




 本文介绍了数据重构的概念,重点讲解了Pandas中的数据合并方法,包括stack、concat、join、append和merge,并提供了相关代码示例。此外,还详细阐述了groupby的用法,用于数据的分组聚合。通过一系列实战任务,展示了如何在实际操作中应用这些方法。
本文介绍了数据重构的概念,重点讲解了Pandas中的数据合并方法,包括stack、concat、join、append和merge,并提供了相关代码示例。此外,还详细阐述了groupby的用法,用于数据的分组聚合。通过一系列实战任务,展示了如何在实际操作中应用这些方法。
1.了解数据重构的方法
2.学会使用groupby作数据运算
什么是数据重构?
数据重构:指数据从一种格式到另一种格式的转换,包括结构转换、格式变化、类型替换等,以解决空间数据在结构、格式和类型上的统一,实现多源和异构数据的联接与融合。
合并数据集
stack
使用pandas进行数据重排时,经常用到stack和unstack两个函数。stack的意思是堆叠,堆积,unstack即“不要堆叠”。
常见的数据层次化结构有:花括号和表格。
表格在行列方向上均有索引(类似于DataFrame)。
花括号结构只有“列方向”上的索引(类似于层次化的Series)。
stack函数会将数据从”表格结构“变成”花括号结构“,即将其行索引变成列索引,反之,unstack函数将数据从”花括号结构“变成”表格结构“,即要将其中一层的列索引变成行索引。
stack:stack函数会将数据从”表格结构“变成”花括号结构“ ,将列索引转为行索引,完成层级索引
unstack:unstack函数将数据从”花括号结构“变成”表格结构“,层级索引展开 ,默认操作内层索引
df_obj = pd.DataFrame(np.random.randint(0,10, (5,2)), columns=['data1', 'data2'])
df_obj

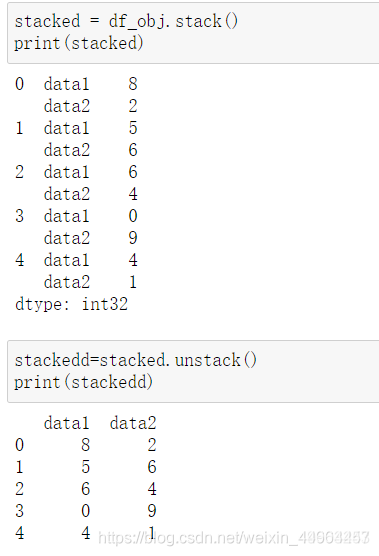
stacked = df_obj.stack()
print(stacked)
stackedd=stacked.unstack()
print(stacked)
代码结果如下所示·:
concat
Pandas中的pd.concat与np.concatenate类似,但可选参数更多,功能更为强大。
pd.concat可以简单地合并一维的对象:
ser1 = pd.Series(['A', 'B', 'C'], index=[1, 2, 3])
ser2 = pd.Series(['D', 'E', 'F'], index=[4, 5, 6])
pd.concat([ser1, ser2])
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









