







分类问题
概述
回归可以用于预测,比如我们提到过的预测房屋价格等。有时候,我们可能也会对分类问题感兴趣,不是关心多少,而是关心“哪一个”:
- 某个电子邮件是否是垃圾邮件
- 某用户可能注册或不注册订阅服务
- 某个图像绘制的是狗,猫还是牛,马
这里的分类问题并不包括分析图像,得到图像中未知物品的名称,而是在预定范围下,判断图像中物品是不是已知物品中的某一个。
独热编码
统计学家很早以前就发明了一种表示分类数据的简单方法:独热编码(one-hot encoding)。 独热编码是一个向量,它的分量和类别一样多。 类别对应的分量设置为1,其他所有分量设置为0。 在我们的例子中,标签 y 将是一个三维向量, 其中 (1,0,0) 对应于“猫”、 (0,1,0) 对应于“鸡”、 (0,0,1) 对应于“狗”:
网络结构
为了解决线性模型的分类问题,我们需要一个和输出与一样多的仿射函数(affine function)。每个输出有自己对应的仿射函数。例如,我们输入四个特征,有三个可能的输出,那么我们可以将函数总结为:
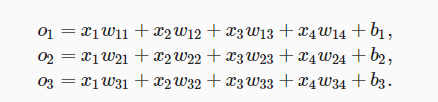
softmax运算
我们希望模型的输出y_hat可以视为属于类j的概率,然后选择具有最大输出值的类别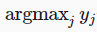 作为我们的预测,例如如果y_hat1,y_hat2,y_hat3分别是0.1,0.8,0.1,那么我们预测类别是2.
作为我们的预测,例如如果y_hat1,y_hat2,y_hat3分别是0.1,0.8,0.1,那么我们预测类别是2.
然而我们是否能将未规范化的预测O直接作为我们的输出呢?显然不行,因为 因为将线性层的输出直接视为概率时存在一些问题: 一方面,我们没有限制这些输出数字的总和为1。 另一方面,根据输入的不同,它们可以为负值。 这些违反了概率基本公理。
那要将输出视为概率我们应该怎么做呢?
首先,我们必须保证任何数据在上面输入后输出都是非负的且总和为.0。此外,我们需要一个训练目标,来鼓励模型精准的估计概率。在分类器输出0.5的所有样本中,我们希望这些样本有一半实际上属于预测的类。 这个属性叫做校准(calibration)。
幸运的是,我们有这样的softmax函数,他正是能够将未规范化的预测变换为非负且总和为1,同时要求模型保持可导。如下图所示:

损失函数
我们需要使用一个损失函数来度量预测结果,我们将使用最大似然估计,或者简言之,使用交叉熵损失。
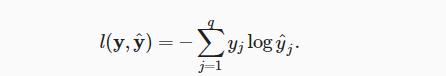
优化算法
因为仍属于回归问题, 我们仍然使用梯度下降算法作为优化算法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









