是指将一段长文本或大量文本进行简化和概括,以提取其中的关键信息,形成一段短小精悍的文字。这个过程涉及到对原始文本的理解、分析和筛选,以及对关键信息的归纳和表达。好的文本摘要应该既能够准确地概括原文的主旨,又能够让读者一目了然地了解主要内容。
8、Embedding排行榜
Huggingface上的mteb是一个海量Embeddings排行榜,定期会更新Huggingface开源的Embedding模型各项指标,进行一个综合的排名,大家可以根据自己的实际应用场景,选择适合自己的Embedding模型。
链接: embedding模型
在MTEB的排行榜中,数据会定期刷新,排行数据也会定期变化。比如,我前阵子在做模型评测时,那时候达摩院开源的GTE排在了第一位,今天再看的时候,已经掉下去了。
系列长度:Max Tokens
embedding维度:Embedding Dimensions

















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









