







现代Web服务
Web⼯作⽅式
浏览器本身是⼀个客户端,当你输⼊URL的时候,⾸先浏览器会去请求DNS服务器,通过DNS获取相应的域名对应的IP,然后通过IP地址找到IP对应的服务器后,要求建⽴TCP连接,等浏览器发送完HTTP Request(请求)包后,服务器接收到请求包之后才开始处理请求包,服务器调⽤⾃身服务,返回HTTP Response(响应)包;客户端收到来⾃服务器的响应后开始渲染这个Response包⾥的主体(body),等收到全部的内容随后断开与该服务器之间的TCP连接。
简单归纳为:
-
客户端通过TCP/IP协议建⽴到服务器的TCP连接
-
客户端向服务器发送HTTP协议请求包,请求服务器⾥的资源⽂档
-
服务器向客户端发送HTTP协议应答包,如果请求的资源包含有动态语⾔的内容,那么服务器会调⽤动态语⾔ 的解释引擎负责处理“ 动态内容”,并将处理得到的数据返回给客户端
-
客户端与服务器断开。由客户端解释HTML⽂档,在客户端屏幕上渲染图形结果
需要注意的是客户端与服务器之间的通信是⾮持久连接的,也就是当服务器发送了应答后就与客户端断开连接,等待下⼀次请求。
URL和DNS解析
URL
-
URL:⽤于描述⼀个⽹络 上的资源
scheme://host[:port#]/path/…/[?query-string][#anchor]scheme:指定低层使⽤的协议(例如: http, https, ftp) host:HTTP服务器的I P地址或者域名 port#:HTTP服务器的默认端⼝是80,这种情况下端⼝号可以省略。如果使⽤了别的端⼝,必须指明,例 path:访问资源的路径 query-string:发送给http服务器的数据 anchor:锚
举例:http://mail.163.com/index.html
http://:这个是协议,也就是HTTP超⽂本传输协议,也就是⽹⻚在⽹上传输的协议。
mail:这个是服务器名,代表着是⼀个邮箱服务器,所以是mail.
163.com:这个是域名,是⽤来定位⽹站的ᇿ⼀⽆⼆的名字。
mail.163.com:这个是⽹站名,由服务器名+域名组成。
/:这个是根⽬录,也就是说,通过⽹站名找到服务器,然后在服务器存放⽹⻚的根⽬录
index.html:这个是根⽬录下的默认⽹⻚(当然,163的默认⽹⻚是不是这个我不知道,只是⼤部分的默认⽹⻚,都是index.html)
DNS
-
DNS (Domain Name System)城名系统⽤于TCP/IP⽹络,它从事将主机名或域名转换为实际IP地址的⼯作
-
DNS解析过程
1. 浏览器中输⼊域名,操作系统会先检查⾃⼰本地的hosts⽂件是否有这个⽹络映射关系,如果有,就先调⽤这个IP地址映射,完成域名解析。 2. 如果hosts没有域名,查找本地DNS解析器缓存,如果有直接返回,完成域名解析。 3. 如果还没找到,会查找TCP/IP参数中设置的⾸选DNS服务器,我们叫它本地DNS服务器,此服务收到查询时,如果要查询的域名包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析,此解析具有权威性。 4. 如果要查询的域名,不由本地DNS服务器区域解析,但该服务已经缓存了地址映射关系,则调⽤这个IP地址映射,完成域名解析,此解析不具有权威性。 5. 如果上述过程失败,则根据本地DNS服务器的设置进⾏查询,如果未⽤转发模式,则把请求发给根服务器,根服务器返回⼀个负责该顶级服务器的IP,本地DNS服务器收到IP信息后,再连接该IP上的服务器进⾏解析,如果仍然⽆法解析,则发送下⼀级DNS服务器,重复操作,直到找到。 6. 如果是转发模式则把请求转发⾄上⼀级DNS服务器,假如仍然不能解析,再转发给上上级。不管是否转发,最后都把结果返回给本地DNS服务器。
上述⼀个是迭代查询,⼀个是递归查询。递归查询的
过程是查询者发⽣了更替,⽽迭代查询过程,查询者不变。
HTTP协议
介绍
- HTTP协议是Hyper Text Transfer Protocol(超⽂本传输协议)的缩写是⼀个基于TCP/IP通信协议来传递数据,服务器传输超⽂本到本地浏览器的传送协议。
HTTP请求包
结构:由 请求⾏(request line)、请求头部(header)、空⾏和请求数据四个部分组成。
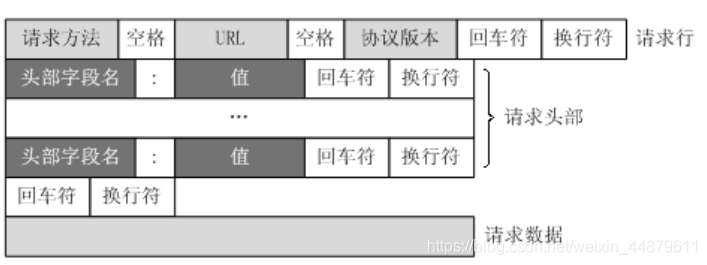
第⼀部分:请求⾏,⽤来说明请求类型,要访问的资源以及所使⽤的HTTP版本
第⼆部分:请求头部,紧接着请求⾏(即第⼀⾏)之后的部分,⽤来说明服务器要使⽤的附加信息
第三部分:空⾏,请求头部后⾯的空⾏是必须的
第四部分:请求数据也叫主体,可以添加任意的其他数据
请求包举例
GET http://edu.kongyixueyuan.com/ HTTP/1.1 //请求⾏: 请求⽅法请求URIHTTP协议/ 协议版本
Accept: application/x-ms-application, image/jpeg, application/xaml+xml,image/gif, image/pjpeg,application/x-ms-xbap, /
//客户端能接收的数据格式
Accept-Language: zh-CN
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64;
Trident/4.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729;
Media Center PC 6.0; .NET4.0C; .NET4.0E)
UA-CPU: AMD64
Accept-Encoding: gzip, deflate //是否⽀持流压缩
Host: edu.kongyixueyuan.com //服务端的主机名
Connection: Keep-Alive
//空⾏,⽤于分割请求头和消息体
//消息体,请求资源参数,例如POST传递的参数
HTTP响应包
也由四个部分组成,分别是:状态⾏、消息报头、空⾏和响应正⽂。

第⼀部分:状态⾏,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
第⼆部分:消息报头,⽤来说明客户端要使⽤的⼀些附加信息
第三部分:空⾏,消息报头后⾯的空⾏是必须的
第四部分:响应正⽂,服务器返回给客户端的⽂本信息
响应包举例
HTTP/1.1 200 OK //状态⾏
Server: nginx //服务器使⽤的WEB软件名及版本
Content-Type: text/html; charset=UTF-8 //服务器发送信息的类型
Connection: keep-alive //保持连接状态
Set-Cookie: PHPSESSID=mjup58ggbefu7ni9jea7908kub; path=/; HttpOnly
Cache-Control: no-cache
Date: Wed, 14 Nov 2018 08:27:32 GMT //发送时间
Content-Length: 99324 //主体内容⻓度
//空⾏⽤来分割消息头和主体
... //消息体HTTP拓展
HTTP协议是⽆状态的和Connection: keep alive的区别 ⽆状态是指协议对于事务处理没有记忆能⼒,服
务器不知道客户端是什么状态。从另⼀⽅⾯讲,打开⼀个服务器上的⽹⻚和你之前打开这个服务器上的
⽹⻚之间没有任何联系。 HTTP是⼀个⽆状态的⾯向连接的协议,⽆状态不代表HTTP不能保持TCP连
接,更不能代表HTTP使⽤的是UDP协议(⾯对⽆连接)。 从HTTP/1.1起,默认都开启了Keep-Alive保持
连接特性,简单地说,当⼀个⽹⻚打开完成后,客户端和服务器之间⽤于传输HTTP数据的TCP连接不会
关闭,如果客户端再次访问这个服务器上的⽹⻚,会继续使⽤这⼀条已经建⽴的TCP连接。 Keep-Alive
不会永久保持连接,它有⼀个保持时间,可以在不同服务器软件(如Apache) 中设置这个时间。
请求⽅法
根据HTTP标准,HTTP请求可以使⽤多种请求⽅法。 HTTP1.0定义了三种请求⽅法: GET, POST 和HEAD⽅法。 HTTP1.1新增了五种请求⽅法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT ⽅法。
GET 请求指定的⻚⾯信息,并返回实体主体。
HEAD 类似于get请求,只不过返回的响应中没有具体的内容,⽤于获取报头
POST 向指定资源提交数据进⾏处理请求(例如提交表单或上传⽂件)。数据被包含在请求体中。POST请求可能会导致新的资源的建⽴和/或已有资源的修改。
PUT 从客户端向服务器传送的数据取代指定的⽂档的内容。
DELETE 请求服务器删除指定的⻚⾯。
CONNECT HTTP/1.1协议中预留给能够将连接改为管道⽅式的代理服务器。
OPTIONS 允许客户端查看服务器的性能。
TRACE 回显服务器收到的请求,主要⽤于测试或诊断。
拓展:GET和POST的区别
GET在浏览器回退时是⽆害的,⽽POST会再次提交请求。
GET产⽣的URL地址可以被Bookmark,⽽POST不可以。
GET请求会被浏览器主动cache,⽽POST不会,除⾮⼿动设置。
GET请求只能进⾏url编码,⽽POST⽀持多种编码⽅式。
GET请求参数会被完整保留在浏览器历史记录⾥,⽽POST中的参数不会被保留。
GET请求在URL中传送的参数是有⻓度限制的,⽽POST没有。
对参数的数据类型,GET只接受ASCII字符,⽽POST没有限制。
GET⽐POST更不安全,因为参数直接暴露在URL上,所以不能⽤来传递敏感信息。
GET参数通过URL传递,POST放在Request body中。
HTTP的底层是TCP/IP。所以GET和POST的底层也是TCP/IP,也就是说,GET/POST都是TCP链接。GET
产⽣⼀个TCP数据包;POST产⽣两个TCP数据包。对于GET⽅式的请求,浏览器会把http header和data
⼀并发送出去,服务器响应200(返回数据);⽽对于POST,浏览器先发送header,服务器响应100
continue,浏览器再发送data,服务器响应200 ok(返回数据))
HTTPS通信原理
服务器 ⽤RSA⽣成公钥和私钥把公钥放在证书⾥发送给客户端,私钥⾃⼰保存客户端⾸先向⼀个权威的
服务器检查证书的合法性,如果证书合法,客户端产⽣⼀段随机数,这个随机数就作为通信的密钥,我
们称之为对称密钥,⽤公钥加密这段随机数,然后发送到服务器服务器⽤密钥解密获取对称密钥,然
后,双⽅就已对称密钥进⾏加密解密通信了。
Https的作用
内容加密 建⽴⼀个信息安全通道,来保证数据传输的安全;
身份认证 确认⽹站的真实性
数据完整性 防⽌内容被第三⽅冒充或者篡改
Https和Http的区别
https协议需要到CA申请证书。
http是超⽂本传输协议,信息是明⽂传输;https 则是具有安全性的ssl加密传输协议。
http和https使⽤的是完全不同的连接⽅式,⽤的端⼝也不⼀样,前者是80,后者是443。
http的连接很简单,是⽆状态的;HTTPS协议是由SSL+HTTP协议构建的可进⾏加密传输、身份认证的⽹络协议,⽐http协议安全。
Socket
背景
网络种可以利⽤ip地址+协议+端⼝号唯⼀标示⽹络中的⼀个进程。
Socket介绍
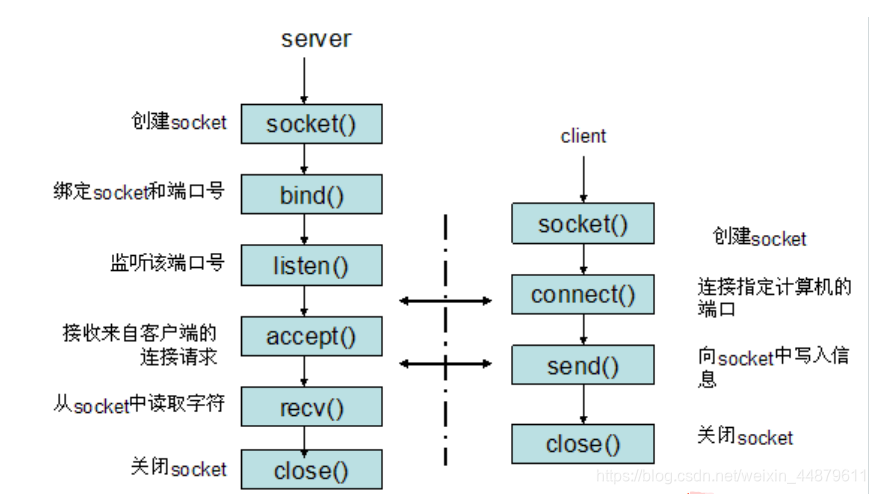
socket是在应⽤层和传输层之间的⼀个抽象层,它把TCP/IP层复杂的操作抽象为⼏个简单的接⼝供应⽤层调⽤已实现进程在⽹络中通信
socket起源于UNIX,在Unix⼀切皆⽂件哲学的思想下,socket是⼀种"打开—读/写—关闭"模式的实现,服务器和客户端各⾃维护⼀个"⽂件",在建⽴连接打开后,可以向⾃⼰⽂件写⼊内容供对⽅读取或者读取对⽅内容,通讯结束时关闭⽂件。
代码举例
举例图
举例代码
服务端
// tcp/server/main.go
package Server
import (
"bufio"
"fmt"
"net"
)
func process(conn net.Conn) {
defer conn.Close() // 关闭连接
for {
reader := bufio.NewReader(conn)
var buf [128]byte
n, err := reader.Read(buf[:]) // 读取数据
if err != nil {
fmt.Println("read from client failed, err:", err)
break
}
recvStr := string(buf[:n])
fmt.Println("收到client端发来的数据:", recvStr)
conn.Write([]byte(recvStr)) // 发送数据
}
}
func main() {
listen, err := net.Listen("tcp", "127.0.0.1:20000")
if err != nil {
fmt.Println("listen failed, err:", err)
return
}
for {
conn, err := listen.Accept() // 建⽴连接
if err != nil {
fmt.Println("accept failed, err:", err)
continue
}
go process(conn) // 启动⼀个goroutine处理连接
}
}
client端
// tcp/client/main.go
// 客户端
package Clicent
import (
"bufio"
"fmt"
"net"
"os"
"strings"
)
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:20000")
if err != nil {
fmt.Println("err :", err)
return
}
defer conn.Close() // 关闭连接
inputReader := bufio.NewReader(os.Stdin)
for {
input, _ := inputReader.ReadString('\n') // 读取⽤户输⼊
inputInfo := strings.Trim(input, "\r\n")
if strings.ToUpper(inputInfo) == "Q" { // 如果输⼊q就退出
return
}
_, err = conn.Write([]byte(inputInfo)) // 发送数据
if err != nil {
return
}
buf := [512]byte{}
n, err := conn.Read(buf[:])
if err != nil {
fmt.Println("recv failed, err:", err)
return
}
fmt.Println(string(buf[:n]))
}
}
WebSocket
WebSocket protocol 是HTML5⼀种新的协议。它实现了浏览器与服务器全双⼯通信,能更好的节省服
务器资源和带宽并达到实时通讯它建⽴在TCP之上,同 HTTP⼀样通过TCP来传输数据。WebSocket同
HTTP⼀样也是应⽤层的协议,并且⼀开始的握⼿也需要借助HTTP请求完成。
- 特点:建立连接后,是实时通讯的了,不同与http,接受数据后就关闭的通讯。
RPC
Remote Procedure Call 远程过程调⽤ 它是⼀种通过⽹络从远程计算机程序上请求服务,⽽不需
要了解底层⽹络技术的协议。
⼀个完整的RPC架构⾥⾯包含了四个核⼼的组件,分别是Client,Server,Client Stub以及Server Stub(Stub是存根).
- 客户端(Client),服务的调⽤⽅。
- 服务端(Server),真正的服务提供者。
- 客户端存根,存放服务端的地址消息,再将客户端的请求参数打包成⽹络消息,然后通过⽹络远程发送给服务⽅。
- 服务端存根,接收客户端发送过来的消息,将消息解包,并调⽤本地的⽅法
RPC 与 HTTP
RPC更是⼀个软件结构概念,是构建分布式应⽤的理论基础。就好⽐为啥你家可以⽤到发电⼚发出
来的电?是因为电是可以传输的。⾄于⽤铜线还是⽤铁丝还是其他 种类的导线,也就是⽤http还
是⽤其他协议的问题了。
Rest & Restful
Rest全称是Representational State Transfer,中⽂意思是表述性状态转移。Rest指的是⼀组架构
约束条件和原则。如果⼀个架构符合Rest的约束条件和原则,我们就称它为Restful架构。
Rest架构的主要原则
- 在Rest中的⼀切都被认为是⼀种资源。
- 每个资源由URI标识。
- 使⽤统⼀的接⼝。处理资源使⽤POST,GET,PUT,DELETE操作类似创建,读取,更新和删除(CRUD)操作。
- ⽆状态:每个请求是⼀个独⽴的请求。从客户端到服务器的每个请求都必须包含所有必要的信息,以便于理解。
- 同⼀个资源具有多种表现形式,例如XML,JSON
Go Hello Web!
package main
import (
"fmt"
"log"
"net/http"
)
func hello(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, Web!")
}
func main() {
http.HandleFunc("/", hello)
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatal(err)
}
}
解析:
http.HandleFunc 将 hello 函数注册到根路径 / 上, hello 函数我们也叫做处理器。它接收两个参数:
- 第⼀个参数为⼀个类型为 http.ResponseWriter 的接⼝,响应就是通过它发送给客户端的。
- 第⼆个参数是⼀个类型为 http.Request 的结构指针,客户端发送的信息都可以通过这个结构获取。
http.ListenAndServe 将在 8080 端⼝上监听请求,最后交由 hello 处理。
多路复用器
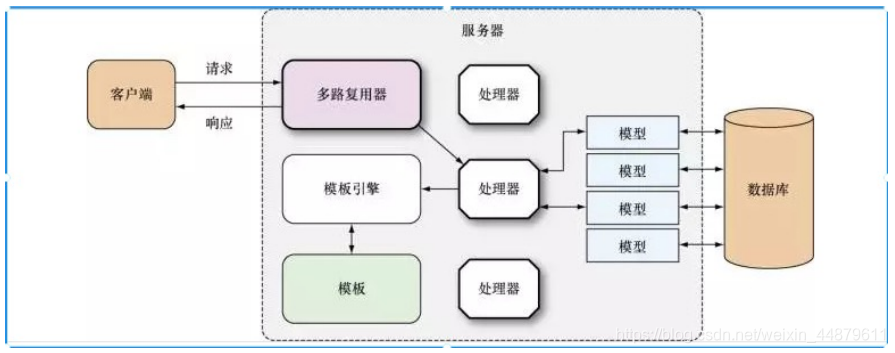
流程:
- 客户端发送请求;
- 服务器中的多路复⽤器收到请求;
- 多路复⽤器根据请求的 URL 找到注册的处理器,将请求交由处理器处理;
- 处理器执⾏程序逻辑,必要时与数据库进⾏交互,得到处理结果;
- 处理器调⽤模板引擎将指定的模板和上⼀步得到的结果渲染成客户端可识别的数据格式(通常是HTML);
- 最后将数据通过响应返回给客户端;
- 客户端拿到数据,执⾏对应的操作,例如渲染出来呈现给⽤户。
net/http 包内置了⼀个默认的多路复⽤器 DefaultServeMux
net/http 包中很多⽅法都在内部调⽤DefaultServeMux 的对应⽅法,如 HandleFunc 。我们知道, HandleFunc 是为指定的 URL 注册⼀个处理器(准确来说, hello 是处理器函数,⻅下⽂)。其内部实现如下:
// src/net/http/server.go
func HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
DefaultServeMux.HandleFunc(pattern, handler)
}
实际上, http.HandleFunc ⽅法是将处理器注册到 DefaultServeMux 中的。
另外,我们使⽤ “:8080” 和 nil 作为参数调⽤ http.ListenAndServe 时,会创建⼀个默认的服务器:
// src/net/http/server.go
func ListenAndServe(addr string, handler Handler) {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
这个服务器默认使⽤ DefaultServeMux 来处理器请求:
type serverHandler struct {
srv *Server
}
func (sh serverHandler) ServeHTTP(rw ResponseWriter, req *Request) {
handler := sh.srv.Handler
if handler == nil {
handler = DefaultServeMux
}
handler.ServeHTTP(rw, req)
}
创建多路复用器
直接调⽤ http.NewServeMux ⽅法即可。然后,在新创建的多路复⽤器上注册处理器。
package main
import (
"fmt"
"log"
"net/http"
)
func hello(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, Web")
}
func main() {
//创建Mux
mux := http.NewServeMux()
mux.HandleFunc("/", hello)
server := &http.Server{
Addr: ":8080",
Handler: mux, //注册处理器
}
if err := server.ListenAndServe(); err != nil {
log.Fatal(err)
}
}
处理器和处理器函数
服务器收到请求后,会根据其 URL 将请求交给相应的处理器处理。处理器实现了 Handler 接⼝的结
构, Handler 接⼝定义在 net/http 包中:
// src/net/http/server.go
type Handler interface {
func ServeHTTP(w Response.Writer, r *Request)
}
可以定义⼀个实现该接⼝的结构,注册这个结构类型的对象到多路复⽤器中:
package main
import (
"fmt"
"log"
"net/http"
)
type GreetingHandler struct {
Language string
}
func (h GreetingHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "%s", h.Language)
}
func main() {
mux := http.NewServeMux()
mux.Handle("/chinese", GreetingHandler{Language: "你好"})
mux.Handle("/english", GreetingHandler{Language: "Hello"})
server := &http.Server {
Addr: ":8080",
Handler: mux,
}
if err := server.ListenAndServe(); err != nil {
log.Fatal(err)
}
}
// src/net/http/server.go
func (mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter,
*Request)) {
if handler == nil {
panic("http: nil handler")
}
mux.Handle(pattern, HandlerFunc(handler))
}
虽然,⾃定义处理器这种⽅式⽐较灵活,强⼤,但是需要定义⼀个新的结构,实现 ServeHTTP ⽅法,还是⽐较繁琐的。
为了⽅便使⽤, net/http 包提供了以函数的⽅式注册处理器,即使⽤ HandleFunc 注册。函数必须满⾜签名: func (w http.ResponseWriter, r *http.Request) 。 这个函数称为处理器函数。 HandleFunc ⽅法内部,会将传⼊的处理器函数转换为 HandlerFunc 类型。
// src/net/http/server.go
func (mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter,
*Request)) {
if handler == nil {
panic("http: nil handler")
}
mux.Handle(pattern, HandlerFunc(handler))
}
HandlerFunc 是底层类型为 func (w ResponseWriter, r *Request) 的新类型,它可以⾃定义其⽅法。由于 HandlerFunc 类型实现了 Handler 接⼝,所以它也是⼀个处理器类型,最终使⽤ Handle 注册。
注意,这⼏个接⼝和⽅法名很容易混淆:
- Handler :处理器接⼝,定义在 net/http 包中。实现该接⼝的类型,其对象可以注册到多路复⽤器中;
- Handle :注册处理器的⽅法;
- HandleFunc :注册处理器函数的⽅法;
- HandlerFunc :底层类型为 func (w ResponseWriter, r *Request) 的新类型,实现了Handler 接⼝。它连接了处理器函数与处理器
URL匹配
如果注册的 URL 不是以 / 结尾的,那么它只能精确匹配请求的 URL。反之,即使请求的 URL 只有前缀与被绑定的 URL 相同, ServeMux 也认为它们是匹配的。
http 请求
请求的结构
处理器函数:
func (w http.ResponseWriter, r *http.Request)
- 结构
// src/net/http/request.go
type Request struct {
Method string //请求的方法类型
URL *url.URL // url
Proto string // 协议版本号
ProtoMajor int // 大版本号
ProtoMinor int // 小版本号
Header Header // 头部
Body io.ReadCloser
ContentLength int
// 省略⼀些字段...
}
Header头部
常⻅的⾸部有:
- Accept :客户端想要服务器发送的内容类型;
- Accept-Charset :表示客户端能接受的字符编码;
- Content-Length :请求主体的字节⻓度,⼀般在 POST/PUT 请求中较多;
- Content-Type :当包含请求主体的时候,这个⾸部⽤于记录主体内容的类型。在发送 POST 或
- PUT 请求时,内容的类型默认为 x-www-form-urlecoded 。但是在上传⽂件时,应该设置类型为 multipart/form-data 。
- User-Agent :⽤于描述发起请求的客户端信息,如什么浏览器。
Content-Length/Body
Content-Length 表示请求体的字节⻓度,请求体的内容可以从 Body 字段中读取。细⼼的朋友可能发现了 Body 字段是⼀个 io.ReadCloser 接⼝。在读取之后要关闭它,否则会有资源泄露。可以使⽤ defer 简化代码编写
func bodyHandler(w http.ResponseWriter, r *http.Request) {
data := make([]byte, r.ContentLength)
r.Body.Read(data) // 忽略错误处理
defer r.Body.Close()
fmt.Fprintln(w, string(data))
}
mux.HandleFunc("/body", bodyHandler)
直接在浏览器中输⼊ URL 发起的是 GET 请求,⽆法携带请求体。有很多种⽅式可以发起带请求体的请求,下⾯介绍两种:
表单
func indexHandler(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, `
<html>
<head>
<title>Go Web</title>
</head>
<body>
<form method="post" action="/body">
<label for="username">⽤户名:</label>
<input type="text" id="username" name="username">
<label for="email">邮箱:</label>
<input type="text" id="email" name="email">
<button type="submit">提交</button>
</form>
</body>
</html>
`)}
mux.HandleFunc("/", indexHandler)
- 提交后,会调用方法,进入到对应URL下的处理器函数,来进行操作,例如验证密码等等
调试工具
Postman
Postwoman
Paw
获取请求参数
URL 键值对
前⽂中介绍 URL 的⼀般格式时提到过,URL 的后⾯可以跟⼀个可选的查询字符串,以 ? 与路径分隔,
形如 key1=value1&key2=value2 。
URL 结构中有⼀个 RawQuery 字段。这个字段就是查询字符串
func queryHandler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, r.URL.RawQuery) }
mux.HandleFunc("/query", queryHandler)
如果我们以 localhost:8080/query?name=ls&age=20 请求,查询字符串 name=ls&age=20 会传回客户端。
表单
- action 表示提交表单时请求的 URL, method 表示请求的⽅法。如果使⽤ GET 请求,由于 GET ⽅法没有请求体,参数将会拼接到 URL 尾部;
- enctype 指定请求体的编码⽅式,默认为 application/x-www-form-urlencoded 。如果需要发送⽂件,必须指定为 multipart/form-data ;
Form 字段
使⽤ x-www-form-urlencoded 编码的请求体,在处理时⾸先调⽤请求的 ParseForm ⽅法解析,然后从 Form 字段中取数据:
func formHandler(w http.ResponseWriter, r *http.Request) {
r.ParseForm()
fmt.Fprintln(w, r.Form) }
mux.HandleFunc("/form", formHandler)
Form 字段的类型 url.Values 底层实际上是 map[string][]string 。调⽤ ParseForm ⽅法之后,可以使⽤ url.Values 的⽅法操作数据。
使⽤ ParseForm 还能解析查询字符串,将上⾯的表单改为:
<html>
<head>
<title>Go Web</title>
</head>
<body>
<form action="/form?lang=cpp&name=ls" method="post"
enctype="application/x-www-form-urlencoded">
<label>Form:</label>
<input type="text" name="lang" />
<input type="text" name="age" />
<button type="submit">提交</button>
</form>
</body>
</html>
PostForm 字段
如果⼀个请求,同时有 URL 键值对和表单数据,⽽⽤户只想获取表单数据,可以使⽤ PostForm 字段。
使⽤ PostForm 只会返回表单数据,不包括 URL 键值。
MultipartForm 字段
如果要处理上传的⽂件,那么就必须使⽤ multipart/form-data 编码。与之前的 Form/PostForm 类似,处理 multipart/form-data 编码的请求时,也需要先解析后使⽤。只不过使⽤的⽅法不同,解析使⽤ ParseMultipartForm ,之后从 MultipartForm 字段取值。
<form action="/multipartform?lang=cpp&name=dj" method="post"
enctype="multipart/form-data">
<label>MultipartForm:</label>
<input type="text" name="lang" />
<input type="text" name="age" />
<input type="file" name="uploaded" />
<button type="submit">提交</button>
</form>
func multipartFormHandler(w http.ResponseWriter, r *http.Request) {
r.ParseMultipartForm(1024)
fmt.Fprintln(w, r.MultipartForm)
fileHeader := r.MultipartForm.File["uploaded"][0]
file, err := fileHeader.Open()
if err != nil {
fmt.Println("Open failed: ", err)
return
}
data, err := ioutil.ReadAll(file)
if err == nil {
fmt.Fprintln(w, string(data))
} }
mux.HandleFunc("/multipartform", multipartFormHandler)
MultipartForm 包含两个 map 类型的字段,⼀个表示表单键值对,另⼀个为上传的⽂件信息。
使⽤表单中⽂件控件名获取 MultipartForm.File 得到通过该控件上传的⽂件,可以是多个。得到的是 multipart.FileHeader 类型,通过该类型可以获取⽂件的各个属性。
需要注意的是,这种⽅式⽤来处理⽂件。为了安全, ParseMultipartForm ⽅法需要传⼀个参数,表示最⼤使⽤内存,避免上传的⽂件占⽤空间过⼤
FormValue/PostFormValue
为了⽅便地获取值, net/http 包提供了 FormValue/PostFormValue ⽅法。它们在需要时会⾃动调⽤ ParseForm/ParseMultipartForm ⽅法。
FormValue ⽅法返回请求的 Form 字段中指定键的值。如果同⼀个键对应多个值,那么返回第⼀个。如果需要获取全部值,直接使⽤ Form 字段。下⾯代码将返回 hello 对应的第⼀个值:
fmt.Fprintln(w, r.FormValue("hello"))
PostFormValue ⽅法返回请求的 PostForm 字段中指定键的值。如果同⼀个键对应多个值,那么返回第⼀个。如果需要获取全部值,直接使⽤ PostForm 字段
注意: 当编码被指定为 multipart/form-data 时, FormValue/PostFormValue 将不会返回任何值,它们读取的是 Form/PostForm 字段,⽽ ParseMultipartForm 将数据写⼊ MultipartForm 字段。
http 响应
最简单的⽅式是通过 http.ResponseWriter 发送字符串给客户端。但是这种⽅式仅限于发送字符串.
ResponseWriter
func (w http.ResponseWriter, r *http.Request)
// src/net/http/
type ReponseWriter interface {
Header() Header
Write([]byte) (int, error)
WriteHeader(statusCode int) }



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









