






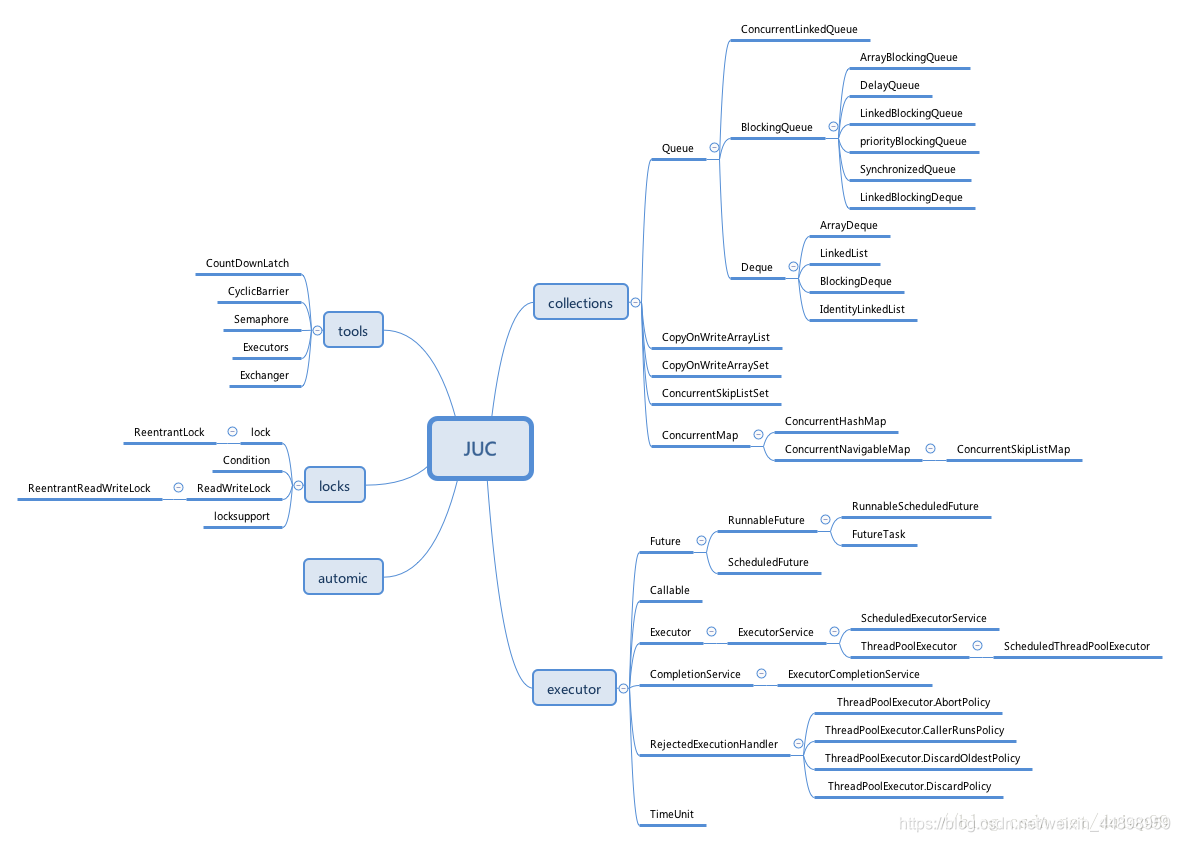
主要架构图示
Volatile与CAS
Volatile是一个只能修饰成员变量的关键字。
对volatile变量进行写操作时,其生成的汇编代码会加上一个lock前缀,lock的作用是
- 将处理器缓存的数据写回内存
- 使其他处理器缓存了该内存地址的数据无效
Volatile的内存语义
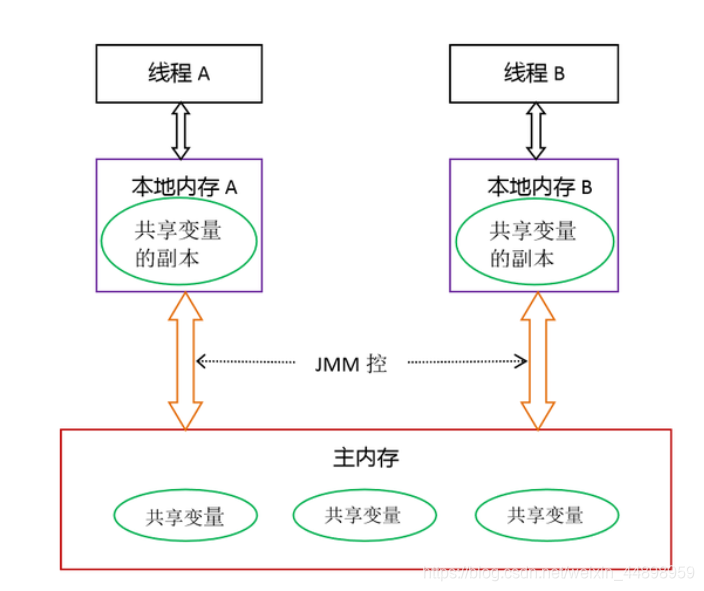
JMM(java内存模型,逻辑概念)
我们来看一个例子,我们准备一个布尔类型的标记量flag,使用一个线程修改,两个线程获取这个flag;
public class JMM {
private boolean flag =false ;
public static void main(String[] args) {
JMM jmm = new JMM();
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(3);
jmm.flag = true;
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程1"+jmm.flag);
}).start();
new Thread(()->{
while (true)
{
if(jmm.flag) {
System.out.println("线程2得到最新的flag");
return;
}
}
}).start();
new Thread(()->{
while (true)
{
try {
TimeUnit.SECONDS.sleep(4);
System.out.println("线程3"+jmm.flag);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
开始运行

可以看到我们第二个线程始终没有获取到最新的flag值(由于while(true)和if判断没有数据依赖关系,编译器与cpu做了某种指令优化重排导致的,可能这就是在cpu已经拥有缓存一致性的情况下,我们还需要Volatile的原因)

接下来,我们把flag修饰成Volatile类型
private volatile boolean flag =false ;
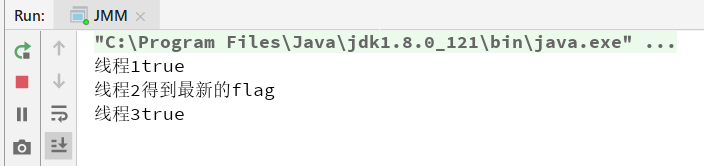
可以看到线程二获得了修改过的flag值。
这说明volatile的内存语义是:
- 当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存。(是所有的共享变量!!不只是volatile类型)
- 当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效,从新从主内存中读取共享变量。(是所有的共享变量!!)
volatile内存语义的实现
以下是JMM内存屏障插入策略
- 在每个volatile写之前插入StoreStore (禁止屏障上面的volatile写和屏障下面的volatile写重排序)
- 在每个volatile写之后插入StoreLoad(禁止屏障上面的volatile写和屏障下面的volatile读重排序)
- 在每个volatile读之后插入一个LoadLoad(禁止屏障上面的volatile读和屏障下面的volatile读重排序)和LoadStore(禁止屏障上的volatile读和屏障下面的volatile写重排序)
CAS
关于CAS
https://blog.youkuaiyun.com/weixin_44898959/article/details/109561574
总结
对于一个volatile类型:
每次写操作,都能被所有拥有它的线程立即感知到。
每次读,都是读的共享内存中最新版本的变量。
(对于volatile不保证原子性这个说法,我认为准确来说是volatile的读+写整个过程不是原子的)
CAS的取值,比较,交换的过程是一个原子性操作,可以看成是一个过程。
对Volatile类型的变量进行CAS,实现了线程间的轻量级通讯,是JUC包的基石。
(比如,一个把volatile int类型的变量a当成锁,a=1表示以被占用。不同线程在同时想要对a进行cas,只可能有一个线程修改成功,这个线程变占得了锁)
Locks包
LockSupport
使用JUC包进行并发编程时,线程的阻塞和唤醒的时机,都依靠java api来决定。LockSupport就是提供这些方法的工具类
| 方法名称 | 描述 |
|---|---|
| void park() | 阻塞当前线程,可调用unpark和Thread.interrupt,使线程从park处返回 |
| void parkNanos(long nanos) | 阻塞当前线程,最长不超过nanos纳秒 |
| void parkUntil(long deadline) | 阻塞当前线程,直到deadline时间 |
| void unpark(Thread t) | 唤醒某个线程 |
在java 6之后,LockSupport又引入了3个新方法park(Object blocker),parkNanos(Object blocker,long nanos),parkUntil(Object blocker,long deadline)。其中,blocker是用来表示线程正在等待的对象,这样在线程阻塞时,虚拟机能返回更多的信息给程序员。
Lock接口及其实现
JUC引入了Lock接口,不同于关键字synchronized地方是
1.synchronized是java的关键字,由jvm层面实现,
通过观察字节码,被synchronized修饰的方法前后会分别插入monitorenter,monitorexit指令,是c++中Monitor对象负责
Lock是具体类实现,是java api层面,
2.synchronized自动加锁,解锁,Lock需要手动加锁,解锁
3.是否可以中断阻塞:synchronized不可中断,Lock可中断:通过设置超时,或者线程调用interrupt。
4.Lock可指定是否为公平锁,synchronized默认非公平
5.Lock可以绑定多个condition,实现精准唤醒
ReentrantLock
ReentrantLock故名思意,可重入锁。当线程持有锁时,如果再次抢占这把锁,会直接抢占到手。
ReadWriteLock
之前遇到的锁基本都是排他锁,这些再同一时刻只允许一个线程进行访问。
ReadWriteLock中维护了一对锁,一个读锁一个写锁。读锁可以多线程同时持有,写锁是排他锁。当写锁被获取到时,其他线程获取读锁和写锁都会阻塞
Lock锁的实现:AQS(AbstrctQueueSynchronizer)
前面介绍ReentrantLock和ReadWriteLock草草带过,因为这并不是重点,Lock锁是表面,它提供简易的API供程序员调用。使得程序员可以不用知道其背后逻辑,而锁的本质是一个抽象队列同步器。
平常我们new一个lock,其实本质上是new了一个AQS,AQS用一个Volatile int变量state来维护资源的占有状态,用一个CLH队列来维护阻塞线程,CLH本质是一个FIFO队列,其结点Node是对线程的封装。对线程的阻塞与唤醒本质是调用了LockSupport的park和unpark方法
AQS原理及源码学习
Condition接口
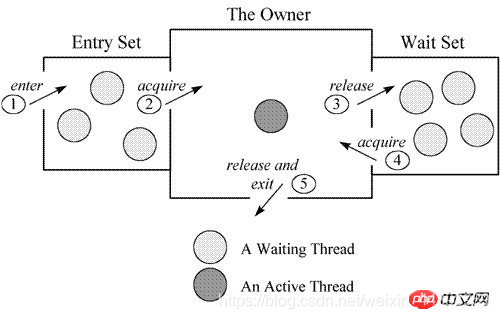
任意一个Java对象,都有一组监视器方法(Object提供),及wait,notify,notifyall。这些方法与synchronized关键字配和(如果没有对象并没有成为被线程获得的锁,调用这些方法会报错),实现了等待/通知模式。
图示是jvm底层实现的monitor机制
Condition也提供了类似这样的监视器方法,与Lock配和可以实现等待/通知模式。不同的地方是。
- 可以通过lock获得多个condition,实现多个等待队列。
Condition实现分析
实现Condition接口的是AQS的内部类ConditionObject。既然是内部类,那么condition对象能调用AQS的成员
Condition对象只能由Lock.newCondition获得,可以Condition和Lock是多对一关系。
观察ConditionObject源码

我们可以轻易发现,每一个Condition都封装了一个线程等待队列(上文讲过,AQS中的Node对象是用来封装线程的)
观察await方法
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
我们发现,当codition对象调用await方法后(注意,如果当前线程没有获得lock锁,调用await会直接抛异常),会将当前线程入队到codition的等待队列,然后使得当前线程释放锁,并调用LockSupport.park方法阻塞当前线程。
观察signal()方法
public final void signal() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
Node first = firstWaiter;
if (first != null)
doSignal(first);
}
private void doSignal(Node first) {
do {
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
//自旋锁
} while (!transferForSignal(first) &&
(first = firstWaiter) != null);
}
//下面的是AQS的方法了
final boolean transferForSignal(Node node) {
//CAS修改Node线程节点状态失败便return false,继续循环
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
//当前node进入同步队列
Node p = enq(node);
int ws = p.waitStatus;
// 结点插入Sync队列尾部,并返回这个结点的前驱结点(也就是之前的Tail)
//这里检查了前驱节点的状态,如果前驱节点是异常的,就唤醒一次目标线程(确实没理解这样做干嘛,听别人分析是为了提高性能)
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
可以看到,调用signal方法的线程也必须拥有锁,不然直接抛异常。当线程调用signal方法后,会将codition对象等待队列中的第一个线程,使用CAS修改其waitStatus,随后加入到AQS的同步队列中
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
当锁被前驱线程释放,该线程被唤醒后,将跳出这个while循环,进而调用acqueireQueued()方法尝试着获得锁,获取到锁之后,线程就会继续运行。
signalAll()方法,相当与对等待队列中的每个节点均执行一次signal方()法
总结
调用codition.await,线程会释放锁,并且进入该codition维护的等待队列,然后调用Support.park阻塞线程
调用codition.signal,会将改codition等待队列中的队首线程移动到AQS的同步队列,等到竞争到锁,就可以从await处返回
JUC中的Collection
Queue接口
ConcurrentLinkedQueue
线程安全的队列,和阻塞队列不同,ConcurrentLinkedQueue是使用自旋锁的方式保证线程安全的。由于用到的地方不多,这里先不深入学习了。
BlockingQueue
阻塞队列提高了多组不同方式的出队和入队操作。
以下是各种方法对满队时入队,空队时出队的特殊处理
| 方法类型 | 抛出异常 | 特殊值(boolean) | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除 | remove() | poll() | take() | poll(time,unit) |
| 检查 | element() | peek() | 不可用 | 不可用 |
JUC提供了7种BlockingQueue的实现
ArrayBlockingQueue:由数组结构,有界
LinkedBlockingQueue:链表结构,有界(默认是Inter.MAX_VALUE)
priorityBlockQueue:支持优先级排序的无界阻塞队列
DelayQueueQueue:使用priorityBlock实现的延迟
SynchronousQueue:不储存元素的阻塞队列,生产一个对应消费一个
LinkedTransferQueue:链表结构,无界阻塞队列
LinkedBlockingDeque:链表结构,双向阻塞队列
使用等待/通知模式实现一个简单的BlockIngQueue
class MyArrayBlockingQueue<T>
{
private Lock lock = new ReentrantLock();
private Condition full = lock.newCondition();
private Condition empty = lock.newCondition();
private Object[] elements;
private int putIndex;//入队位置
private int takeIndex;//出队位置
private int cap;//队列容量
public MyArrayBlockingQueue(int cap)
{
this.elements = new Object[cap];
this.cap = cap;
putIndex = 0;
takeIndex = 0;
}
public void put(T t)
{
lock.lock();
try {
//队列满就阻塞
while (putIndex == cap-1) {
full.await();
}
elements[putIndex] = t;
putIndex++;
empty.signal();
}catch (InterruptedException e)
{
e.printStackTrace();
}
finally {
lock.unlock();
}
}
public T take() throws InterruptedException {
lock.lock();
try{
//队列空就阻塞
while (takeIndex == putIndex)
{
empty.await();
}
T res = (T)elements[takeIndex];
takeIndex++;
full.signal();
return res;
}
finally {
lock.unlock();
}
}
}
Deque
双端队列,可以同时满足栈和队列的功能
CopyOnWriteArrayList
使用Lock对象加锁,写时复制,总是将数组换成一个新的
public boolean add(E e) {
final ReentrantLockDemo lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
相对于vector的synchronized关键字加锁 。
CopyOnWriteArraySet
ConcurretnHashMap
众所周知,哈希表是中非常高效,复杂度为O(1)的数据结构,在Java开发中,我们最常见到最频繁使用的就是HashMap和HashTable,但是在线程竞争激烈的并发场景中使用都不够合理。
HashMap :先说HashMap,HashMap是线程不安全的,在并发环境下,可能会形成环状链表(扩容时可能造成,具体原因自行百度google或查看源码分析),导致get操作时,cpu空转,所以,在并发环境中使用HashMap是非常危险的。
HashTable : HashTable和HashMap的实现原理几乎一样,差别无非是1.HashTable不允许key和value为null;2.HashTable是线程安全的。但是HashTable线程安全的策略实现代价却太大了,简单粗暴,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把大锁,多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞,相当于将所有的操作串行化,在竞争激烈的并发场景中性能就会非常差。
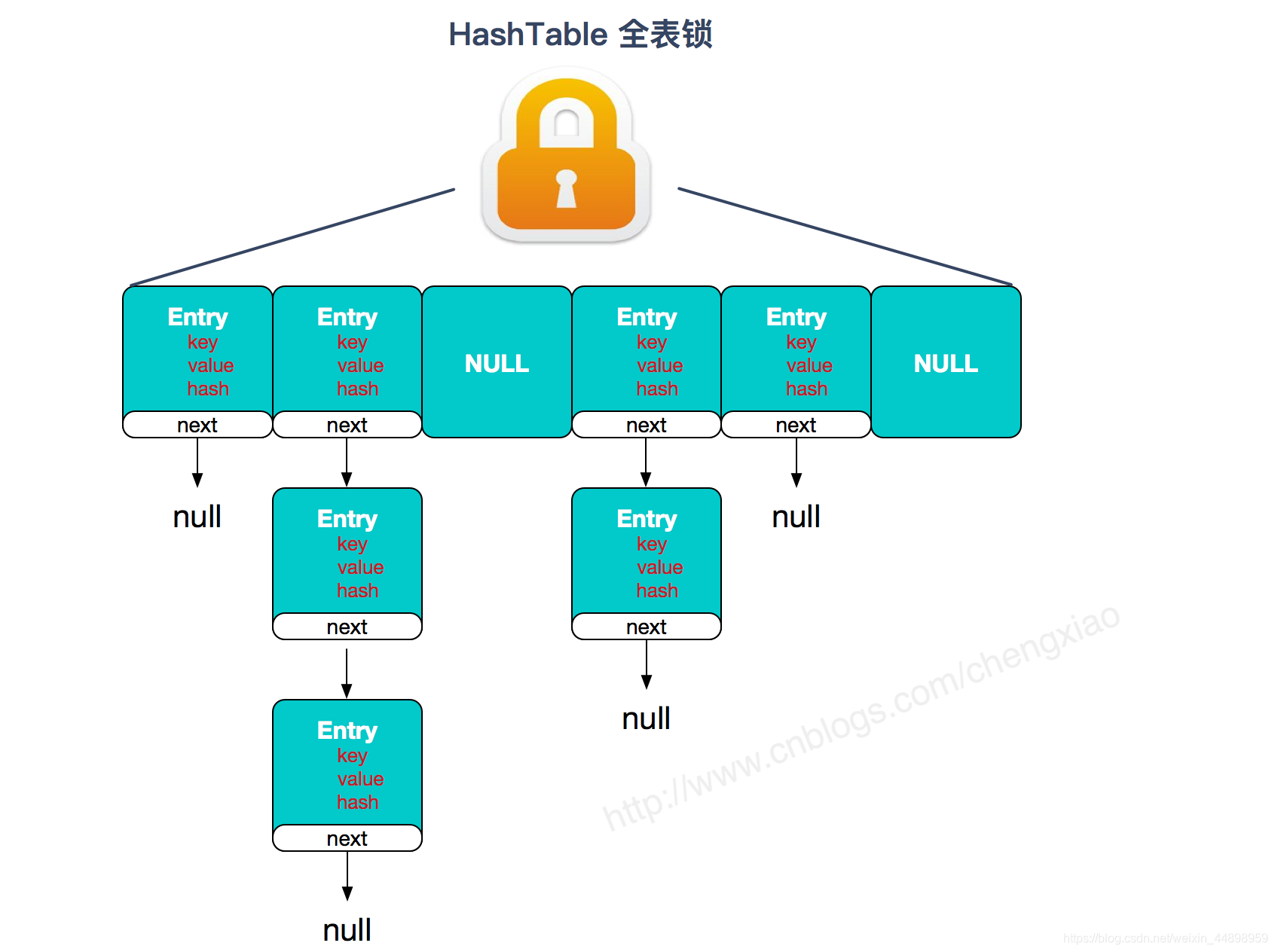
HashTable性能差主要是由于所有操作需要竞争同一把锁,而如果容器中有多把锁,每一把锁锁一段数据,这样在多线程访问时不同段的数据时,就不会存在锁竞争了,这样便可以有效地提高并发效率。这就是ConcurrentHashMap所采用的"分段锁"思想。
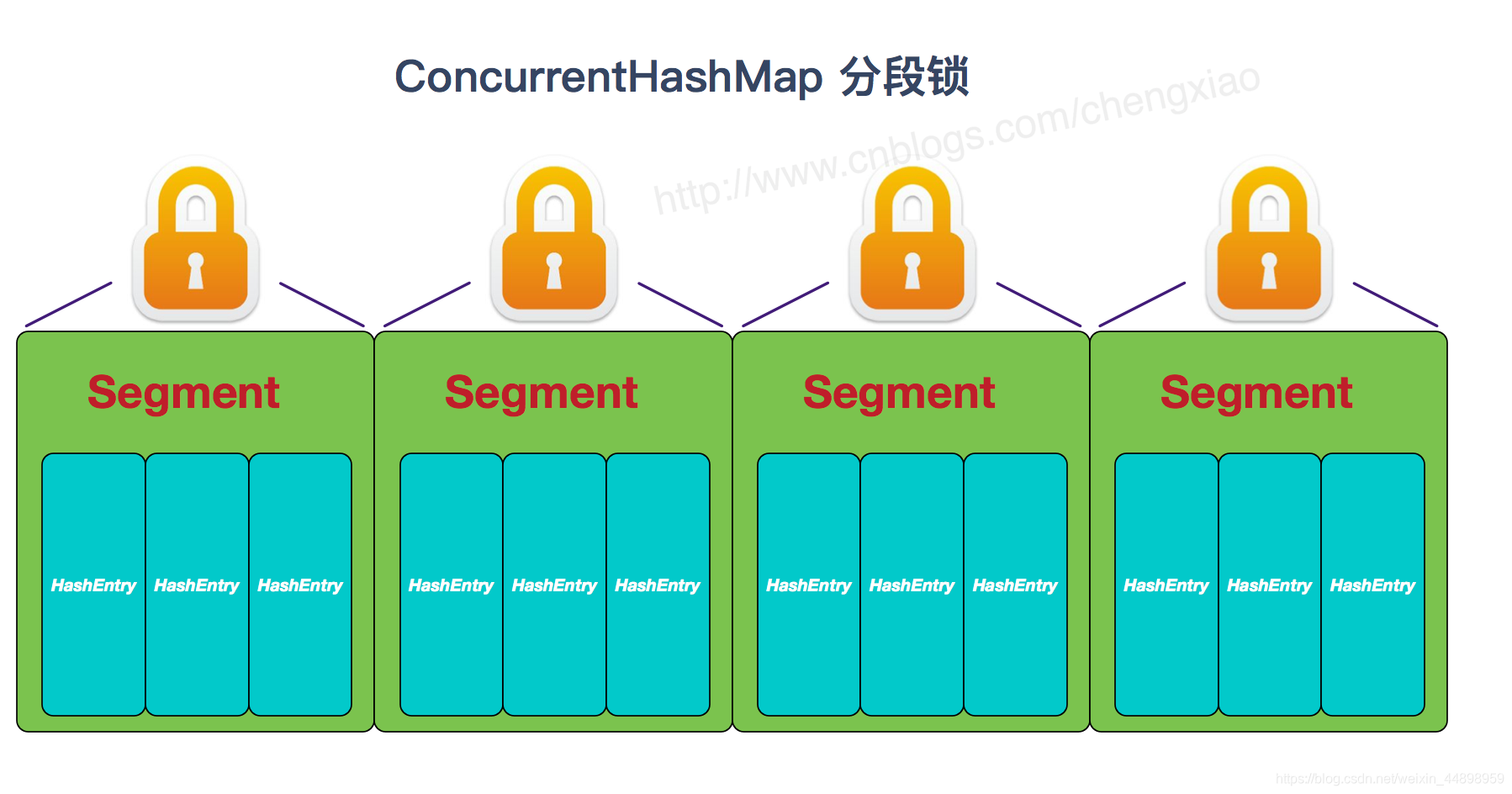
ConcurrentHashMap采用了非常精妙的"分段锁"策略,ConcurrentHashMap的主干是个Segment数组。
final Segment<K,V>[] segments;
Segment继承了ReentrantLock,所以它就是一种可重入锁(ReentrantLock)。在ConcurrentHashMap,一个Segment就是一个子哈希表,Segment里维护了一个HashEntry数组,并发环境下,对于不同Segment的数据进行操作是不用考虑锁竞争的。(就按默认的ConcurrentLeve为16来讲,理论上就允许16个线程并发执行,有木有很酷)
所以,对于同一个Segment的操作才需考虑线程同步,不同的Segment则无需考虑。
Segment类似于HashMap,一个Segment维护着一个HashEntry数组
transient volatile HashEntry<K,V>[] table;
HashEntry是目前我们提到的最小的逻辑处理单元了。一个ConcurrentHashMap维护一个Segment数组,一个Segment维护一个HashEntry数组。
我们说Segment类似哈希表,那么一些属性就跟我们之前提到的HashMap差不离,比如负载因子loadFactor,比如阈值threshold等等,看下Segment的构造方法
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;//负载因子
this.threshold = threshold;//阈值
this.table = tab;//主干数组即HashEntry数组
}
我们来看下ConcurrentHashMap的构造方法
1 public ConcurrentHashMap(int initialCapacity,
2 float loadFactor, int concurrencyLevel) {
3 if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
4 throw new IllegalArgumentException();
5 //MAX_SEGMENTS 为1<<16=65536,也就是最大并发数为65536
6 if (concurrencyLevel > MAX_SEGMENTS)
7 concurrencyLevel = MAX_SEGMENTS;
8 //2的sshif次方等于ssize,例:ssize=16,sshift=4;ssize=32,sshif=5
9 int sshift = 0;
10 //ssize 为segments数组长度,根据concurrentLevel计算得出
11 int ssize = 1;
12 while (ssize < concurrencyLevel) {
13 ++sshift;
14 ssize <<= 1;
15 }
16 //segmentShift和segmentMask这两个变量在定位segment时会用到,后面会详细讲
17 this.segmentShift = 32 - sshift;
18 this.segmentMask = ssize - 1;
19 if (initialCapacity > MAXIMUM_CAPACITY)
20 initialCapacity = MAXIMUM_CAPACITY;
21 //计算cap的大小,即Segment中HashEntry的数组长度,cap也一定为2的n次方.
22 int c = initialCapacity / ssize;
23 if (c * ssize < initialCapacity)
24 ++c;
25 int cap = MIN_SEGMENT_TABLE_CAPACITY;
26 while (cap < c)
27 cap <<= 1;
28 //创建segments数组并初始化第一个Segment,其余的Segment延迟初始化
29 Segment<K,V> s0 =
30 new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
31 (HashEntry<K,V>[])new HashEntry[cap]);
32 Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
33 UNSAFE.putOrderedObject(ss, SBASE, s0);
34 this.segments = ss;
35 }
初始化方法有三个参数,如果用户不指定则会使用默认值,initialCapacity为16,loadFactor为0.75(负载因子,扩容时需要参考),concurrentLevel为16。
从上面的代码可以看出来,Segment数组的大小ssize是由concurrentLevel来决定的,但是却不一定等于concurrentLevel,ssize一定是大于或等于concurrentLevel的最小的2的次幂。比如:默认情况下concurrentLevel是16,则ssize为16;若concurrentLevel为14,ssize为16;若concurrentLevel为17,则ssize为32。为什么Segment的数组大小一定是2的次幂?其实主要是便于通过按位与的散列算法来定位Segment的index。
接下来,我们来看看put方法
public V put(K key, V value) {
Segment<K,V> s;
//concurrentHashMap不允许key/value为空
if (value == null)
throw new NullPointerException();
//hash函数对key的hashCode重新散列,避免差劲的不合理的hashcode,保证散列均匀
int hash = hash(key);
//返回的hash值无符号右移segmentShift位与段掩码进行位运算,定位segment
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
从源码看出,put的主要逻辑也就两步:1.定位segment并确保定位的Segment已初始化 2.调用Segment的put方法。
关于segmentShift和segmentMask
segmentShift和segmentMask这两个全局变量的主要作用是用来定位Segment,int j =(hash >>> segmentShift) & segmentMask。
segmentMask:段掩码,假如segments数组长度为16,则段掩码为16-1=15;segments长度为32,段掩码为32-1=31。这样得到的所有bit位都为1,可以更好地保证散列的均匀性
segmentShift:2的sshift次方等于ssize,segmentShift=32-sshift。若segments长度为16,segmentShift=32-4=28;若segments长度为32,segmentShift=32-5=27。而计算得出的hash值最大为32位,无符号右移segmentShift,则意味着只保留高几位(其余位是没用的),然后与段掩码segmentMask位运算来定位Segment。
get/put方法
public V get(Object key) {
Segment<K,V> s;
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
//先定位Segment,再定位HashEntry
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
get方法无需加锁,由于其中涉及到的共享变量都使用volatile修饰,volatile可以保证内存可见性,所以不会读取到过期数据。
来看下concurrentHashMap代理到Segment上的put方法,Segment中的put方法是要加锁的。只不过是锁粒度细了而已。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);//tryLock不成功时会遍历定位到的HashEnry位置的链表(遍历主要是为了使CPU缓存链表),若找不到,则创建HashEntry。tryLock一定次数后(MAX_SCAN_RETRIES变量决定),则lock。若遍历过程中,由于其他线程的操作导致链表头结点变化,则需要重新遍历。
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;//定位HashEntry,可以看到,这个hash值在定位Segment时和在Segment中定位HashEntry都会用到,只不过定位Segment时只用到高几位。
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
//若c超出阈值threshold,需要扩容并rehash。扩容后的容量是当前容量的2倍。这样可以最大程度避免之前散列好的entry重新散列,具体在另一篇文章中有详细分析,不赘述。扩容并rehash的这个过程是比较消耗资源的。
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
Executor框架
我们用线程来完成异步任务,一开始,java的线程即使任务单元,也是执行单元,体现在Thread类同时拥有run方法(任务内容)和start方法(执行任务)。Executor将任务和执行解耦。任务单元包括Runnable和Callable。而执行机制由Executor提供
Callable
Callable和Runnable一样是任务单位。不同的是Callable在任务完成后有返回值,并且可以抛出异常
public class CallableTest implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("call启动");
return 1;
}
}
为了兼容性,Callable不可以直接交给线程运行,而是需要一个实现了Runnable的适配类
Future
Future和实现它的FutureTask类表示异步执行的结果
FutureTask
使用Future.get可以阻塞获得任务完成时返回的结果
CallableTest callableTest = new CallableTest();
//FutureTask是适配类,FutureTask实现了runnable接口
FutureTask<Integer> futureTask = new FutureTask<>(callableTest);
new Thread(futureTask).start();
try {
//使用futureTask.get获得返回结果
//get会阻塞等待结果返回
//futureTask的结果会有缓存
//多个线程执行同一个futuretask,那么只会计算一次
Integer integer = futureTask.get();
System.out.println(integer);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
CompletableFuture
CompletableFuture弥补了Future获取任务结果时会阻塞的缺点,如果有其他任务需要上一个任务的结果,可以直接通过thenAccept、thenApply、thenCompose等方式将前面异步处理的结果交给另外一个异步事件处理线程来处理。
public class CompletableFutureDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Void> async = CompletableFuture.runAsync(() -> {
System.out.println("异步执行一个线程");
});
CompletableFuture<Integer> supplyAsync = CompletableFuture.supplyAsync(() -> {
System.out.println("异步执行一个线程,成功后返回");
int a = 10/0;
return 1024;
});
System.out.println(supplyAsync.get());
CompletableFuture<Integer> thenApply = CompletableFuture.supplyAsync(() -> {
return 1;
}).thenApply((t) -> {
return t + 1;
});
System.out.println(thenApply.get());
/*whenComplete((t,u))任务完成时怎么做
exceptionally(f)出异常时怎么做
*/
supplyAsync.whenComplete((t,u)->{
//whenComplete((t,u)
System.out.println(t);//t:任务正常完成,返回任务返回的结果
System.out.println(u);//u:任务出异常,返回异常
}).exceptionally(f->{
System.out.println("***"+f.getMessage());
return -1;
});
/*
CompletableFutures是JAVA8里面引入的。
这个API有Future的优点,并且弥补了其缺点。即异步的任务完成后,需要用其结果继续操作时,无需等待。
可以直接通过thenAccept、thenApply、thenCompose等方式将前面异步处理的结果交给另外一个异步事件处理线程来处理。
*/
}
}
Executor接口
Executor接口的派生类就是Executor框架的执行单元,ExecutorService继承Executor接口,AbstractExecutorService实现ExecutorService,是所有线程池的基类。
我们可以手动继承AbstractExecutorService实现自己的线程池。
ThreadPoolExecutor
ThreadPoolExecutor线程池是Executor框架最核心的执行单位,一般池化技术的优点就是资源利用率高。
阿里巴巴开发手册要求开发人员在创建ThreadPookExecutor时必须使用全参构造
//线程池7个参数
public ThreadPoolExecutor(int corePoolSize,核心线程数,线程池初始化时就存在的线程
int maximumPoolSize,线程池能容纳的最大线程数。当任务队列满了,且池中线程数还小于max,再来任务时,就会再新开线程处理刚来的任务!
long keepAliveTime,多余线程的存活时间,即core线程之外的线程
TimeUnit unit,多余线程的存活时间的单位
BlockingQueue<Runnable> workQueue,一个阻塞队列,用来存放任务
ThreadFactory threadFactory, 线程创建工厂,一般自定义一个可以指定线程名的
RejectedExecutionHandler handler) 拒绝策略,线程池满了之后,再进来的任务只能采取拒绝策略
/*
线程池拒绝策略 1. )new ThreadPoolExecutor.AbortPolicy()该拒绝策略为:线程池满了,还有人进来,不处理这个人的,并抛出异常
2.new ThreadPoolExecutor.CallerRunsPolicy():** //该拒绝策略为:哪来的去哪里 哪个线程调用哪个线程执行
3.new ThreadPoolExecutor.DiscardPolicy():** //该拒绝策略为:队列满了,丢掉异常,不会抛出异常。
4.new ThreadPoolExecutor.DiscardOldestPolicy():** //该拒绝策略为:队列满了,抛弃队列中等待最久的任务
*/
线程池在执行提交的任务时的策略:当任务提交时,如果核心线程有空闲就交给核心线程,没有就进队列阻塞,如果队列满了就开额外线程处理这个任务,如果额外线程满了就执行拒绝。
向线程池提交任务
我们可以使用ThreadPoolExecutor.execute(Runnable a)或submit(Callable c)来提交任务,不同的是,使用submit回返回一个FutureTask。上面我们已经说到了FutureTask的使用方法,不再赘述了。
关闭线程池
可以通过线程池的shutdown和shutdownNow方法关闭线程池。它们的原理是:
遍历池中所有线程,调用interrupt方法中断,而无法响应中断的线程可能永远无法停止。
区别是:
shoutdownNow首先将线程池的状态设置成STOP,然后尝试停止所有正在执行或暂停任务的线程,返回等待执行任务的列表,
而shutdown只是将线程池的状态设置成shutdown状态,然后中断所有没有正在执行任务的线程。
这里我们补充一点Thread.interrupt的知识
interrupt是调用操作系统中unpark方法唤醒线程,并修改中断标记。而对于是否响应标记,则是JVM实现的,不同场景下的做法也不同
Locksupport.park,Object.wait,Thread.sleep会响应中断,Object.wait,Thread.sleep会抛出异常,抛出异常后中断标记又被设置成false
synchronized不会响应中断
线程池的监控
我们可以获取线程池的如下属性来监控线程池
| 属性 | 描述 |
|---|---|
| taskCount | 线程池所要执行的任务数量 |
| completedTaskCount | 线程池在运行中已经完成的任务数量 |
| largestPoolsize | 线程池创建过的最大线程的数量,可以知道线程池是不是满过 |
| getPoolSize | 线程池的线程数量 |
| getActiveCount | 获取获得的线程数 |
Tools
JUC的工具类们
CountDownLatch
允许一个或多个线程等待直到其他线程中执行的一组操作完成的同步辅助
可以理解为减法计数器
主要方法:
countDownLatch.countDown();//计数器数量减1
countDownLatch.await();//等待计数器归0
Demo:
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(6);//new一个减法计数器
for (int i = 0; i <6 ; i++) {
new Thread(()->{
System.out.println(Thread.currentThread().getName());
System.out.println("计数器数量"+countDownLatch.getCount());
countDownLatch.countDown();//计数器值减一
},String.valueOf(i)).start();
}
try {
countDownLatch.await();//等待计数器归0
System.out.println("关门");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
CyclicBarrier
可以理解为加法计数器
Demo
CyclicBarrier cyclicBarrier = new CyclicBarrier(7,()->{
System.out.println("召唤神龙");
});
for (int i = 0; i <7; i++) {
final int t = i;
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"现在的龙珠数量:"+(t+1));
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
},String.valueOf(t)).start();
}
Semaphore
信号量 PV操作
主要方法:
semaphore.acquire();//获得一个信号量,得不到就会阻塞
semaphore.release();//释放一个信号量
作用:并发限流
Demo
Semaphore semaphore = new Semaphore(3);
for (int i = 0; i <6 ; i++) {
new Thread(()->{
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName()+"得到一个信号量");
TimeUnit.SECONDS.sleep(2);
System.out.println("释放信号量");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
semaphore.release();
}
}).start();
}
Executors
Executors工具类主要用于三种线程池的创建,但一般我们不用它
//注意 不可用Executors创建线程,应为它的任务队列是LinkedBlockQueue,他的默认最大容量是inter.MAX_VALUE
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(8);//一池5个处理线程
Executors.newSingleThreadExecutor();//一池一线程
Executors.newCachedThreadPool();//一池n个线程
Atomic原子操作类
当程序更新一个变量时,通常会伴随三个指令,取值,计算,赋值,显然是线程不安全的。
JDK提供了Atomic包,这个包中的原子类采用自旋地方式保证线程安全。
Atomic总共存在4种类型的原子更新方式,分别是原子更新基本类型,原子更新数组,原子更新引用和原子更新属性

















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









