







ICLR2022中正在openreview中的论文
https://openreview.net/pdf?id=TVHS5Y4dNvM
Opensource: https://github.com/tmp-iclr/convmixer.
摘要
尽管CNN多年来一直是视觉任务的主导架构,但最近的实验表明,基于Transformer的模型,尤其是ViT,在某些环境下可能超过其性能。
然而,由于Transformer中Self-attention二次方运行时间,ViT需要使用patch将图像的一小块区域组合成单个输入特征,以便应用于较大的图像。这就提出了一个问题:ViTs的性能是由于其强大的Transformer架构,还是由于使用patch作为输入表示?
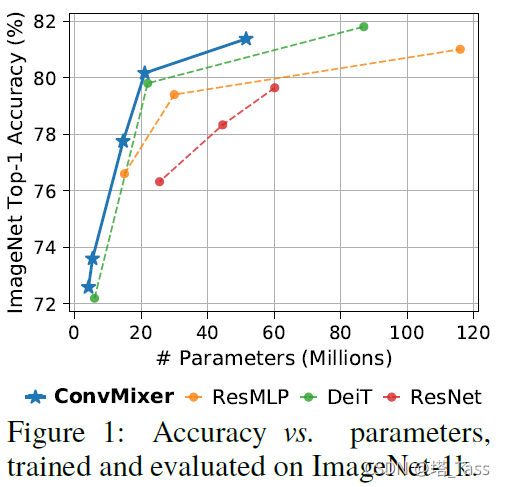
在本文中,我们为后者提供了一些证据:具体而言,我们提出了ConvMixer,这是一个极其简单的模型,类似于MLP-Mixer的思想,它直接对作为输入的patch进行操作,分离空间和通道的维度,并在整个网络中保持相同的大小和分辨率。然而,ConvMixer仅使用标准卷积来实现混合步骤。尽管它很简单,但我们发现,除了优于经典的视觉模型(如ResNet)外,ConvMixer在类似的参数量和数据集大小时优于ViT、MLP-Mixer及其一些变体。
1 简介
最近,基于Transformer模型的架构,例如ViT在许多此类任务中通常优于经典CNN架构,尤其是对于大型数据集。一个观点是,与在NLP中一样,Transformer成为CV领域的主导架构只是时间问题。然而,为了将Transformer应用于图像,必须改变表示方式:Transformer由于其二次方的复杂度不能在像素级别上天真地使用,一个折衷方案是首先将图像分割为多个“patches”,embedding它们,然后将Transformer encoder直接应用于这些patch token的集合。
一种观点认为,当数据集越来越大,CNN架构性能会陷入瓶颈,而Transformer的表示能力则能继续增强
在这项工作中,我们探讨的问题是,ViT的强大性是否更多地来自这种基于patches的表示,而不是来自transformer架构本身。我们开发了一种非常简单的卷积结构,我们称之为“ConvMixer”,因为它与最近提出的MLP-Mixer相似(Tolstikhin等人,2021年)。该体系结构在许多方面与Vision Transformer(和MLP Mixer)类似:它直接在patches上操作,在所有层中保持相同的分辨率和大小的表示,在连续层中不进行下采样,并且将“通道(channel-wise)Mixing”与“空间(spatial)Mixing”的信息分离。但与Vision Transformer和MLP Mixer不同,我们的体系结构仅通过标准卷积完成所有这些操作。

尽管它非常简单(仅需6行稠密的PyTorch代码,如上图),结果却优于“标准”计算机视觉模型,如相似参数量的ResNet和一些相应的ViT、MLP-Mix变体。这表明,至少在某种程度上,patches本身可能是“卓越”性能的最关键组件。我们相信这提供了一个强大的“Conv但基于patches”的baselines,并可以与更高级的体系结构进行比较。
2. ConvMixer
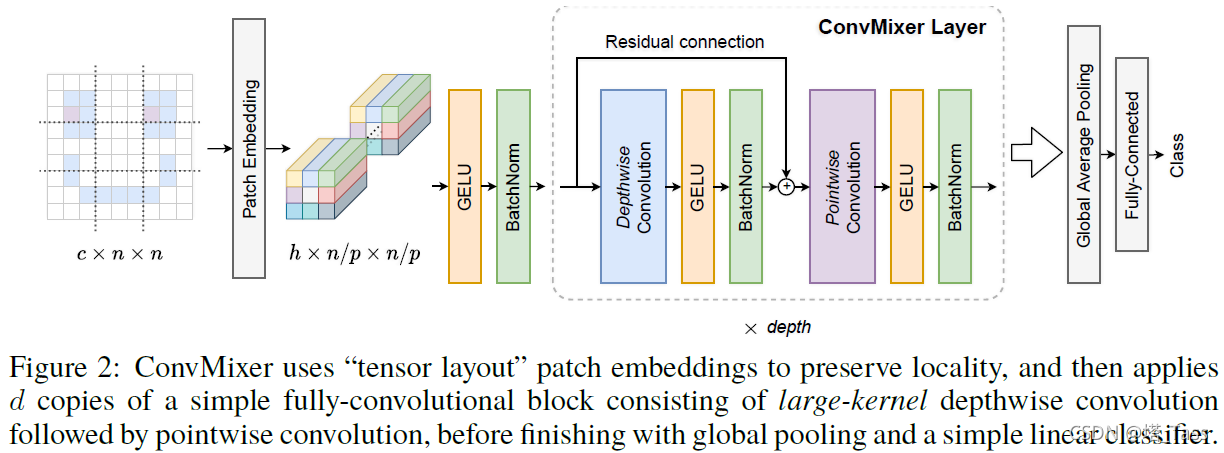
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 512
512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









