







基本概念
通过下面表格进行基本概念的介绍
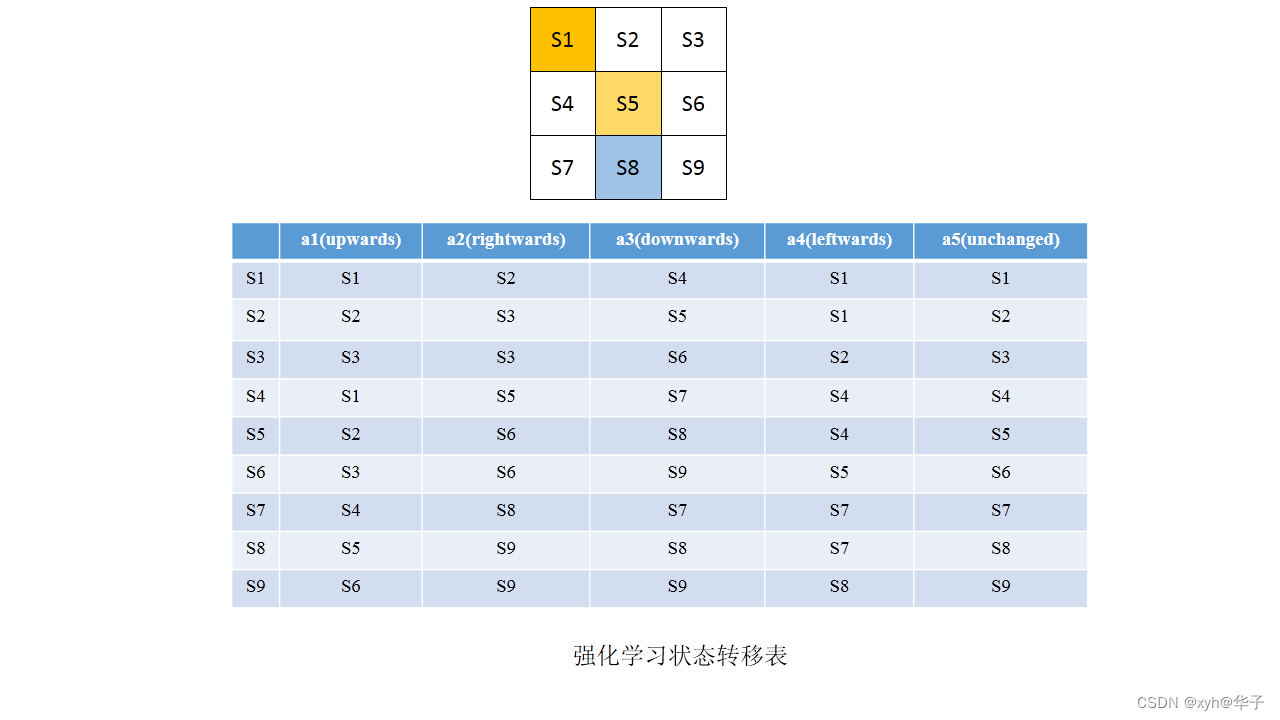
状态(state)
在强化学习转态转移表中,S1-S9均表示状态,这里共有九个状态。
注:这里转态有限,所以表达力也有限
动作(action)
上表中,a1-a5均为action。
状态转换(state transition)
转态转移,有多种可能,每种转移概率都不一样,所以状态转移等同数学上条件概率的计算,如下式公式:
Gamma公式展示
Γ
(
n
)
=
(
n
−
1
)
!
∀
n
∈
N
\Gamma(n) = (n-1)!\quad\forall n\in\mathbb N
Γ(n)=(n−1)!∀n∈N 是通过 Euler integral
p ( s 2 ∣ s 1 , a 2 ) = 1 , p ( s i ∣ s 1 , a 2 ) = 0 p(s2|s1,a2) = 1, p(si|s1,a2) = 0 p(s2∣s1,a2)=1,p(si∣s1,a2)=0
策略(policy)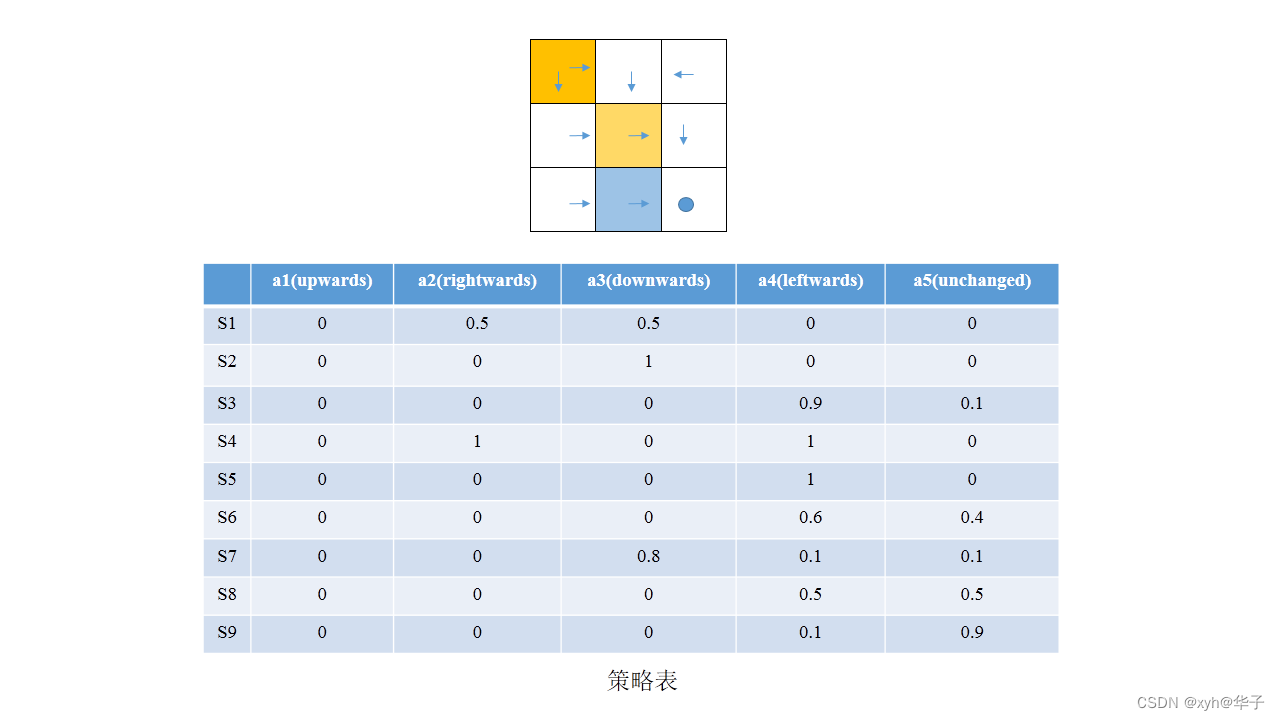
从上述策略表,每个转态下,采取action的概率都不相同,采取action的概率集合就是策略,就是上述策略表中每一行。
奖赏(reward)
通常使用一个正数代表鼓励,负数代表惩罚,其实0也算一种正反馈,也是一种鼓励。
注:reward实际是交互的指引。
reward依赖当前的状态
路径(trajectory is a state-action-reward chain)
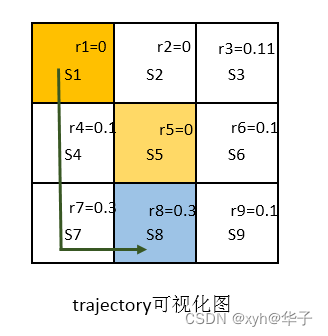
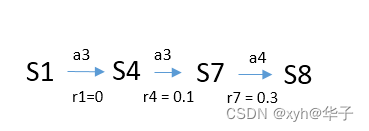
上图中S1->S8的trajectory,该路径获得return值为r1+r4+r7+r8 = 0.7。
上述只是其中一条trajectory,需要不断调整policy,找出最好trajectory。
MDP的要素
集合(Sets)
- State:状态集合
- Action:每个状态下行动集合
- Reward:奖赏的集合
概率分布(probability distribution)
- State trasnsition probability:在某个状态下,采取某种行动,转移到新的状态的概率。
- Reward probability:在某种状态下,采取某种行动,获得的奖励。
策略(policy)
- 在某种状态下,采取某种行动的概率。
马可夫属性(markon property)
- 无记忆性
- p ( s t + 1 ∣ a t + 1 , s t , . . . , a 1 , s 0 ) = p ( s t + 1 ∣ a t + 1 , s t ) , p ( r t + 1 ∣ a t + 1 , s t , . . . , a 1 , s 0 ) = p ( r t + 1 ∣ a t + 1 , s t ) p(s_{t+1}|a_{t+1},s_{t},...,a_{1},s_{0}) =p(s_{t+1}|a_{t+1},s_{t}) , p(r_{t+1}|a_{t+1},s_{t},...,a_{1},s_{0})=p(r_{t+1}|a_{t+1},s_{t}) p(st+1∣at+1,st,...,a1,s0)=p(st+1∣at+1,st),p(rt+1∣at+1,st,...,a1,s0)=p(rt+1∣at+1,st)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









