







#coding=utf8
#本次学习爬取中国大学排名
from bs4 import BeautifulSoup #导入beautifulsoup方法
import requests
import bs4 #导入bs4库,知否判断对象是否是这个类型可以用到
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#检查返回值是否是200
r.encoding=r.apparent_encoding#将编码等于内容编码
return r.text#返回text
except:
return ""#错误返回空
def fillUnivList(ulist,html):
soup=BeautifulSoup(html,'html.parser')#使用html.parser解析html
for tr in soup.find('tbody').children:#查找tbody下的子节点(因为tr可能在其他地方也有,所以不能单独只定位tr)
if isinstance(tr,bs4.element.Tag):#isinstance() 函数来判断一个对象tr是否是一个已知的类型bs4的tag类型,类似 type()。
tds=tr('td')#tr标签下的td
ulist.append([tds[0].string,tds[1].string,tds[4].string])#将td的第0,1,4个值写入列表
def printUnivList(ulist,num):
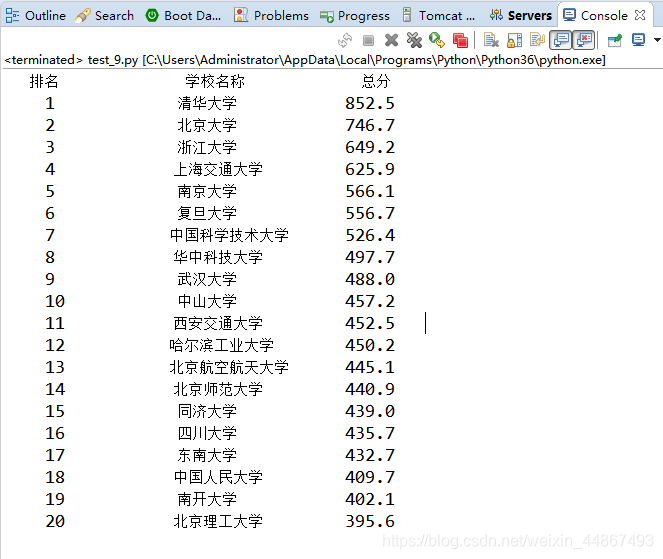
print("{:^15}\t{:^15}\t{:^20}".format("排名","学校名称","总分"))#打印一个头部,每一个约束宽度为指定的数字,\t表示空四个字符
for i in range(num):
u=ulist[i]#从list中取i值
print("{:^10}\t{:^10}\t{:^10}".format(u[0],u[1],u[2]))#因为list中只写入了3个,所以最多取三个
def main():
uinfo=[]
url='http://zuihaodaxue.com/zuihaodaxuepaiming2020.html'
html=getHTMLText(url)
fillUnivList(uinfo, html)#uinfo是为了替换占位的ulist,是一个列表类型
printUnivList(uinfo, 20)#给num赋予20个值,uinfo同上
main()
结果:

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









