









 本文详细介绍了Selenium WebDriver中八种常用的元素定位方法,包括id、name、classname、tagname、linktext、partiallinktext、xpath和cssselector定位。通过实例展示了如何使用这些方法在百度首页上定位各种元素。
本文详细介绍了Selenium WebDriver中八种常用的元素定位方法,包括id、name、classname、tagname、linktext、partiallinktext、xpath和cssselector定位。通过实例展示了如何使用这些方法在百度首页上定位各种元素。
介绍
WebDriver是Selenium体系中设计出来操作浏览器的一套API,可支持多种编程语言,对于Python来说,可以将WebDriver视为Python的一个用于实现Web自动化的第三方类库。
WebDriver一共提供了下面八种元素定位方法。
| 定位方式 | 使用方法 |
|---|---|
| id | find_element_by_id() |
| name | find_element_by_name() |
| class name | find_element_by_class_name() |
| tag name | find_element_by_tag_name() |
| link text | find_element_by_link_text() |
| partial link text | find_element_by_partial_link_text() |
| xpath | find_element_by_xpath() |
| css selector | find_element_by_css_selector() |
1.id定位
HTML规定id属性在HTML文档中必须是唯一的,WebDriver提供的id定位方法就是通过元素的id属性来查找元素。通过id定位百度输入框与搜索按钮,用法如下:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
#定位百度的输入框
driver.find_element_by_id('kw')
#定位百度一下的按钮
driver.find_element_by_id('su')
2.name定位
HTML规定name来指定元素的名称,name的属性值在当前页面可以不唯一。通过name定位百度输入框:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
#使用id方法定位百度的输入框
driver.find_element_by_id('kw')
#使用name方法定位百度的输入框
driver.find_element_by_name('wd')
3.class name定位
HTML规定class来指定元素的类名。通过class属性定位百度输入框和搜索按钮:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
#使用class name方法定位百度的输入框
driver.find_element_by_class_name('s_ipt')
注:上面定位百度输入框的三种方法可以看出相同的位置可以使用不同的定位方法实现。
4.tag name定位
HTML的本质就是通过tag来定义实现不同的功能,每一个元素本质上也是一个tag。因为一个tag往往用来定义一类功能,所以通过tag识别某个元素的概率很低。通过tag定位百度的输入框与搜索按钮会发现它们完全相同:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
find_element_by_tag_name(“input”)
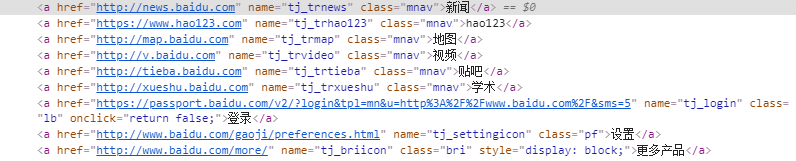
5.link text定位
link定位与前面的几种定位方法不用,它专门用来定位文本链接。定位百度上面的一些文本的代码如下:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element_by_link_text('新闻')
driver.find_element_by_link_text('hao123')
driver.find_element_by_link_text('地图')
driver.find_element_by_link_text('视频')
...
6.partial link text定位
parial link text定位是对link text定位的一种补充,有些文本链接会比较长,这个时候我们可以取文本链接的一部分定位,只要这一部分信息可以唯一地标识这个链接。通过partial link定位百度首页的文本链接的代码如下:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element_by_link_text('新')
driver.find_element_by_link_text('hao')
driver.find_element_by_link_text('地')
driver.find_element_by_link_text('视')
...
7.xpath定位
Xpath是一种在XML文档中定位元素的语言。因为HTML可以看作XML的一种实现,所以Selenium用户可以使用这种强大的语言在Web应用中定位元素。同样以百度输入框和搜索按钮为例:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
#使用xpath方法定位百度输入框和“百度一下”的按钮
driver.find_element_by_xpath('//*[@id="kw"]')
driver.find_element_by_xpath('//*[@id="su"]')
8.css selector定位
CSS是一种语言,它是用来描述HTML和XML文档的表现。CSS使用选择器来为页面元素绑定属性。这些选择器可以被 selenium 用作另外的定位策略。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
#使用css selector方法定位百度输入框和“百度一下”的按钮
driver.find_element_by_css_selector('#kw')
driver.find_element_by_css_selector('#su')
注:根据顺序复制你需要的xpath或者css selector:首先查看网页源代码->选择需要复制的位置->右键->copy->copy Xpath或者copy selector.即可。
实例
from selenium import webdriver
import time
driver = webdriver.Chrome()
#打开百度首页
driver.get('https://www.baidu.com/')
#打开百度新闻
driver.find_element_by_link_text('新闻').click()
#从百度新闻后退到百度首页
driver.back()
#定位百度输入框并模拟输入selenium
driver.find_element_by_css_selector('#kw').send_keys('selenium')
#定位百度一下按钮,并点击搜索
driver.find_element_by_css_selector('#su').click()
time.sleep(5)
driver.quit()
整个过程自动进行,小伙伴们学会了吗?找一个其他的网页试试吧!

















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









